Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 流水线恢复/append
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
接着我们要介绍第二种情况的流水线架设。也就是流水线恢复。也即下图蓝框部分。

关于这个方法:
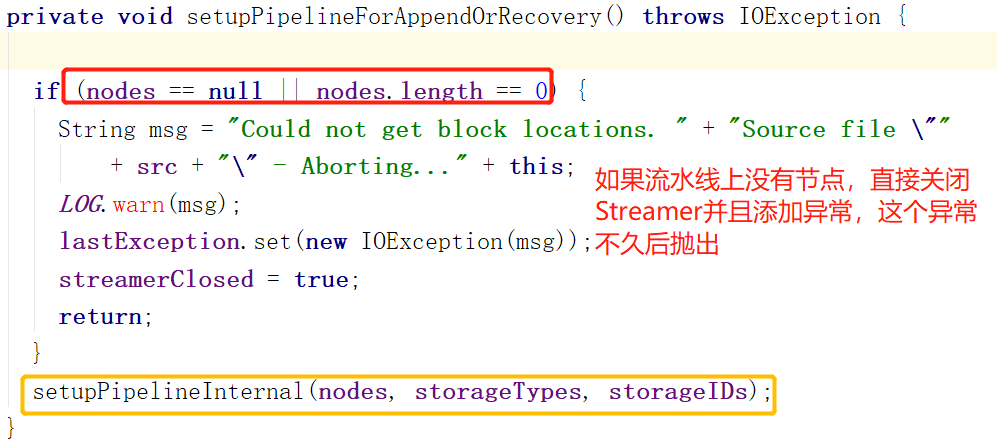
这个方法只是检查了一下流水线上是否有节点,而后直接调用橙色部分的方法。橙色部分的方法接收的参数是关于流水线上DataNode的内容

首先要做的是处理掉在流水线上但不能工作的DataNode。
要处理两类DataNode
1.正在重启的DataNode
2.无法正常工作的DataNode
最后要把无法工作的DataNode替换成能工作的DataNode。
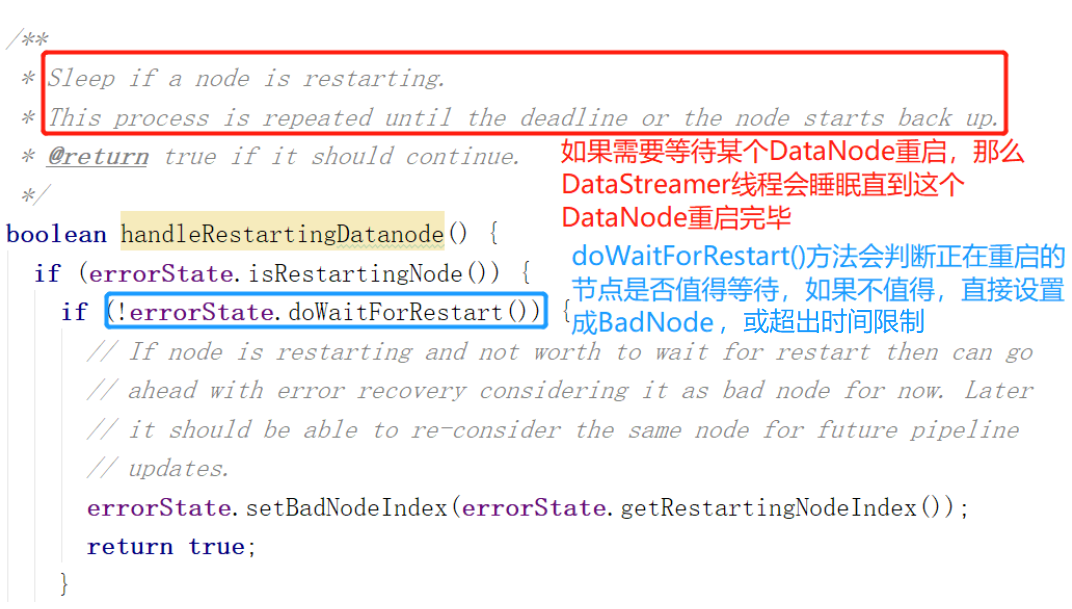
1.处理正在重启的DataNode:
判断一个DataNode是否值得等待重启:如果他是流水线上唯一节点或者是和客户端同一主机的节点,那么就值得等待。因为流水线只有一个节点,不等他等谁...只有他能工作。如果是本地节点,那么重启恢复到和客户端通信的速度会比较快。右图(左图方法的下半部分)只有一个sleep,怎么保证一直睡眠呢?上图红框上面有while循环。
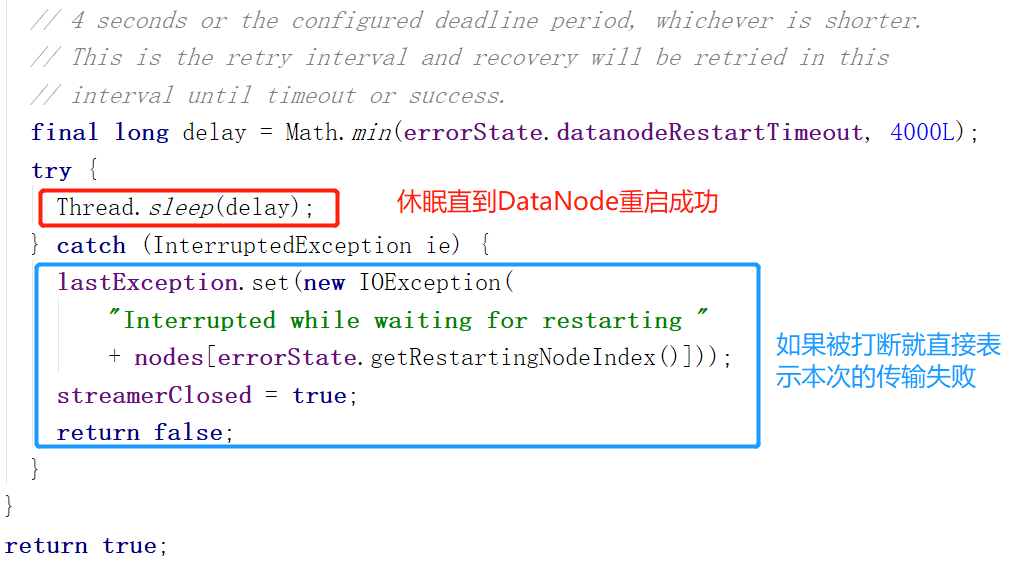
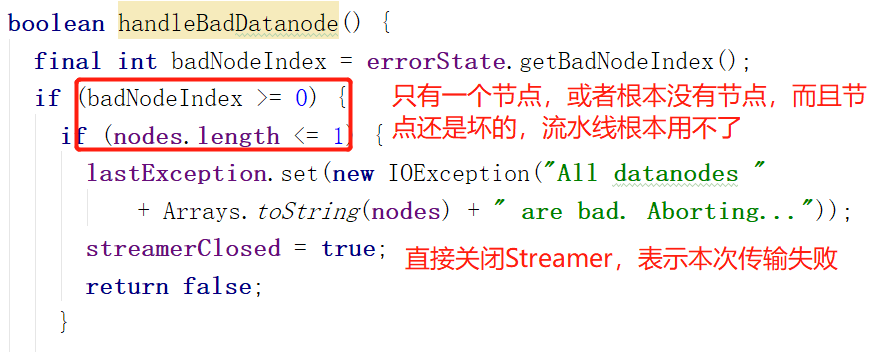
2.处理无法正常工作的节点BadNode:
其实做的最主要的事是移除坏(无法正常工作)的节点。
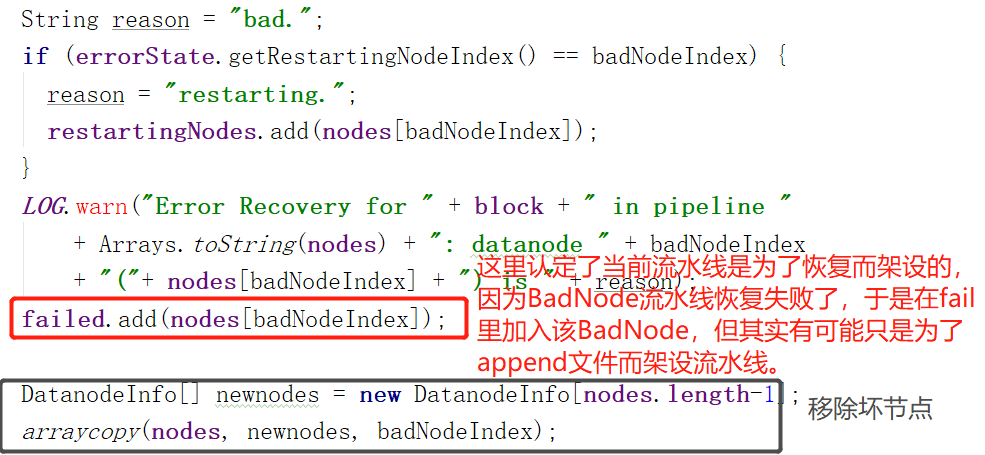
3.替换节点(实际是增加能工作的节点),其实关于新版的客户端设计我是有疑虑的。因为Append和Recovery设置流水线用的都是同一个方法,也就是![]()
结合这一步,就是说,即使没有BadNode,Append操作也需要在流水线上找多一个节点。如果找不到就报错。
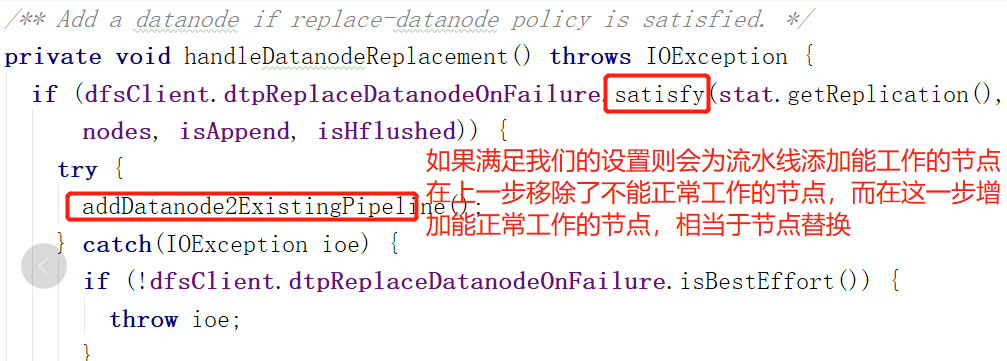
关于satisfy:
在dfs.client.block.write.replace-datanode-on-failure.policy不设置的情况下,如果是append文件,总是会满足这个函数
如果设置为NEVER,则返回false
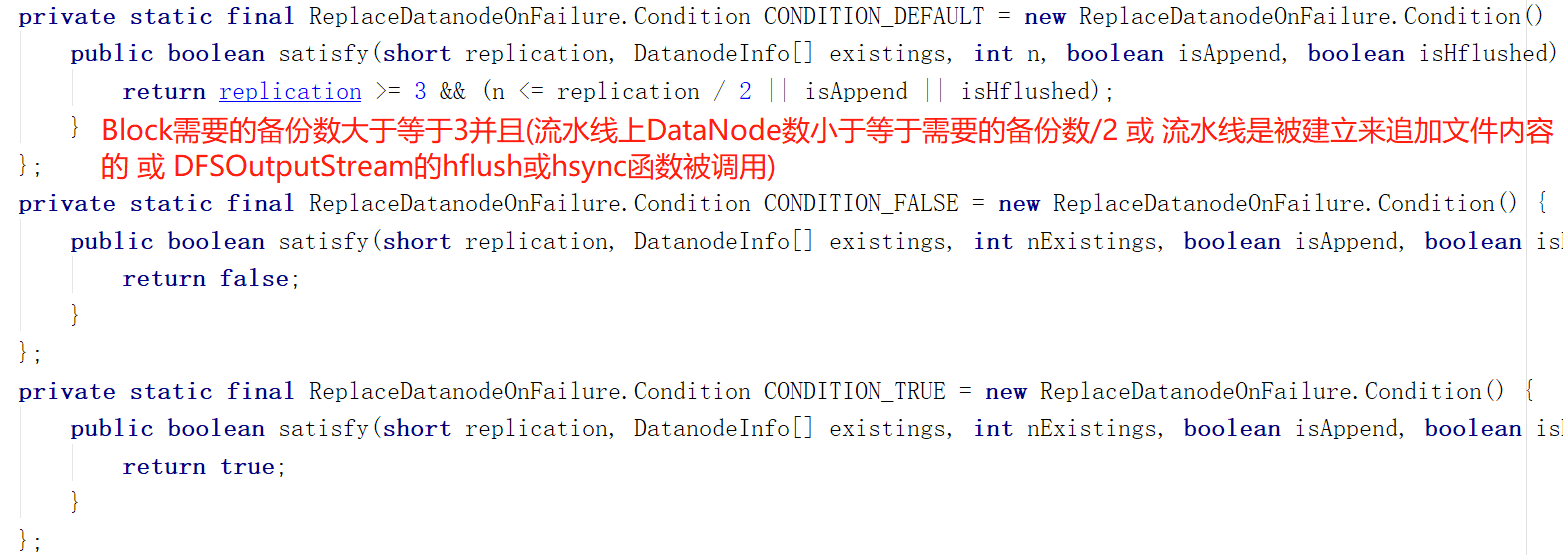
所以Append文件总是会为流水线寻找新节点,而且找不到还会报错...
看一下是怎么添加DataNode的,首先看一下官方注解,如果当前流水线失败正在恢复,需要添加一个新的DataNode,要知道,这个新的DataNode里可没有当前正在写入数据的Block的Replica,因为他是新加入的。所以需要找一个流水线上的DataNode,把Replica复制给新DataNode,但是还是要根据之前的错误发生在哪来决定复制还是不复制。
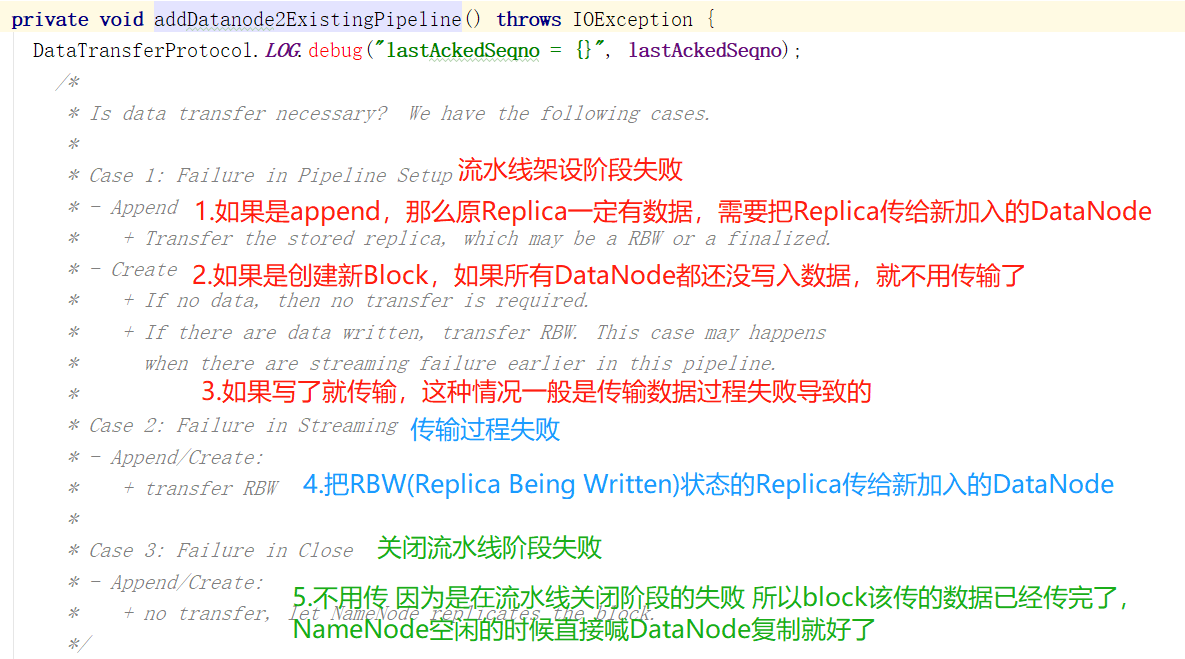
对于情况2:
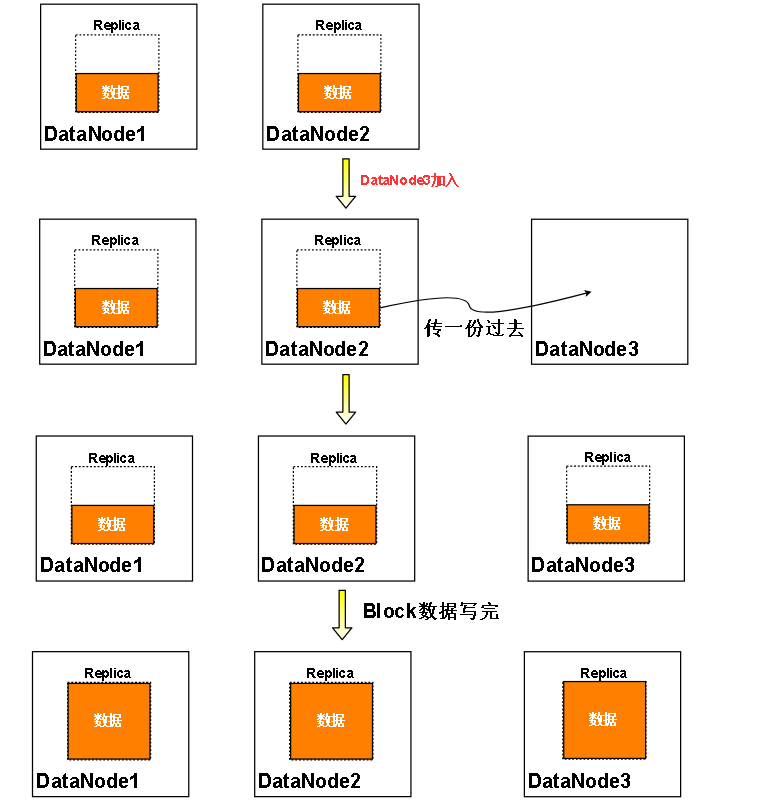
对于情况5
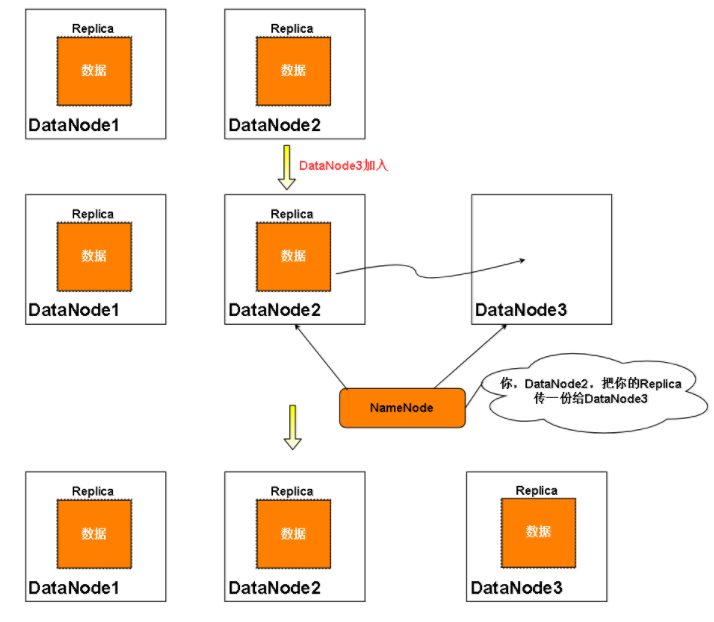
向下看:
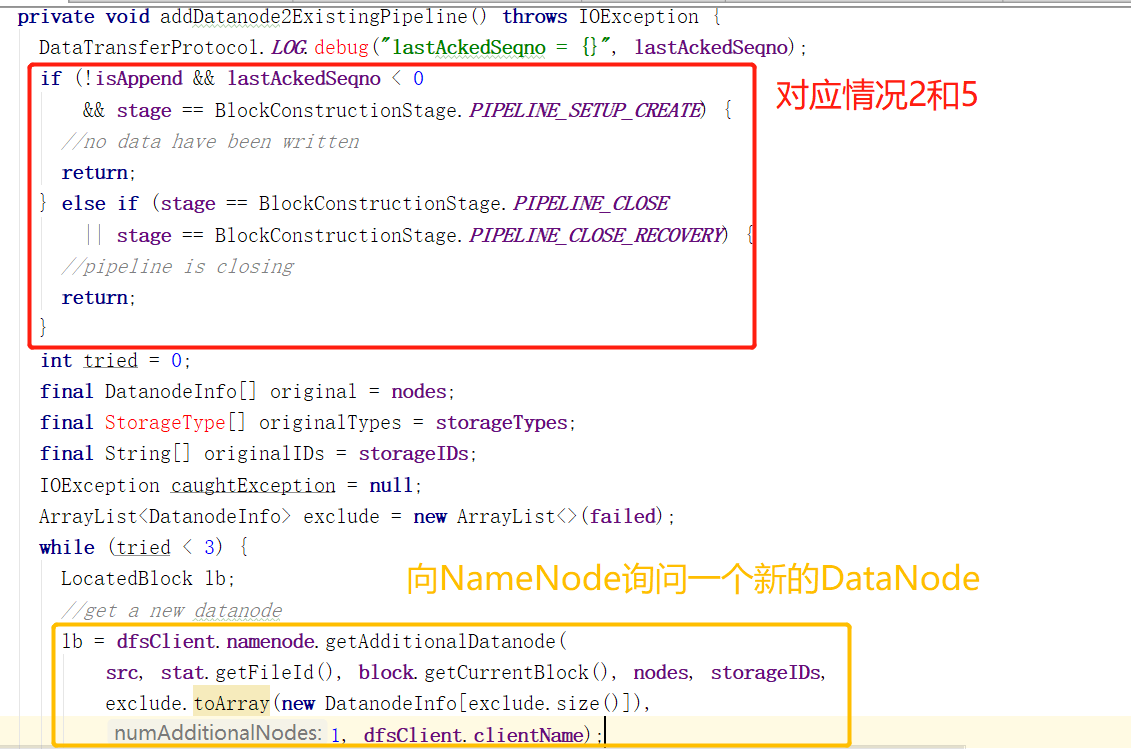
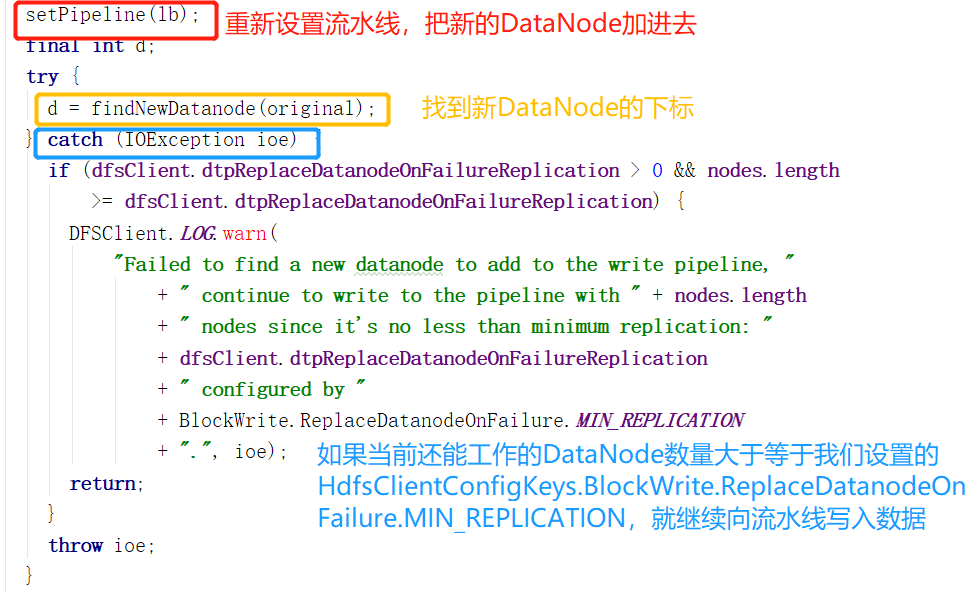
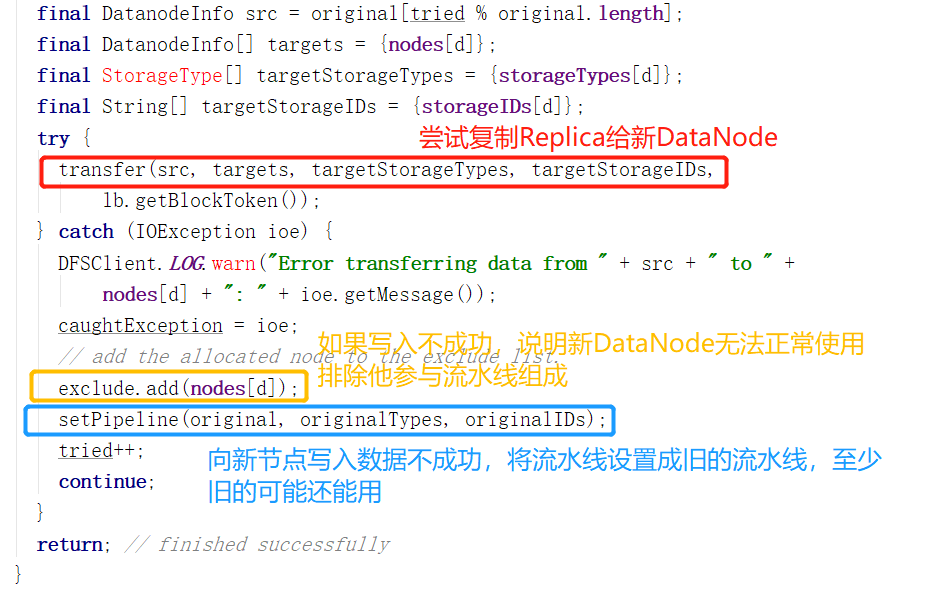
对不能正常工作的DataNode的处理完毕。接着之前的setupPipelineInternal讲下去。
updateBlockForPipeline会向NameNode申请更新Block的BGS和AccessToken,更新之后的信息返回,但不会在NameNode那边更新Block。
到了下面的updatePipeline才会告诉NameNode去更新,因为此时流水线架设成功。
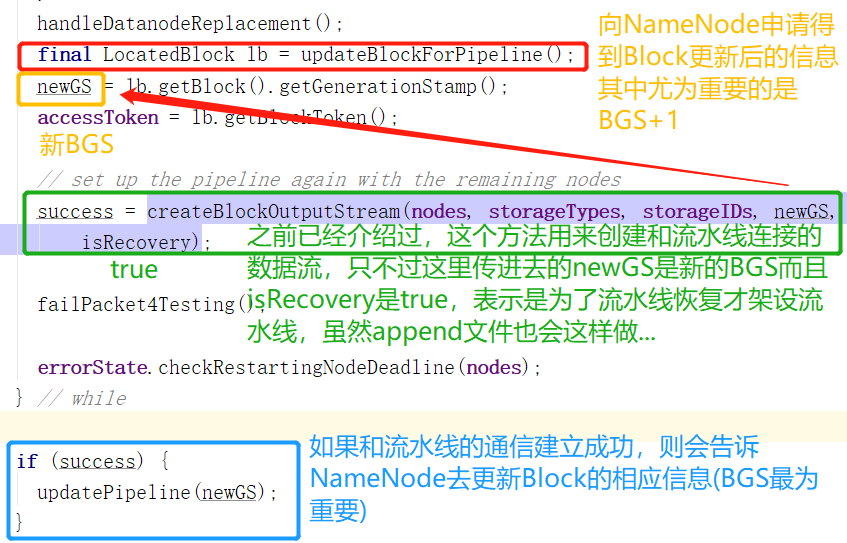
流水线的架设终于介绍完了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号