Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 创建块
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干

橙色框:新建块时的流水线架设
本身这个方法只是设置一个DataStreamer的一些成员变量而已,比如当前流水线的DataNode(s),各个DataNode的存储类型(一般是DISK,表示存在磁盘),Block在各个DataNode的存储ID

直接调用的是nextBlockOutput方法,这个方法返回的是一个LocatedBlock,包含了一个块的信息。
包括Block的备份存储位置,块的大小,块的BGS和BlockId。详细见右图

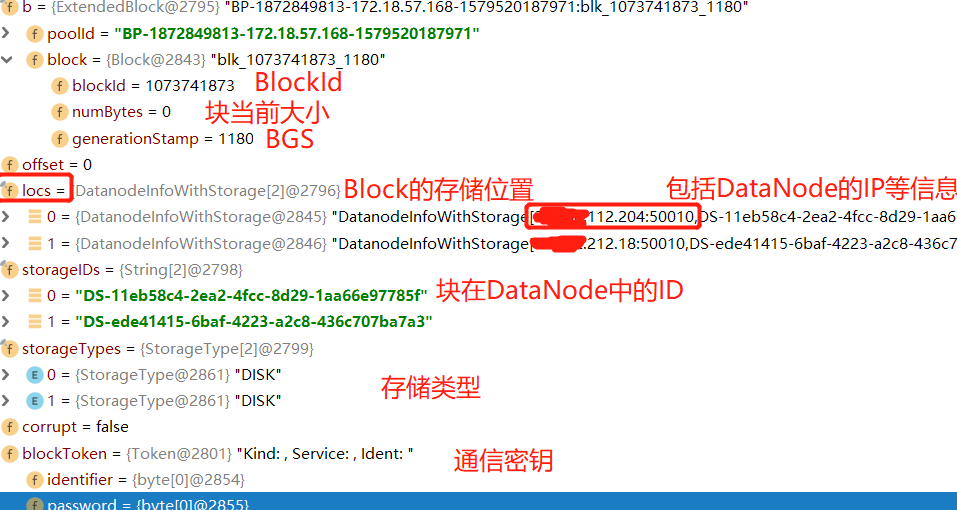
我们继续往下看,nextBlockOutput做了什么。其实官方注解已经说的很清楚了,连接流水线上第一个DataNode。
下面的nodes数组是从新块中得到的,是新块所在DataNode的信息。根据这个信息,调用createBlockOutputStream方法,创建和第一个节点的连接。并且通过一个boolean变量判断是否连接成功
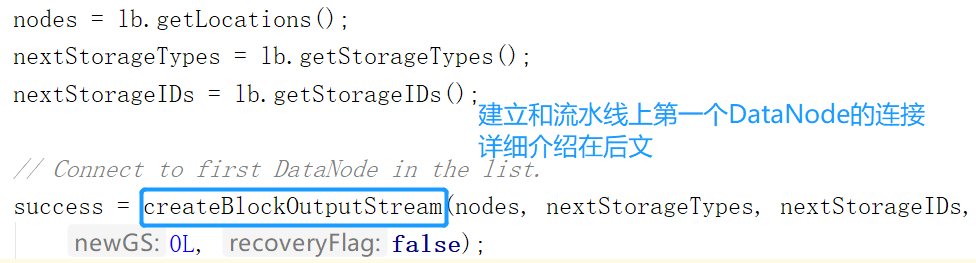
如果不成功会重新向NameNode申请Block并且尝试连接流水线第一个节点,直到超出规定的次数。
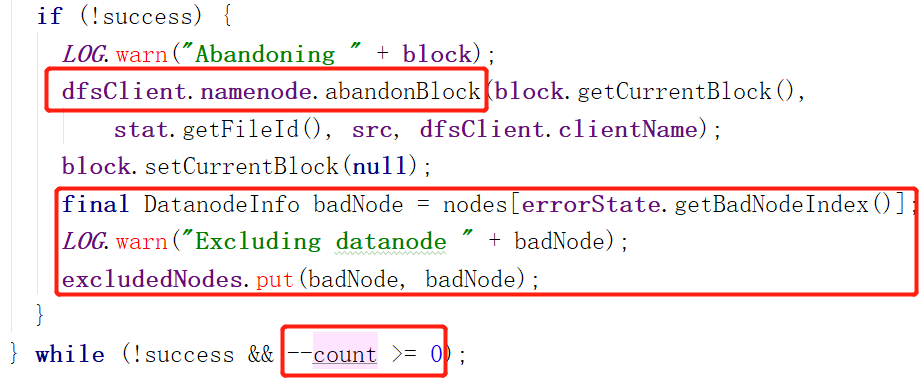
从下图我们得出三点信息:
1.如果创建连接不成功,则会通过远程调用通知NameNode,把这个Block丢弃掉。NameNode会把相应块的信息删除。
2.把工作不正常的节点添加到excludeNodes里,下次申请新块会告诉NameNode新块不备份到这个BadNode上。
3.超过规定次数(count,在block.write.retry里设置)后不再重试。
我们先留下一个问题,errorState的BadNodeIndex是从哪来的? (其实聪明的你已经猜到了,我们连接流水线第一个节点的时候如果失败就会产生BadNode)
上面简单提到了“创建和第一个节点的连接”下面就要详细谈谈这个过程。
建立流水线的方法在上文提到过。

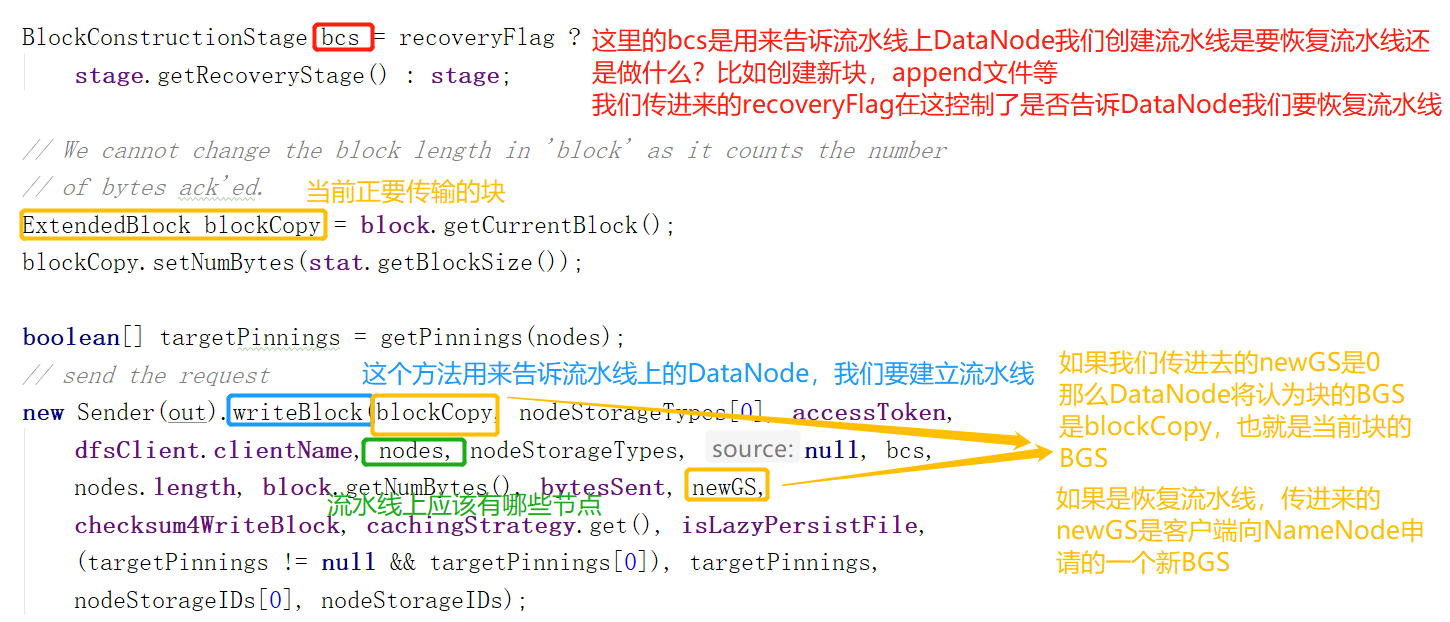
我们观察参数,发现传进去的是流水线DataNode的信息,还有的就是newGS,recoveryFlag。前者表示当前是否为恢复流水线,操作,因为恢复流水线需要新的BGS,如果是就把新的BGS做为newGS填进去,这里是创建新Block,显然不是。后者表示当前建立流水线是否是为了恢复流水线,这里显然不是。
下面讲解createBlockOutputStream方法
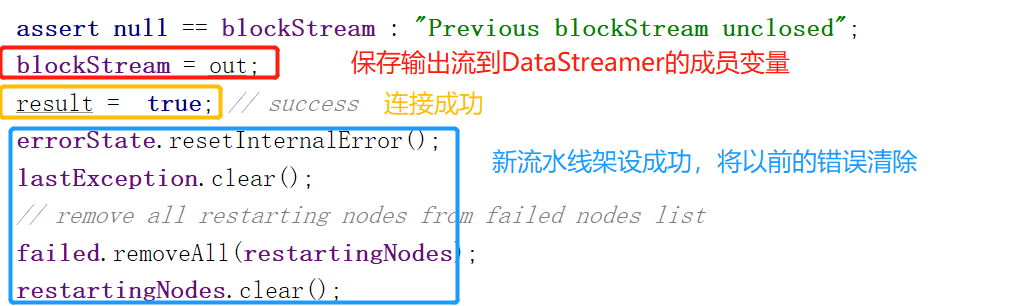
1.这个方法开始先做了3件重要的事,如下图。
如果流水线架设成功,那么我们就可以向下图中的输出流输送Packet,从接收流接收ACK。

2.接下来比较重要的是连接第一个DataNode。为了恢复流水线而重新架设流水线请看后文,为什么重新架设流水线会让客户端向NameNode申请一个新的BGS,请看Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)文末部分。
3.接着是接收DataNode的回复,根据回复,如果有正在重启的DataNode并且当前流水线无DataNode正在重启,将会抛出异常,并且把checkRestart设置为true,这个变量在catch块里用到。(左图)
右图接着左图之后。

关于上图的OOB,笔者还没有查证是什么含义。个人认为是用Out Of Band带外通信,把紧急的消息(DataNode重启)发送给客户端,若不对,恳请读者指教。
4.catch块
1.设置BadNode,把第一个不能正常连接的DataNode标记为BadNode,如果返回的消息不能认定谁是BadNode,那么BadNode就是你啦,第一个节点!
这里也解释了上文errorState的BadNodeIndex是怎么来的。

2.在3中如果checkRestart如果为true,那么catch会认为当前不正常工作的节点只是重启了而且,并且看看是否应该等待他重启(如果是本地节点就值得等待),值得的话就等待他重启(左图)
最后因为有错误,会关闭所有流(右图)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号