
Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
在HDFS中,有三种Recovery
1.Lease Recovery
2.Block Recovery
3.PipeLine Recovery
以下将 一 一 讲解。
一.Lease Recovery
首先很有比要介绍一下Lease(租约)
租约保证HDFS的一读多写机制,当一个客户端(Client)希望打开(Open)HDFS中的某个文件进行append或者truncate操作(追加内容或者减少内容)
他必须向NameNode申请Lease(租约),Lease相当于一把写锁,只有拥有Lease的客户端才能对文件进行写操作,其他客户端只能对文件进行读操作,而不能
进行写操作。当客户端关闭(Close)文件的时候,NameNode将释放相应的租约给其他客户端使用,相当于锁的释放。但是,有时候客户端拿到写锁之后可能宕机,无法关闭文件,从而导致租约无法归还。为了解决这个问题,NameNode中采取一种定时机制,客户端需要在规定的时间内,续租(Renew The Lease),才能继续拥有文件写的权力(联想一下交房租)。如果客户端没有在规定的时间内续租的话,NameNode有权把这个客户端占有的租约恢复成无人使用状态,以便给后来需要租约的客户端使用,恢复租约到无人使用状态的过程叫做(Lease Recovery)
先阐述一下,上述所说的规定时间。
有两种规定时间:1.软限制时间(一般是一分钟) 2.硬限制时间(一般是一小时)(强制下线时间)
Lease Recovery 在两种情况下发生
1.一个占有Lease的客户端在软限制时间内没有续租,并且有其他的客户端表示对他的Lease有兴趣。
2.一个占有Lease的客户端在硬限制时间内没有续租,在硬限制时间内没有其他客户端来过问这个Lease。NameNode将以其他客户端的名义要回这个Lease。
Lease Recovery过程:
假设没有按期续租的客户端为A
1.NameNode将以HDFS系统的名义占有租约,如此一来,如果又有客户端想对正在Lease Recovery的文件上下其手的话,就会失败,因为NameNode已经占有租约。(具体无法执行的操作包括:针对对应文件向NameNode请求一个新的GS,打开文件读写,关闭文件等等
2.NameNode检查自己这里文件的最后两个Block的状态
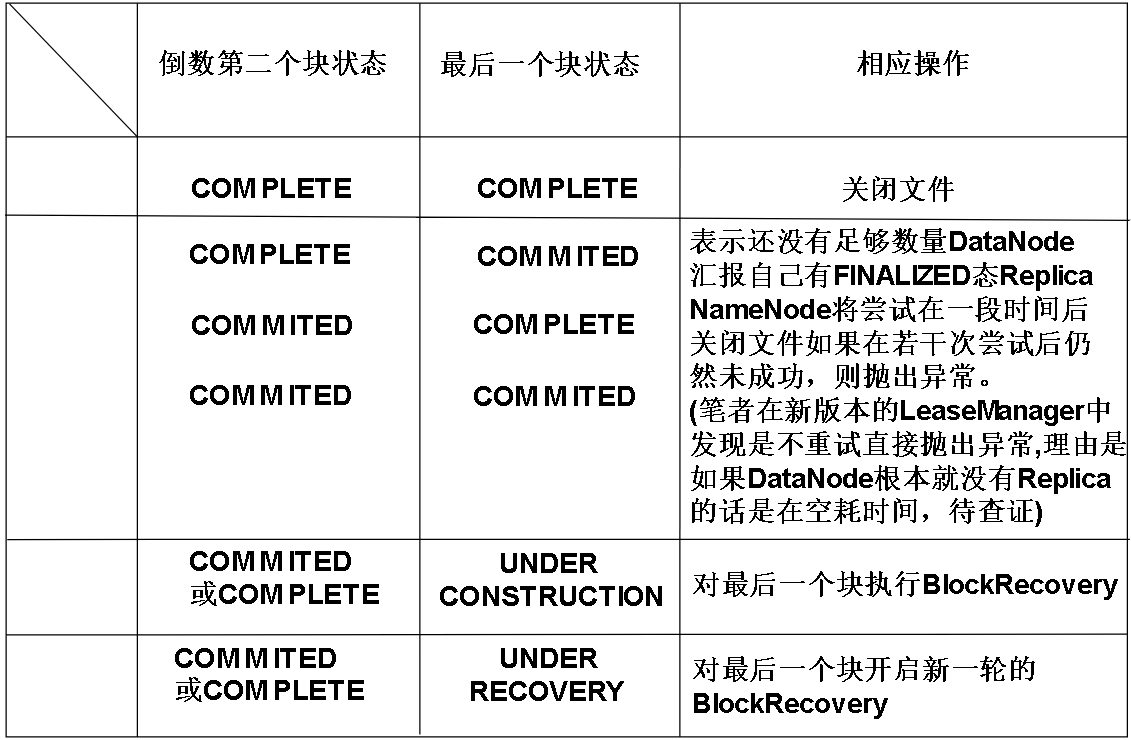
3.NameNode将自己这边的BLOCK从UNDER_CONSTRUCTION状态转换成UNDER_RECOVERY状态。
4.找到被A写入的DataNode,可能不只一个DataNode。如果在这些DataNode中找不到对应的Replica或者根本就不存在对应DataNode.则放弃Recovery
5.如果没有最小备份数个DataNode告知NameNode自己拥有FINALIZED态的Replica(比如我们设置的最小备份数是3,那么理应有3个DataNode告诉NameNode,自己已经有FINALIZED态的Replica了。也就是我们的最小备份数目的达成),将转到步骤6,否则结束。
6.NameNode随机选取一个DataNode为领袖DataNode
7.NameNode生成一个新GS,用来做为本次Recovery的标识符,称为Recovery Id,因为BGS是单调递增的,所以每次Recovery的GS都独一无二,如果Recovery成功这个新的GS将成为Block的BGS。NameNode随后将Replica所在的DataNode,被Recovery的Block的GS,BlockId等信息发送给领袖DataNode。
(GS/BGS,具体见Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS)
8.领袖DataNode收到上述信息后,将新GS和BlockId发送给上一步获取的各个DataNode,我们称之为从仆DataNode吧
9.从仆DataNode工作
1.检查自己是否真的如NameNode所说,存在合法的Replica,如果Replica的BGS和NameNode给出的BGS不一样,则抛出异常。
2.如果Replica合法,但是正在被其他Writer写入,那么DataNode将断打断这个Writer,并且等待Writer退出,在等待的过程中会把数据写回磁盘,保证数据量是DR(DR请见:Hadoop架构: 流水线(PipeLine)),如果Writer尝试重建流水线,将会失败,因为1中已经提到,NameNode以文件系统的名义占用了租约,其他客户端无法针对该文件获得新的GS。这个Writer可能是忘记续租的客户端。
3.关闭可能存在的Recovery,在本次Recovery之前可能有别的Recovery正在本文件进行,因为每个Recovery都有一个新的GS来作为独一无二的标记,所以如果这个原本就有的Recovery的Recovery Id比我们本次Recovery的Recovery Id旧的话,就把原有Recovery的GS设置成设置成本次Recovery的GS
10.领袖DataNode让所有仆从DataNode的把Replica的BGS都更新为第4步获得的新BGS,并且将所有的Replica都按情况裁剪成如下长度:
根据所有仆从DataNode的情况选取长度:
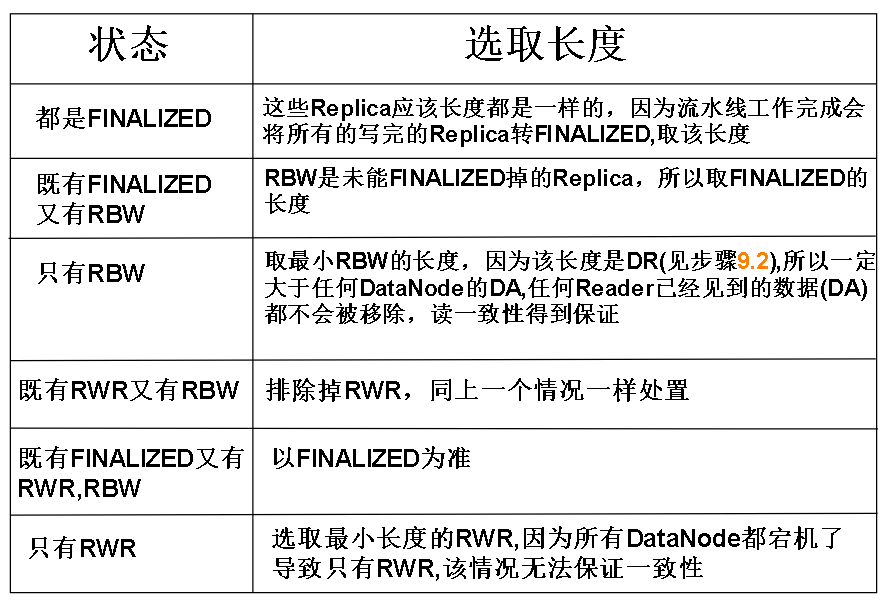
11.领袖DataNode根据仆从DataNode的工作情况决定下一步
1.如果全部仆从DataNode都完成了工作,没有异常,则直接向NameNode汇报自己完成了工作
2.如果部分完成了工作,部分没有完成,则进行重试,超过一定次数后,放弃Recovery
12.NameNode更新关于Block的信息(比如这个块存在哪些DataNode上,BGS是多少),并且释放租约
13.NameNode将关于块的变化(块长度变成了最小等等,BGS变化等)写入到日志
二,Block Recovery
其中6~11步其实就是Block Recovery , 把一些被编辑到一半的Block恢复成合理的状态。
三,PipeLine Recovery
我们知道,客户端和DataNode之间进行数据传输是依靠流水线的,客户端向流水线上发包(Packet),DataNode接收并处理,但是如果在流水线运转过程中,某个DataNode宕机了,怎么办呢?这时候就需要PipeLine Recovery机制来恢复我们的流水线,让流水线恢复到能正常工作的状态。
关于流水线,请参考 Hadoop架构: 流水线(PipeLine)
我们知道,流水线是由DataNode串联而成的,就像一条水管,数据(Packets)从一端流进去,依次经过流水线上的各个DataNode,当最后一个DataNode收到数据,将会发出ACK(Acknowledge)给前一个
DataNode,前一个DataNode收到ACK后又会向前一个DataNode发送ACK。回复(ACK)相反地从尾端流回执行写操作的客户端(Writer)。
那么,只要是流水线上一个DataNode宕机了,都会导致整个PipeLine的DataStream(数据流动)环节无法正常运转。就像自行车链条,一个关节坏了,整个链条就转不起来。
所以,我们需要PipeLine Recovery机制(流水线恢复),保证DataStream继续运作。
流水线恢复按阶段不同分为3种:
1.架设流水线阶段失败
2.流水线传输数据阶段失败
3.流水线关闭阶段失败
架设阶段失败:
分情况:
1.流水线是用来创建新的Block的:客户端放弃掉(Abandon)新建的Block,重新向NameNode申请一块Block并且将重新架构流水线。
2.流水线是用来对已有文件写入数据的:客户端重新架构流水线,并且把Block的BGS+1
传输数据阶段失败:
步骤:
1.客户端排除掉出错的DataNode(称之为BadNode),BadNode会通过断开与客户端的TCP连接的方式将自己隔离出流水线,并且尽可能地将已经确认(收到ACK)的数据写入磁盘,最后关闭文件。
2.客户端检测到流水线上发送回来的ACK不对数,少了某个DataNode,会停止发送Packet
3.客户端将重新架设流水线,并且根据 fs.client.block.write.replace-datanode-on-failure.policy/enable 的设置决定是否寻找新的节点代替BadNode,客户端向NameNode申请新的BGS,这个BGS将在重新架设流水线成功后,成为Replica和Block的BGS。这样BadNode的Rplica的BGS就和还健在的DataNode,以及NameNode那边Block的BGS相差1,如果以后BadNode重启,加入流水线,那么因为Replica的版本(BGS是Replica的版本标识)过老,而被要求删除(或许能够恢复,如果客户端也挂了)
4.客户端重新发送数据,从哪里开始发送呢?假如客户端最后收到ACK的数据Packet是P,那么重新从P后开始发送数据。
5.DataNode如果接收到4中发来的Packet时,发现自己已经有这部分数据了,就会简单的把这个Packet发给下游。
关闭阶段失败:
步骤:
1.客户端尝试新建流水线,用来告知DataNode应该把Replica给FINALIZE掉
2.DataNode等待客户端发送endBlock包,这个包是用来告诉DataNode,Block传输完成的,当DataNode收到这个包,将把Replica设置成FINALIZED。
3.DataNode在关闭网络连接前,会向客户端发送endBlock包的确认包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号