


KNN--算法举例
前言:
找了个时间来写一下knn的算法,发现了不少意外的惊喜,以前有些马马虎虎的东西今天居然理解了,并发现了几篇好博文可以和大家分享。
knn主要是利用数据特征与其他已知数据的远近程度来进行分类。
正文:
import matplotlib.pyplot as plt
import numpy as np
import operator
#已知分类的数据
x1 = np.array([3,2,1])
y1 = np.array([104,100,81])
x2 = np.array([101,99,98])
y2 = np.array([10,5,2])
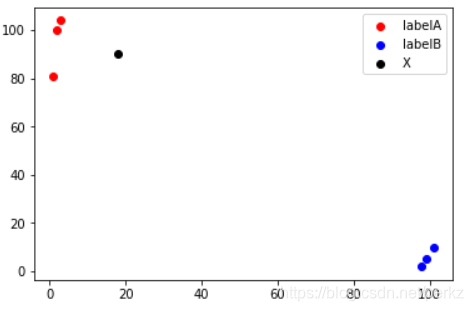
#用散点方式画出来,一个是红点一个是蓝点
scatter1 = plt.scatter(x1,y1,c='r')
scatter2 = plt.scatter(x2,y2,c='b')
#未知数据
x = np.array([18])
y = np.array([90])
scatter3 = plt.scatter(x,y,c='k')
#画图例
#传入数据和设置标签
plt.legend(handles=[scatter1,scatter2,scatter3],labels=['labelA','labelB','X'],loc='best')
plt.show()
画出的图像如下:
#已知分类数据
x_data = np.array([[3,104],
[2,100],
[1,81],
[101,10],
[99,5],
[81,2]])
y_data = np.array(['A','A','A','B','B','B'])
x_test = np.array([18,90])
#计算样本数量
#shape函数用来计算样本的行数和列数等数据
#0代表计算出它的行数
x_data_size = x_data.shape[0]
x_data_size
6
#复制x_test
#tile函数把左边复制给右边
#x_data_size代表行复制6次
#1代表列复制一次
np.tile(x_test,(x_data_size,1))
Out[9]:array([[ 15, -14],
[ 16, -10],
[ 17, 9],
[-83, 80],
[-81, 85],
[-63, 88]])
#计算差值的平方
sqDiffMat = diffMat**2
sqDiffMat
Out[10]:array([[ 225, 196],
[ 256, 100],
[ 289, 81],
[6889, 6400],
[6561, 7225],
[3969, 7744]], dtype=int32)
#求和
#这里解释一下,若sum函数中不加任何东西,则是对整个数组进行加法
#若axis的值为0,则表示列相加
#若axis的值为1,则表示行相加
sqDistances = sqDiffMat.sum(axis=1)
sqDistances
array([ 421, 356, 370, 13289, 13786, 11713], dtype=int32)
#开方
distances = sqDistances**0.5
distances
Out[12]:array([ 20.51828453, 18.86796226, 19.23538406, 115.27792503,
117.41379817, 108.2266141 ])
#从小到大排序
#argsort为排序函数
sortedDistances = distances.argsort()
sortedDistances
array([1, 2, 0, 5, 3, 4], dtype=int64)
classCount = {}
#设置k
#k的值代表离它最近的五个数据
k = 5
for i in range(k):
#获取标签
votelabel = y_data[sortedDistances[i]]
#统计标签数量
classCount[votelabel] = classCount.get(votelabel,0) + 1
classCount
Out[15]:{'A': 3, 'B': 2}
#根据operator.itemgetter(1)-第一个值对classCount排序,然后再取倒序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
sortedClassCount
[('A', 3), ('B', 2)]
#获取数量最多的标签
knnclass = sortedClassCount[0][0]
knnclass
'A'
分类完成!
总结:
写完这篇博文,最大的收获其实在于掌握了关于axis这个参数的运用,我的理解不足以将其完全阐述,可以去看下面这篇链接的博文,写的很详细很好!
地址如下:
https://blog.csdn.net/ksws0292756/article/details/80192926
另外我想再说一下有关shape函数,对于不同的类型有着不同的效果,对于矩阵来讲,它就会输出行与列等数据,对于数组等,则输出的是它的大小,具体实例可以百度搜索到。
这篇文章用到的公式为欧式距离,百度即可搜到,这个算法的缺点在于复杂度较高,当样本中某一类数据类型较多时,则分类结果会被占据多数的样本所主导。
