个人项目论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 学会一个项目的评估与开发,学会性能分析与改进模块,学会测试代码 |
github链接:https://github.com/LEIQIHAO/LEIQIHAO/tree/main/3122004868
一、P2P表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 32 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 32 |
| Development | 开发 | 435 | 461 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 50 |
| · Design Spec | · 生成设计文档 | 30 | 25 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 8 |
| · Design | · 具体设计 | 30 | 35 |
| · Coding | · 具体编码 | 200 | 240 |
| · Code Review | 代码复审 | 10 | 8 |
| · Test | 测试(自我测试,修改代码,提交修改) | 75 | 80 |
| Reporting | 报告 | 60 | 68 |
| · Test Repor | 测试报告 | 20 | 30 |
| · Size Measurement | 计算工作量 | 10 | 12 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 26 |
| 合计 | 525 | 561 |
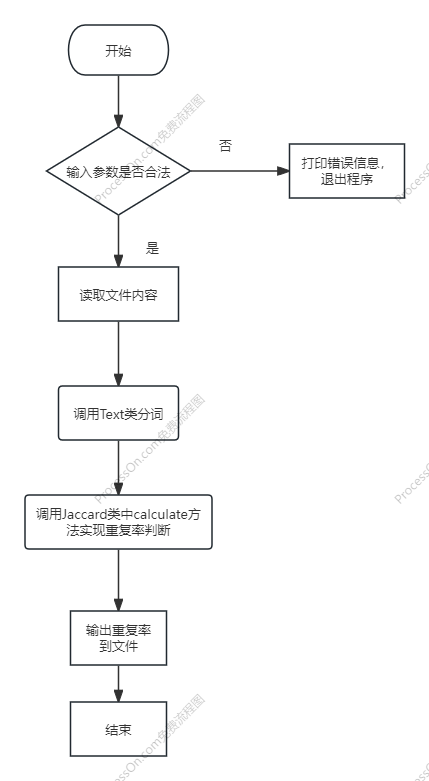
二、设计与实现过程
- 项目主类中定义了validate方法,用于检测传入参数是否是正确的路径,在其中使用java内置函数isBlank和getCanonicalPath分别判断字符串是否为空和该路径是否可以读取到文件
- 同时在主类中使用内置的FileUtil函数进行文件的读取
- 同时定义了两个工具类,分别是Text类用IK分词器进行分词和Jaccard类使用Jaccard算法进行重复率计算
- 最后将计算得到的重复率在主函数通过FileUtil写入对应的文件中
- 算法的关键和独到之处:使用性能较好和分词效果领先的IK分词器使用HashSet来对文本进行分词,保证了代码的可靠性,Juccard算法是指两个集合A和B交集元素的个数在A、B并集中所占的比例,Jaccard系数值越大,样本相似度越高。这个算法相对比较简单,所以性能很好,同时准确率在所有算法中也非常准确。
三、性能改进
我在改进计算模块性能上所花费的时间在20分钟,主要是通过把公共的部分比如说分词、判断参数是否合法这些公共的部分分离出来,避免重复消耗内存和重复计算
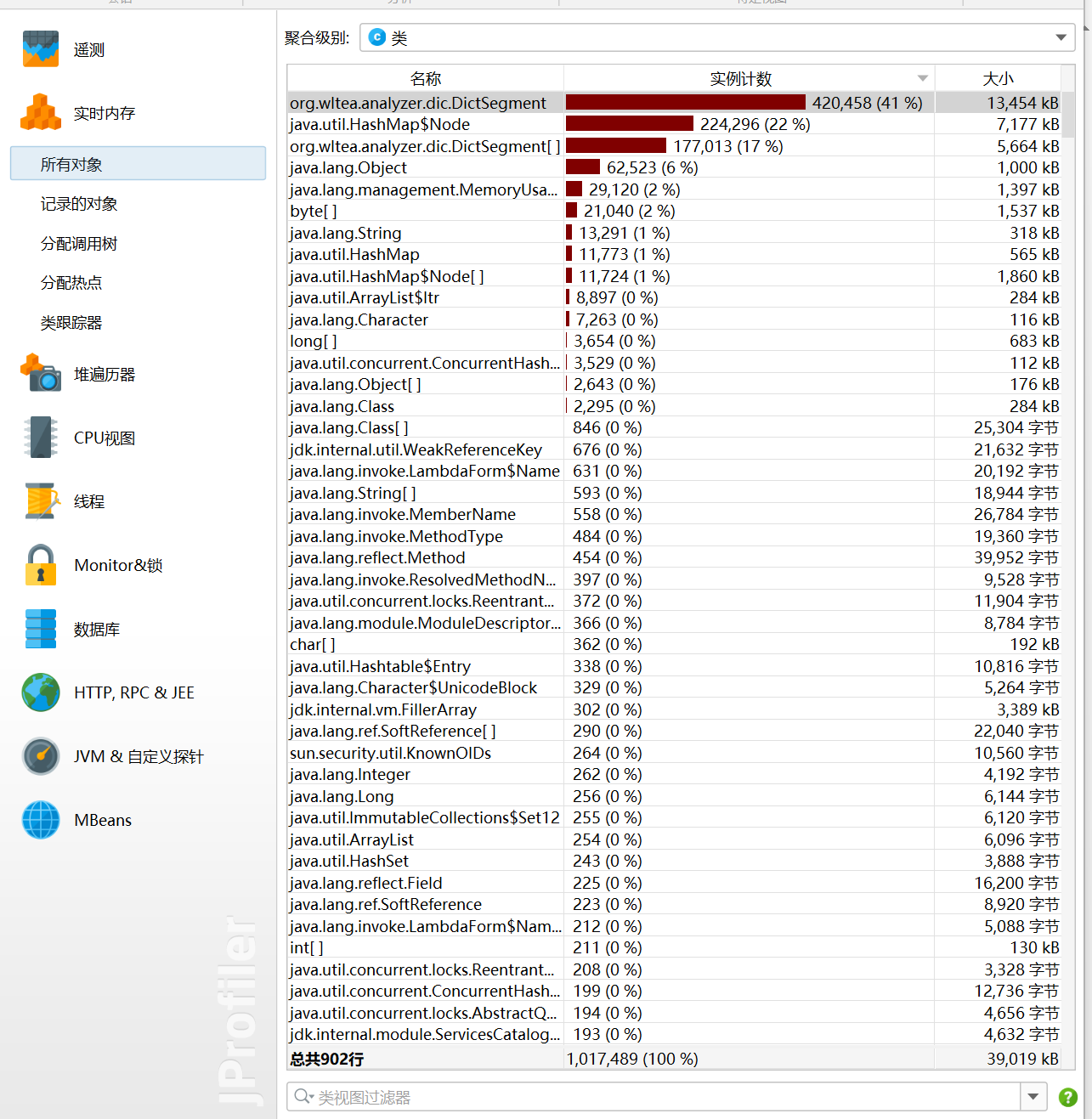
消耗最大的函数是org.wltea.analyzer.dic.DictSegment
四、单元测试展示
部分单元测试代码
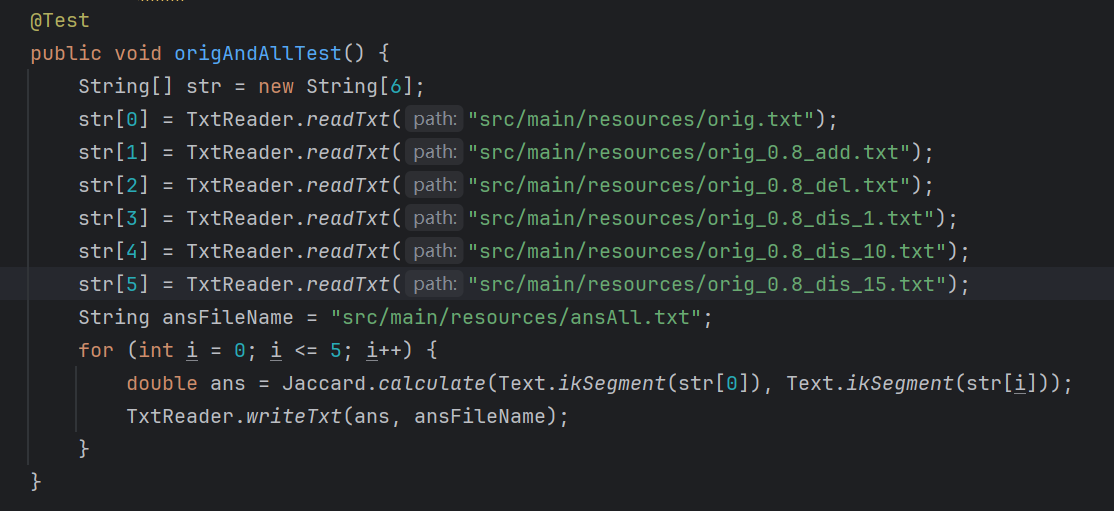
测试的函数主要通过模拟路径的输入,读取文件,分词并计算重复率,最后将结果输出到文件中
覆盖率截图

五、异常捕获
判断传入参数数量是否足够
if (args.length < 3) {
System.err.println("传入参数错误,请检查你的输入");
return false;
}

判断路径能否正常读取文件
// 检查字符串是否为合法,是否为null或者为空
private static boolean isPathString(String str) {
return StringUtils.isBlank(str) || isPath(str);
}
private static boolean isPath(String path) {
File file = new File(path);
try {
// 尝试获取绝对路径,检查路径格式是否正确
String fileStr = file.getCanonicalPath();
return false;
} catch (Exception e) {
return true;
}
}

判断分词器能否正确分词
try {
Lexeme lexeme;
// 判断是否还有词语
while ((lexeme = ik.next()) != null) {
words.add(lexeme.getLexemeText());
}
} catch (IOException e) {
// 分词错误
System.err.println("分词出错:" + e.getMessage());
}


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 我干了两个月的大项目,开源了!
· 推荐一款非常好用的在线 SSH 管理工具
· 千万级的大表,如何做性能调优?
· 聊一聊 操作系统蓝屏 c0000102 的故障分析
· .NET周刊【1月第1期 2025-01-05】