
Oracle笔记16——Oracle序列、索引与同义词
一、
索引(INDEX):单列索引、复合索引,用于优化查询效率
自动创建:当创建PRIMARY KEY或UNIQUE 约束时,默认创建索引
手动创建:CREATE INDEX idx_tableName_columName ON 表名(列名1[,列名2...])
ROWNUM 伪列
虚拟存在的,每查询一次数据,永远从1开始,只能使用 <或者 <=比较
SELECT ROWNUM,e.* FROM emp e;
二、ROWID 伪列
真实存在在物理磁盘中,唯一标识每一行数据的值
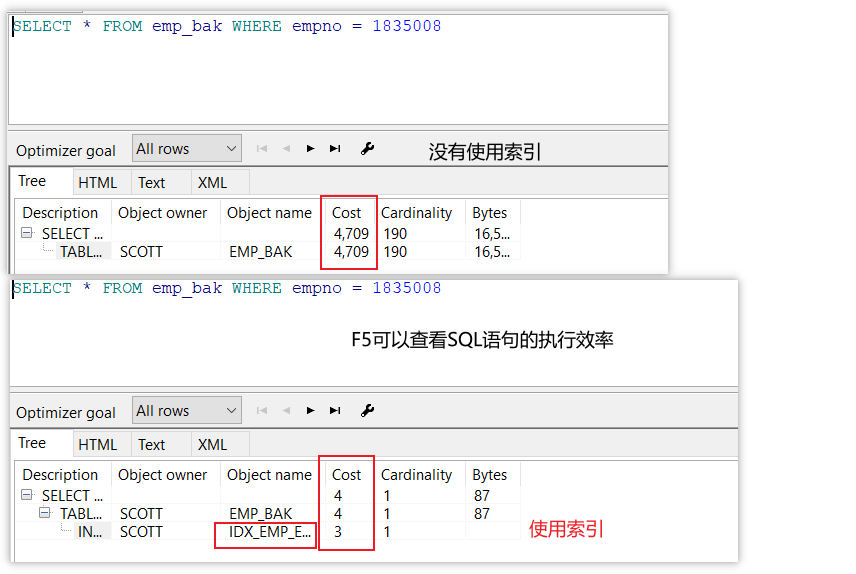
---------------------- --创建索引 ---------------------- --单列索引 1.在emp表的ename字段上创建索引. CREATE INDEX idx_emp_ename ON emp(ename); --复合索引(组合索引) 2.在emp表的deptno和job的组合上创建索引 CREATE INDEX idx_emp_deptno_job ON emp(deptno,job); --测试索引 1.创建表emp_bak表,表结构同emp(即复制emp的表结构) CREATE TABLE emp_bak AS SELECT * FROM emp; 2.往emp_bak表中插入大批量数据(单位:百万) INSERT INTO emp_bak SELECT * FROM emp_bak;--多次执行,1835008条数据 3.将empno设置为唯一值 --将empno的长度修改为7 ALTER TABLE emp_bak MODIFY (empno NUMBER(7));--1.将empno的长度修改为7 UPDATE emp_bak SET empno = ROWNUM;--2.使用ROWNUM将empno修改为唯一值 UPDATE emp_bak SET empno = seq_emp.nextval;--2.也可以使用nextval将empno修改为唯一值 SELECT * FROM emp_bak; 4.查询empno为1835008的员工信息 SELECT * FROM emp_bak WHERE empno = 1835008;--无索引 大约查询时间为0.20s CREATE INDEX idx_emp_empno ON emp_bak(empno);--创建索引 SELECT * FROM emp_bak WHERE empno = 1835008;--有索引 大约查询时间为0.01s
三、分析有无索引的区别
----------分析有无索引的区别------------start --1.无索引 DROP INDEX idx_emp_empno; SELECT ROWID,emp_bak.* FROM emp_bak WHERE empno = 1835008;--0.2 干巴巴的查询了4700多行,才找到该数据 --2.有索引:给empno创建了一个索引,为了维护 1835008 -> AAAR7fAAEAAACwyACq 这段奇妙的关系,需要花代价 ① 1835008 -> AAATBlAAEAAAOMfABa SELECT ROWID,empno FROM emp_bak WHERE empno = 1835008;--AAAR7fAAEAAACwyACq AAAR7fAAEAAAACzAAA 1 AAAR7fAAEAAAACzAAB 2 AAAR7fAAEAAAACzAAC 3 AAAR7fAAEAAAACzAAD 4 AAAR7fAAEAAAACzAAE 5 AAAR7fAAEAAAACzAAF 6 AAAR7fAAEAAAACzAAG 7 ..................... AAAR7fAAEAAACwyACq 1835008 ②AAATBlAAEAAAOMfABa -> 1835008对应的数据 SELECT ROWID,emp_bak.* FROM emp_bak WHERE ROWID = 'AAAR7fAAEAAACwyACq';--0.01 查询了1行 ----------分析有无索引的区别------------end --------------- --删除索引 ----------------- DROP INDEX idx_emp_empno;
四、数据字典表
SELECT * FROM user_tables;--查询当前用户下所有的表格 SELECT * FROM user_constraints;--查看当前用户下所有的约束 SELECT * FROM user_cons_columns;--查看约束关联的列信息 SELECT * FROM user_indexes;--查询当前用户下所有的索引 SELECT * FROM user_ind_columns;--查看索引关联的列信息
五、
序列(sequence):按照一定的规则自动增长或自动减少,通常用于生成主键值
--简单创建 CREATE SEQUENCE seq_emp; --复杂创建 CREATE SEQUENCE seq_emp MINVALUE 1 --最小值 MAXVALUE 9999999999999999999999999999 --最大值 maxvalue n| nomaxvalue 没有最大值 START WITH 1 --开始值 INCREMENT BY 1 --原增的值 NOCYCLE --默认不循环,cycle | nocycle CACHE 20; --默认缓存20 CREATE SEQUENCE seq_dept MINVALUE 10 MAXVALUE 90 START WITH 10 INCREMENT BY 10 NOCYCLE NOCACHE; --两个属性 -- nextval : 获取序列的下一个值 -- currval :获取同一个会话中,序列的当前的值,且取值之前必须先执行nextval取下一个值 SELECT seq_emp.nextval FROM dual; SELECT seq_emp.currval FROM dual; --使用序列:新增数据时,自动生成主键值 INSERT INTO emp(empno, ename, job) VALUES(seq_emp.nextval, '张三', 'SALSMAN'); SELECT * FROM emp; --修改序列:除了START WITH以外的属性均可以修改 1.将seq_dept的最大值修改为200 ALTER SEQUENCE seq_dept MAXVALUE 200 --删除序列 DROP SEQUENCE seq_emp;
六、
创建同义词(SYSNONYM):给对象取别名
创建同义词的语法如下:
CREATE [PUBLIC] SYNONYM 同义词 FOR 表名;
1.为表emp创建私有同义词e CREATE SYNONYM e FOR emp; SELECT * FROM e;--这时通过同义词e便可以访问表emp了 --其它用户可以通过以下方式访问scott的e SELECT * FROM scott.e; 2.为dept表创建共有同义词d CREATE PUBLIC SYNONYM d FOR dept; --其它用户可以直接访问e SELECT * FROM d; 3.删除同义词 DROP SYNONYM e; DROP PUBLIC SYNONYM d;

