数据流分析(data flow analysis)简介(一)
注意
这条博客目前还非常不完善,可能存在一些错误,待后续完善
动机
编译时的优化。
编译器可以只根据本地信息进行一些优化。例如,考虑以下代码。
x = a + b; x = 5 * 2;
优化器很容易识到,x的第一个赋值是一个 "无用的 "赋值,因为为x计算的值从未被使用(因此第一个语句可以从程序中删除)表达式5*2可以在编译时计算出来,将第二个赋值语句简化为x=10。
然而,有些优化需要更多的 "全局 "信息。例如,考虑下面的代码。
a = 1; b = 2; c = 3; if(...)x = a + 5 else x = b + 4 c = x + 1
在这个例子中,对c的初始赋值(在第3行)是无用的,表达式x + 1可以简化为7,但编译器如何发现这些事实就不太明显了,因为不能只看一两个连续的语句来发现。需要进行更全面的分析,以便编译器知道在程序的每个point上哪些变量可以保证有常量值,以及哪些变量在被重新定义之前会被使用。
为了发现这些类型的属性,我们使用数据流分析。数据流分析通常是在程序的控制流图(CFG)上进行的;目标是将每个程序组件(CFG的每个节点),与保证在所有可能的执行中在该点上保持的信息起来。(即获取在任何可能的执行情况中,都确定的信息,如上面的代码中 c=7 是确定的)
理解
概念
DFA是一种静态分析手段。数据流分析指的是一组,用来获取有关数据如何沿着程序执行路径流动的相关信息,的技术.
Data-flow analysis is a technique for gathering information about the possible set of values calculated at various points in a computer program. 通俗的理解为,DFA 可以计算出程序每个point(如基本块出入口)对应的一组值(状态),而这组值包含了一些数据相关的信息。通过这些信息,可以解决一些问题:比如编译优化问题,比如检测是否存在use after free
分类
根据对程序路径的分析精度分类:
- 流不敏感分析(flow insensitive):不考虑语句的先后顺序,按照程序语句的物理位置从上往下顺序分析每一语句,忽略程序中存在的分支
- 流敏感分析(flow sensitive):考虑程序语句可能的执行顺序,通常需要利用程序的控制流图(CFG)
- 路径敏感分析(path sensitive):不仅考虑语句的先后顺序,还对程序执行路径条件加以判断,以确定分析使用的语句序列是否对应着一条可实际运行的程序执行路径
根据分析程序路径的深度分类:
- 过程内分析(intraprocedure analysis):只针对程序中函数内的代码
- 过程间分析(inter-procedure analysis):考虑函数之间的数据流,即需要跟踪分析目标数据在函数之间的传递过程
- 上下文不敏感分析(context-insensitive):将每个调用或返回看做一个 “goto” 操作,忽略调用位置和函数参数取值等函数调用的相关信息
- 上下文敏感分析(context-sensitive):对不同调用位置调用的同一函数加以区分
前向分析和后向分析:
根据节点状态的含义不同,可以分为前向数据流分析和后向数据流分析。
数据流分析方法
前向数据流分析:在前向流分析中,一个块的退出状态是该块进入状态的一个函数,这个函数是块中的语句效果的组成。一个块的进入状态是其前辈的退出状态的函数。这就产生了一组数据流方程。
对程序进行数据流分析的一个简单方法是为控制流图的每个节点设置数据流方程,并通过反复计算每个节点本地输入的输出来解决这些问题(计算方法依赖人为设定的规则),直到整个系统稳定下来(状态不再改变),即达到一个fixpoint。这种一般的方法,也被称为Kildall方法.
对于不同的问题(比如动机中的编译优化问题,以及其他很多问题呢,比如检测是否存在use after free),设置不同的状态表示(如基本块出入口变量的赋值情况)、状态转换规则,最终获取相关问题的信息,从而解决问题。
利用数据流分析挖掘漏洞
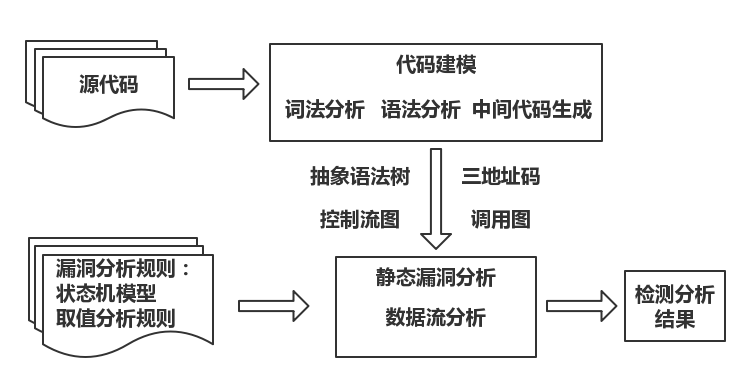
实际问题举例
如检测变量赋值,编译优化的问题,设置初始状态为 变量赋值方程 ,定义状态变化的规则。然后沿着CFG分析,根据块改变状态,最后系统稳定(状态不再改变)后,可以得到信息。比如确定变量是否是常量(x=5),还是由哪些变量赋值(x=a+1)。参考前面提到的动机
如检查是否存在指针use after free的问题
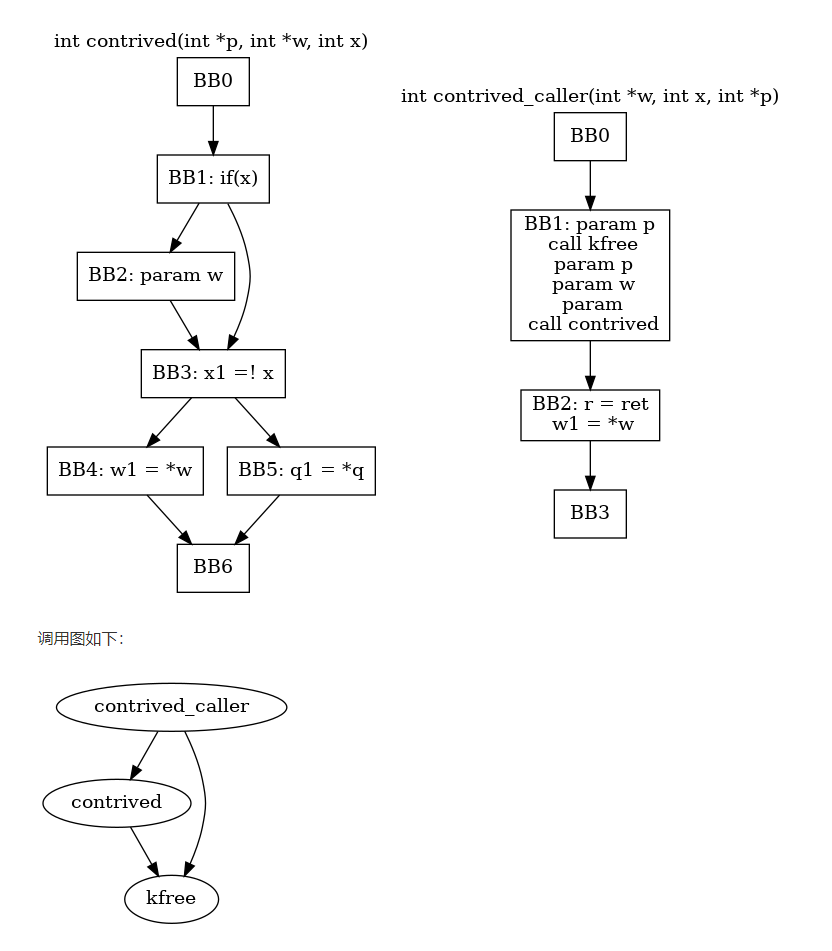
int contrived(int *p, int *w, int x) { int *q; if (x) { kfree(w); // w free q = p; } [...] if (!x) return *w; return *q; // p use after free } int contrived_caller(int *w, int x, int *p) { kfree(p); // p free [...] int r = contrived(p, w, x); [...] return *w; // w use after free }
下面是用于检测指针变量错误使用的检测规则:
v 被分配空间 ==> v.start v.start: {kfree(v)} ==> v.free v.free: {*v} ==> v.useAfterFree v.free: {kfree(v)} ==> v.doubleFree
分析过程从函数 contrived_call 的入口点开始,对于过程内代码的分析,使用深度优先遍历控制流图的方法,并使用基本块摘要进行辅助,而对于过程间的分析,选择在遇到函数调用时直接分析被调用函数内代码的方式,并使用函数摘要。
函数 contrived 中的路径有两条:
- BB0->BB1->BB2->BB3->BB5->BB6:在进行到 BB5 时,BB5 的前置条件为 p.free, q.free 和 w.free,此时语句
q1 = *q将触发 use-after-free 规则并设置 q.useAfterFree 状态。然后返回到函数 contrived_call 的 BB2,其前置条件为 p.useAfterFree, w.free,此时语句w1 = *w设置 w.useAfterFree。 - BB0->BB1->BB3->BB4->BB6:该路径是安全的。
即为三个指针p,q,w设置对应 状态 ,然后根据检测规则改变状态。当系统稳定,根据指针对应状态是否是useAfterFree,可以确定是否存在use after free问题。
参考
博客:
https://www.bookstack.cn/read/CTF-All-In-One/doc-5.4_dataflow_analysis.md
https://chhzh123.github.io/blogs/2019-02-15-spa-ufmg/#%E5%8F%82%E8%80%83%E6%96%87%E7%8C%AE-1
https://blog.csdn.net/z2664836046/article/details/88742210
wiki:
https://en.wikipedia.org/wiki/Data-flow_analysis
大学的课程:
https://pages.cs.wisc.edu/~horwitz/CS704-NOTES/2.DATAFLOW.html
https://groups.seas.harvard.edu/courses/cs252/2011sp/slides/Lec02-Dataflow.pdf
http://www.cs.columbia.edu/~suman/secure_sw_devel/Basic_Program_Analysis_DF.pdf
https://suif.stanford.edu/~courses/cs243/lectures/l2.pdf
论文:
Gary A. Kildall. 1973. A unified approach to global program optimization. In Proceedings of the 1st annual ACM SIGACT-SIGPLAN symposium on Principles of programming languages (POPL '73). Association for Computing Machinery, New York, NY, USA, 194–206. DOI:https://doi.org/10.1145/512927.512945
Markus Mohnen: A Graph-Free Approach to Data-Flow Analysis. CC 2002: 46-61

 浙公网安备 33010602011771号
浙公网安备 33010602011771号