
Apache Druid探究
1、简介
Apache Druid是针对时间序列数据提供的低延时数据写入以及快速交互式查询的分布式OLAP数据库。其两大关键点是:首先,Druid主要针对时间序列数据提供低延时数据写入和快速聚合查询;其次,Druid是一款分布式OLAP引擎。
2、主要特性
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。分析和存储系统,提供极具成本效益并且永远在线的实时数据摄取和任意数据处理。
为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描有必要的元素被优化。Aggregate和 filter没有坐等结果。
高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
3.、Druid使用场景,优缺点
应用场景:Druid应用最多的如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid是一个很好的技术方案选择。
Druid 常见应用的领域:
- 网页点击流分析
- 网络流量分析
- 监控系统、APM
- 数据运营和营销
- BI分析/OLAP
什么时候需要使用Druid
如果你的case满足下面一些特征那么Druid应该是一个好的选择
a)具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
b)需要一个高可用、高容错、高性能数据库时。
c)插入数据的频次非常高,但是修改非常少
d)你的意愿是希望查询延迟在100ms到几秒之间
e)你的数据有时间的属性(Druid包含一些特殊的设计和优化对于时间序列)
f)你可能有不止一个表,而且每个查询仅命中一些大的分布式的表.查询可能也会命中不止一个小的lookup表.(就像储存在内存里的一个小字典,可以不用的)
g)你需要在一些高基数的列上面(比如URLS,user IDs)做一些快速的计算和排序
h)你需要从Kafka,HDFS,flat files或者对象存储比如Amszon S3上加载数据
下面一些情况你可能不太适合用Druid
a)你需要对已经存在的记录利用主键进行低延迟的更新操作.Druid支持流式插入,但是不是更新(一般用后台的批处理任务来进行更新)
b)你正在构建一个线下的报表系统而且对查询延迟不是非常在意
c)你想做一些大的表的关联(比如连接大的事实表和另外一个大的事实表).
4、 数据存储
Realtime Node为LSM-Tree架构,与Hbase实现不同,Druid未提供WAL功能,牺牲数据可靠性,换写入速度。
实时数据到达Realtime Node后,被直接加载到堆缓冲区(Hbase memtable -> RB-Tree),当堆缓冲区大小达到阈值,数据被冲洗到磁盘,形成一个Segment(SSTable),同时Realtime Node立即将新生成的Segment加载到内存非堆区。堆区与非堆区都可以被Broker Node查询。
同时,Realtime Node周期性扫描磁盘Segment,将同一时间段生成的所有Segment合并为一个大的Segment。这个过程叫Segment Merge(相当于hbase中的compaction)。合并完的Segment被Realtime Node上传到DeepStorage,随后Coordinator Node通知一个Historical Node去Deepstorage将新生成的Segment下载到本地,并加载到内存(尽可能使用内存,不足时LRU淘汰),成功加载后,Historical Node通知Coordinator Node,声明其接管这个Segment的查询操作,Realtime Node收到声明后,也向Coordinator Node声明,其不再提供此Segment查询。
Druid有着自己的数据存储的逻辑和格式(主要是DataSource和Segment)
DataSource包含以下内容:
时间列(TimeStamp): 表明每行数据的时间值,默认使用 UTC 时间格式且精确到毫秒级别。这个列是数据聚合与范围查询的重要维度。
维度列(Dimension):维度来自于OLAP的概念,用来标识数据行的各个类别信息。
指标列(Metric):指标对应于OLAP概念中的Fact,是用于聚合和计算的列这些指标列通常是一些数字,计算操作通常包括 Count、Sum 和 Mean 等。
无论是实时数据消费还是批量数据处理,Druid 在基于 DataSource 结构存储数据时即可选择对任意的指标列进行聚合(Roll Up)操作。
相对于其他时序数据库,Druid 在数据存储时便可对数据进行聚合操作是其一大特点, 并且该特点使得 Druid 不仅能够节省存储空间,而且能够提高聚合查询的效率。
DataSource 是一个逻辑概念,Segment 却是数据的实际物理存储格式,Druid 正是通过 Segment 实现了对数据的横纵向切割(Slice and Dice)操作。
从数据按时间分布的角度来看, 通过参数 segmentGranularity 的设置,Druid 将不同时间范围内的数据存储在不同的 Segment 数据块中,这便是所谓的数据横向切割。
这种设计为 Druid 带来一个显而易见的优点:
按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment 数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
同时,在 Segment 中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且对Segment 中的维度列使用了 Bitmap 技术对其数据的访问进行了优化。
其中,Druid会为每一维度列存储所有列值、创建字典(用来存储所有列值对应的ID)以及为每一个列值创建其bitmap索引以帮助快速定位哪些行拥有该列值。

6、Apache Druid查询速度快原因
数据的预聚合
Druid 可以按照给定的时间粒度和所有维度列,进行最细粒度的指标聚合运算,并加以保存为原始数据。
列式存储
对部分列进行查询时可以显著提高效率。
Bitmap 索引
利用位图对所有维度列构建索引,可以快速定位数据行。
mmap
通过内存映射文件的方式加快对于 Segment 的访问。
查询结果的中间缓存
支持对于查询级别和 segment 级别的缓存。
7、Druid的数据源和分段
Druid的数据存储在"DataSource"中,这其实类似于传统的RDBMS中的表.每一个数据源按照时间进行分段,当然你还可以选择其他属性进行分段.每一个时间区间被称为一个"Chunk".(举个列子,一天的时间区间的Chunk,如果你的数据源是按天进行分段的).在一个Chunk内,数据被分成一个或者多个"segments".每个segment是一个单独的文件,它由数以百万的数据行构成.因为segment是组织在时间chunk里的,所以按照时间曲线有助于理解segments,像下面这样的
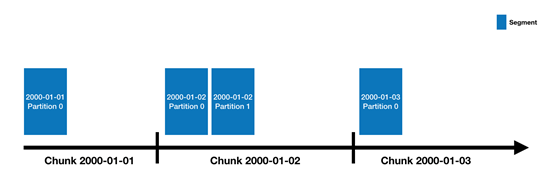
一个数据源刚开始由几个segments一直扩展到几百几千甚至上百万个segments.每个segment的生命周期始于被MiddleManager创建,这个时候segment是可变的没有被提交的.一个segment的构建包含以下列出来的步骤,这种设计是为了满足一个可以支持压缩并可以被快速查询的文件格式
- 转换成列式存储格式
- 利用bitmap建立索引
- 利用多种算法进行压缩
segments会周期性的提交和发布.此时它会被写入deep storage然后状态改为不可变的.随后它会被从MiddleManager移动到Historical进程中去.与此同时关于这个segment的一个条目也会被写入元数据存储.这个条目是描述该segment的元数据,包含segment的schema,大小,以及它在deep storage上的存储位置.所有这些类似的条目都会被Coordinator用来寻找对应的数据是否在集群上是可用状态的。
8、Druid的数据采集格式
Druid可以采集非标准化的数据诸如JSON,CSV或者以某种分隔符隔开的TSV格式,当然还支持自定义格式.虽然大部分的文档使用JSON格式,但是通过druid来配置支持其他的限定格式也不是很难。
当前支持的格式化数据
- 列表项
JSON
{"timestamp": "2013-08-31T01:02:33Z", "page": "Gypsy Danger", "language" : "en",
"user" : "nuclear", "unpatrolled" : "true", "newPage" : "true", "robot": "false",
"anonymous": "false", "namespace":"article", "continent":"North America",
"country":"United States", "region":"Bay Area", "city":"San Francisco",
"added": 57, "deleted": 200, "delta": -143}
CSV
2013-08-31T01:02:33Z,"Gypsy Danger","en","nuclear", "true","true","false","false","article","North America", "United States","Bay Area","San Francisco",57,200,-143
TSV
2013-08-31T01:02:33Z "Gypsy Danger" "en" "nuclear" "true" "true" "false" "false" "article" "North America" "United States" "Bay Area" "San Francisco" 57 200 -143
需要注意的是CSV,TSV不能包含列头,这点在数据采集的时候一定要注意
自定义格式
Druid支持使用正则解析和JavaScript来自定义数据格式.但是这种方式并没有自己实现的Java解析器或者额外的流式处理工具效率更高。
配置数据采集的schema
什么是data schema?其实就是Druid的index数据摄取任务需要的数据源的描述的元数据.它主要描述要采集的数据类型,数据由哪些列构成,哪些是指标列,哪些是维度列,时间的粒度等。
以CSV格式举例
"parseSpec": { "format" : "csv", "timestampSpec" : { "column" : "timestamp" }, "columns" : ["timestamp","page","language","user","unpatrolled","newPage","robot","anonymous","namespace","continent","country","region","city","added","deleted","delta"], "dimensionsSpec" : { "dimensions" : ["page","language","user","unpatrolled","newPage","robot","anonymous","namespace","continent","country","region","city"] }}
parseSpec指明了数据源格式,这里是format中表明是CSV格式,然后说明时间戳字段名是timestamp,数据字段名是columns里面那一堆,dimensionsSpec则代表哪些字段可以作为维度。
实例参考:https://my.oschina.net/u/2460844/blog/649466
9、数据加载方式
a)本地批处理摄取文件
具体操作请参考:https://druid.apache.org/docs/latest/tutorials/tutorial-batch.html
b)从Apache Kafka加载流数据
具体操作请参考:https://druid.apache.org/docs/latest/tutorials/tutorial-kafka.html
c) 使用Apache Hadoop加载文件
具体操作请参考: https://druid.apache.org/docs/latest/tutorials/tutorial-batch-hadoop.html
流式数据源 (实时导入)
实时数据首先会被直接加载到实时节点内存中的堆结构换从去,当条件满足时,缓存区里的数据会被写到硬盘上行程一个数据块(Segment),同事实时节点又会立即将新生成的数据块加载到内存中的非堆区,因此无论是堆缓存区还是非堆区里的数据,都能被查询节点(Broker Node)查询;
同时实时节点会周期性的将磁盘上同一时间段内生成的数据块合并成一个大的Segment,这个过程在实时节点中的操作叫做Segment Merge,合并后的大Segment会被实时节点上传到数据文件存储(DeepStorage)中,上传到DeepStorage后,协调节点(Coordination Node)会指定一个历史节点(Historical Node)去文件存储库将刚刚上传的Segment下载到本地磁盘,该历史节点加载成功后,会通过协调节点(Coordination Node)在集群中声明该Segment可以提供查询了,当实时节点收到这条声明后会立即向集群声明实时节点不再提供该Segment的查询,而对于全局数据来说,查询节点(Broker Node)会同时从实时节点与历史节点分别查询,对结果整合后返回用户。
静态数据源(离线数据导入)
首先通过Indexing Service提交Indexing作业,将输入数据转换为Segments文件。然后需要一个计算单元来处理每个Segment的数据分析,这个计算单元就是Druid中的 历史节点(Historical Node),
Historical Node是Druid最主要的计算节点,用于处理对Segments的查询。在能够服务Segment之前, Historical Node需要首先将Segment从HDFS、S3、本地文件等下载到本地磁盘,然后将Segment数据文件mmap到进程的地址空间。
Historical Node采用了Shared-Nothing架构,状态信息记录在Zookeeper中,可以很容易地进行伸缩。 Historical Node在Zookeeper中宣布自己和所服务的Segments,也通过Zookeeper接收加载/丢弃Segment的命令。
最后,由于Segment的不可变性,可以通过复制Segment到多个 Historical Node来实现容错和负载均衡,这也体现了druid的扩展性和高可用。
10、数据导入流程说明

Parse data——确定正确的解析器。在这种情况下,它将成功确定json。随意使用不同的解析器选项来预览Druid如何解析您的数据。
Parse time——要一个主时间戳列(内部存储在名为的列中__time)。如果您的数据中没有时间戳,请选择Constant value。在我们的示例中,数据加载器将确定time原始数据中的列是可用作主时间列的唯一候选者。
Configure schema——您可以配置将哪些维度和指标摄入到Druid中。数据一经摄取,就会在Druid中显示出来。由于我们的数据集非常小,因此请继续并Rollup通过单击开关并确认更改将其关闭。
Partition——您可以调整如何在Druid中将数据拆分为多个段。由于这是一个很小的数据集,因此在此步骤中无需进行任何调整。
Tune——在Tune步骤是非常重要的设置Use earliest offset到True,因为我们要从流的开始消耗数据。没有其他需要更改的内容,因此请单击Next: Publish以转到Publish步骤。
Publish——发布
Edit JSON spec——可以随意返回并在之前的步骤中进行更改,以查看更改将如何更新规范。同样,您也可以直接编辑规范,并在前面的步骤中看到它。
11、历史数据更新
数据不能作更改操作,想要做更新需要通过hadoop任务整体覆盖
12、Druid连接JAVA
1)pom中引入
<dependency>
<groupId>org.apache.calcite.avatica</groupId>
<artifactId>avatica-core</artifactId>
<version>1.15.0</version>
</dependency>
2)连接
public class DruidJdbcUtil { public static AvaticaConnection connection() throws SQLException{ String urlStr = "jdbc:avatica:remote:url="【http://ip:8082】/druid/v2/sql/avatica/"; Properties connectionProperties = new Properties(); AvaticaConnection connection = DriverManager.getConnection(urlStr, connectionProperties); AvaticaStatement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery(sql); while (resultSet.next()) { String aa = resultSet.getString("aaa); ...... } } }
13、注意事项
1)Druid适用于宽表,不用Join方式
2)时序化数据:Druid 可以理解为时序数据库,所有的数据必须有时间字段。
3)实时数据接入可容忍丢数据(tranquility):目前 tranquility 有丢数据的风险,所以建议实时和离线一起用,实时接当天数据,离线第二天把今天的数据全部覆盖,保证数据完备性。
14、druid 丢失数据有几个情况
1、peon读取了加载数据, 但写不到深度储存里, 那这些数据只能在短暂时间内查询得到, 但过了maxTime, 就会被丢弃了。
2、深度储存丢失数据,
3、meta db(元数据,MySQL和PostgreSQL是更适合生产的元数据存储) 丢失数据。
而这些条件,都在druid的控制范围之外,所以说,druid自己不会丢失数据


