
Apache kylin探究
1、 核心思想
Apache Kylin的核心思想是利用空间换时间,它主要是通过预计算的方式将用户设定的多维立方体缓存到HBase中(目前还仅支持hbase),
同时由于Apache Kylin在查询方面制定了多种灵活的策略,进一步提高空间的利用率,使得这样的平衡策略在应用中值得采用。
kylin主要是对hive中的数据进行预计算,利用hadoop的mapreduce框架实现。
2、 使用场景
(1)假如你的数据存在于Hadoop的HDFS分布式文件系统中,并且你使用Hive来基于HDFS构建数据仓库系统,并进行数据分析,但是数据量巨大,比如TB级别。
(2)同时你的Hadoop平台也使用HBase来进行数据存储和利用HBase的行键实现数据的快速查询等应用
(3)你的Hadoop平台的数据量逐日累增
3、 用户权限
用户是否可以访问项目并使用项目中的某些功能由项目级别的访问控制确定,Apache Kylin在项目级别设置了四种类型的访问权限角色。它们是ADMIN, MANAGEMENT, OPERATION , QUERY.。每个角色都定义了用户可以在Apache Kylin中执行的功能的列表。
A ) QUERY:设计用于仅需要访问权限来查询项目中表/多维数据集的分析人员。
B ) OPERATION:旨在供需要许可以维护多维数据集的公司/组织中的运营团队使用。OPERATION访问权限包括QUERY。
C ) MANAGEMENT:设计为完全了解数据/模型的业务含义的Modeler或Designer使用,Cube将负责Model和Cube设计。管理访问权限包括“操作”和“查询”。
D ) ADMIN:旨在完全管理项目。ADMIN访问权限包括管理,操作和查询。
访问权限在不同项目之间是独立的。
为用户设置项目级访问权限后,将基于在项目级上定义的访问权限角色继承对数据源,模型和Cube的访问权限。有关详细功能,每个访问权限角色都可以访问,请参见下图。
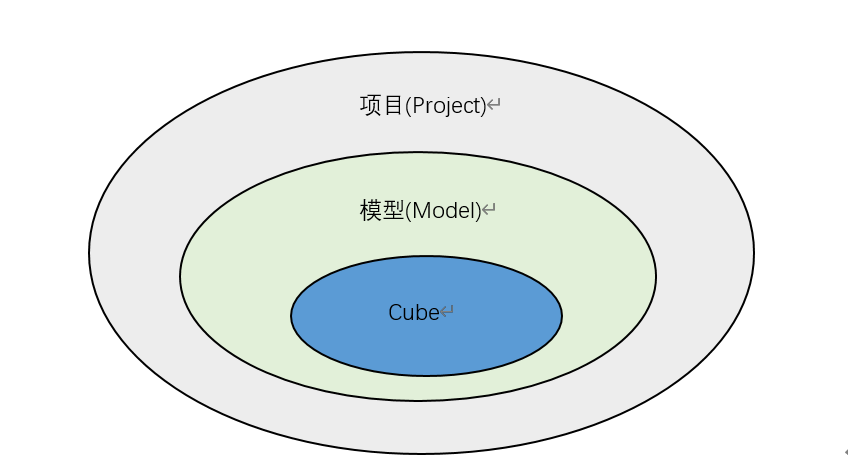
图1.1项目关系图
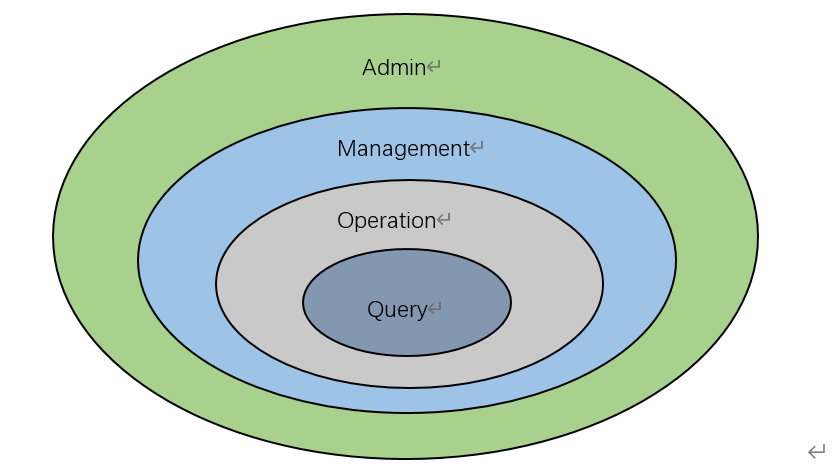
图1.2权限关系图
|
|
系统管理员 System Admin |
项目管理员 Project Admin |
管理 Management |
运营 Operation |
询问 Query |
|
创建/删除项目 |
是 |
没有 |
没有 |
没有 |
没有 |
|
编辑项目 |
是 |
是 |
没有 |
没有 |
没有 |
|
添加/编辑/删除项目访问权限 |
是 |
是 |
没有 |
没有 |
没有 |
|
检查模型页面 |
是 |
是 |
是 |
是 |
是 |
|
检查数据源页面 |
是 |
是 |
是 |
没有 |
没有 |
|
加载,卸载表,重新加载表 |
是 |
是 |
没有 |
没有 |
没有 |
|
以只读模式查看模型 |
是 |
是 |
是 |
是 |
是 |
|
添加,编辑,克隆,删除模型 |
是 |
是 |
是 |
没有 |
没有 |
|
检查cube详细信息定义 |
是 |
是 |
是 |
是 |
是 |
|
添加,禁用/启用,克隆cube,编辑,放置cube,清除多cube |
是 |
是 |
是 |
没有 |
没有 |
|
建立,刷新,合并cube |
是 |
是 |
是 |
是 |
没有 |
|
编辑,查看cube json |
是 |
是 |
是 |
没有 |
没有 |
|
检查洞察页面 |
是 |
是 |
是 |
是 |
是 |
|
在见解页面中查看表 |
是 |
是 |
是 |
是 |
是 |
|
检查监控页面 |
是 |
是 |
是 |
是 |
没有 |
|
检查系统页面 |
是 |
没有 |
没有 |
没有 |
没有 |
|
重新加载元数据,禁用缓存,设置配置,诊断 |
是 |
没有 |
没有 |
没有 |
没有 |
此外,启用查询下推时,对项目的QUERY访问权限允许用户对项目中的所有表发出下推查询,即使没有多维数据集也不能为他们服务。如果尚未在项目级别为用户授予QUERY权限,则是不可能的。
2、kylin全量设置
对数据模型中没有指定分割时间列信息的Cube,Kylin会采用全量构建,即每次从Hive中读取全部的数据来开始构建。通常它适用于以下两种情形。
事实表的数据不是按时间增长的。
事实表的数据比较小或更新频率很低,全量构建不会造成太大的开销
3、kylin增量设置
Kylin每次都会从Hive中读取一个时间范围内的数据,然后进行计算,并以一个Segment的形式进行保存。
需要设置构建model的measure的partition在设置时间段的进行构建cube。
4、定时刷新增量cube
编写定时任务的shell脚本,定时构建cube,shell内容如下:
#! /bin/bash cube_name = cube的名字 do_date = `date -d '-1 day' +%F` #获取00:00时间戳 start_date_unix=`date -d "$do_date 00:00:00" +%s` start_date=$(($start_date_unix*1000)) #获取24:00时间戳 stop_date=$(($start_date+86400000)) curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'$start_date',"endTime":'$endTime', "buildType":"BUILD"}' http://ip:7070/kylin/api/cubes/$cubeName/cube的名字
5、历史数据刷新
a) 在页面上点击刷新
b) 全量构建的Cube只要重新全部构建就可以得到更新
增量更新的Cube因为有多个Segment,因此需要先选择要刷新的Segment,然后再进行刷新。
Kylin是从Hive中来拉取原始数据的,当我们增量的数据通过ETL进入Hive以后,可以紧接着在ETL脚本中发起一个增量构建的HTTP请求:
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"endTime":"{endTime}", "startTime":"{startTime}", "buildType":"BUILD"}' http://localhost:7070/kylin/api/cubes/{cubeName}/rebuild
在脚本中保存上一次构建的endTime,作为此次构建的startTime,此次构建的endTime可以设置为ETL中按时间段抓取数据的结束时间,并保存此次构建的endTime作为下次构建的startTime。
6、实时OLAP
Kylin v3.0.0发布了全新的实时OLAP功能,借助新添加的流接收器群集的功能,Kylin可以以亚秒级的延迟查询流数据。
配置
####全局级别配置
kylin.stream.job.dfs.block.size:指定使用的流式基本立方体作业的HDFS块大小。默认值为16M。kylin.stream.index.path:指定存储段缓存文件(包括片段和检查点文件)的本地路径。默认值为stream_index。kylin.stream.node:指定协调器/接收器的节点。值应为hostname:port或port。如果设置为port,Kylin将自动完成主机名。当Kylin进程开始时,它将注册到元数据中。默认值为null。kylin.stream.metadata.store.type:指定元数据存储的位置。默认值为zk。该条目很简单,因为它只有一个选项。kylin.stream.receiver.use-threads-per-query:指定每个查询使用的线程号。默认值为8。
多维数据集级别配置
kylin.stream.index.maxrows:指定JVM堆中保留的聚合事件的最大数目。默认值为50000。如果您有足够的堆大小,请尝试提高它。kylin.stream.cube-num-of-consumer-tasks:指定共享整个主题分区的副本集的数量。它影响将多少个分区分配给不同的副本集。默认值为3。kylin.stream.segment.retention.policy:指定当段变为IMMUTABLE时处理本地段缓存的策略。可选值包括purge和fullBuild。purge意味着当该段变为IMMUTABLE时,它将被删除。fullBuild意味着当该段变为IMMUTABLE时,它将被上传到HDFS。默认值为fullBuild。kylin.stream.build.additional.cuboids:是否要建立其他长方体。附加的长方体表示在“ 多维数据集高级设置”页面中选择的强制尺寸的集合。默认值为false。默认情况下仅构建Base Cuboid。如果您关心QPS,可以尝试启用它,并且可以预见大多数查询模式。kylin.stream.cube.window:指定每个段的持续时间,以秒为单位的值。默认值为3600。请在deep-dive-real-time-olap查看详细信息。kylin.stream.cube.duration:指定段状态从活动状态变为IMMUTABLE的等待时间,以秒为单位。默认值为7200。请在deep-dive-real-time-olap查看详细信息。kylin.stream.cube.duration.max:指定分段可以保持活动状态的最长时间,以秒为单位。默认值为43200。请在deep-dive-real-time-olap查看详细信息。kylin.stream.checkpoint.file.max.num:指定每个多维数据集的最大检查点文件数。默认值为5。kylin.stream.index.checkpoint.intervals:指定设置两个检查点之间的时间间隔。默认值为300。kylin.stream.immutable.segments.max.num:指定当前流式接收器的每个多维数据集中的IMMUTABLE段的最大数目,如果超过该数目,将暂停当前主题的使用。默认值为100。kylin.stream.consume.offsets.latest:从最近的偏移量还是从最早的偏移量开始消耗。默认值为true。
进阶设定
kylin.stream.assigner:指定用于将主题分区分配给不同副本集的实现类。该类应该是的实现类org.apache.kylin.stream.coordinator.assign.Assigner。默认值为DefaultAssigner。
kylin.stream.coordinator.client.timeout.millsecond:指定协调器客户端的连接超时。默认值为5000。kylin.stream.receiver.client.timeout.millsecond:指定接收方客户端的连接超时时间。默认值为5000。kylin.stream.receiver.http.max.threads:指定接收方的最大连接线程数。默认值为200。kylin.stream.receiver.http.min.threads:指定接收方的最小连接线程。默认值为10。kylin.stream.receiver.query-core-threads:指定用于当前流式接收器的查询线程数。默认值为50。kylin.stream.receiver.query-max-threads:指定用于当前流式接收器的最大查询线程数。默认值为200。kylin.stream.segment-max-fragments:指定每个段保留的最大片段数。默认值为50。kylin.stream.segment-min-fragments:指定每个段保留的最小片段数。默认值为15。kylin.stream.max-fragment-size-mb:指定每个片段的最大大小。默认值为300。kylin.stream.fragments-auto-merge-enable:是否在流式接收器端启用片段自动合并。默认值为true。kylin.stream.metrics.option:指定如何在流式接收器端报告指标,选项值为csv / console / jmx。kylin.stream.event.timezone:指定哪个时区应该派生时间列,例如HOUR_START/DAY_START使用。kylin.stream.auto-resubmit-after-discard-enabled:查找到以前的工作时是否自动重新提交新的建筑工作,将被用户丢弃。

详细操作可参考:http://kylin.apache.org/docs/tutorial/realtime_olap.html
7、时效的影响及优化
1 >kylin主要通过空间换时间的方式来提高查询性能。Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid。
2 >高基数维度也会影响cube构建效率,根据业务需求尽量减少高基维度在子cube中出现的次数。
3 >kylin默认选择的存储引擎是Hbase,所以rowKey的设计与Hbase的查询效率密切相关
优化方法如下:
a) 衍生维度(不推荐)减少计算,查询聚合会变慢
b) 必要维度(在构建cube的Advanced Setting下Aggregation Groups的Mandatory Dimensions)用于总是出现的维度。例如,如果你的查询中总是会带有 “ORDER_DATE” 做为 group by 或 过滤条件, 那么它可以被声明为必要维度。这样一来,所有不含此维度的 cuboid 就可以被跳过计算。
c) 层级维度(Hierarchy Dimensions),例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。
d) 联合维度(Joint Dimensions),有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
e) Rowkeys:是由维度编码值组成。”Dictionary” (字典)是默认的编码方式; 字典只能处理中低基数(少于一千万)的维度;如果维度基数很高(如大于1千万), 选择 “false” 然后为维度输入合适的长度,通常是那列的最大长度值; 如果超过最大值,会被截断。请注意,如果没有字典编码,cube 的大小可能会非常大。
可以拖拽维度列去调整其在 rowkey 中位置; 位于rowkey前面的列,将可以用来大幅缩小查询的范围。通常建议将 mandantory 维度放在开头, 然后是在过滤 ( where 条件)中起到很大作用的维度;如果多个列都会被用于过滤,将高基数的维度(如 user_id)放在低基数的维度(如 age)的前面。
8、维度和指标个数(混合模型)
当kylin构建的维度和指标个数发生改变的时候,可以在kylin1.0版本中引入混合模型(也称为“动态模型”),可解决增加从之前的cube中维度和指标的cube。
关于Hybrid的概念如下参考:
现在让我们从一个示例案例开始;假设用户有一个名为“ Cube_V1”的多维数据集,它已经建立了几个月。现在,用户希望添加新的维度或指标来满足其业务需求;因此,他创建了一个名为“ Cube_V2”的新多维数据集;
由于某些原因,用户希望保留“ Cube_V1”,并希望从“ Cube_V1”的结束日期开始构建“ Cube_V2”;可能的原因包括:
- 历史记录源数据已从Hadoop中删除,从一开始就无法构建“ Cube_V2”。
- 多维数据集很大,重建需要很长时间。
- 新的维度/指标仅在某天开始可用或应用;
- 当查询使用新的维度/指标时,用户认为过去的结果为空是可以的。
对于针对常见维度/指标的查询,用户希望同时扫描“ Cube_V1”和“ Cube_V2”以获得完整的结果集;在这样的背景下,引入了“混合模型”来解决这个问题。
混合模型是一种新的实现,它是一个或多个其他实现(多维数据集)的组合;参见下图。
Hybrid并没有真正的存储空间。就像表上的虚拟数据库视图一样。混合实例充当委派者,将请求转发到其子实现,然后在从子实现返回时合并结果。
9、kylin生成segment存放入HBASE中大小限制问题:
Kylin在build过程中,每一个cuboid的数据都会被分到若干个分片中(这里的分片就对应HBase中的region)。
kylin.storage.hbase.region-cut-gb:单个 Region 的大小,默认值为 5.0
kylin.storage.hbase.min-region-count:指定最小 Region 个数,默认值为 1
kylin.storage.hbase.max-region-count:指定最大 Region 个数,默认值为 500
kylin.storage.hbase.hfile-size-gb:指定 HFile 大小,默认值为 2.0(GB)
10、支持数据请求
f) 支持jdbc连接kylin
需要配置pom.xml加入配置
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
第一种方法:使用Statement方式查询
第二种方法:使用PreparedStatement方式查询
第三种方法:获取查询结果集元数据
package org.apache.kylin.jdbc; import java.sql.SQLException; import java.util.Properties; import org.junit.Test; import java.sql.Connection; import java.sql.Driver; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Statement; public class QueryKylinST { @Test public void testStatementWithMockData() throws SQLException, InstantiationException, IllegalAccessException, ClassNotFoundException { // 加载Kylin的JDBC驱动程序 Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance(); // 配置登录Kylin的用户名和密码 Properties info= new Properties(); info.put("user","ADMIN"); info.put("password","KYLIN"); // 连接Kylin服务 Connection conn= driver.connect("jdbc:kylin://10.8.217.66:7070/learn_kylin",info); Statement state= conn.createStatement(); ResultSet resultSet =state.executeQuery("select part_dt, sum(price) as total_selled,count(distinct seller_id) as sellers " + "from kylin_sales group by part_dt order by part_dt limit 5"); System.out.println("part_dt\t"+ "\t" + "total_selled" + "\t" +"sellers"); while(resultSet.next()) { String col1 = resultSet.getString(1); String col2 = resultSet.getString(2); String col3 = resultSet.getString(3); System.out.println(col1+ "\t" + col2 + "\t" + col3); } } @Test public void testanylist() throws Exception { Driver driver =(Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance(); Properties info= new Properties(); info.put("user","ADMIN"); info.put("password","KYLIN"); Connection conn= driver.connect("jdbc:kylin://10.8.217.66:7070/learn_kylin",info); PreparedStatement state = conn.prepareStatement("select * from KYLIN_CATEGORY_GROUPINGS where LEAF_CATEG_ID = ?"); state.setLong(1,10058); ResultSet resultSet = state.executeQuery(); while (resultSet.next()) { String col1 = resultSet.getString(1); String col2 = resultSet.getString(2); String col3 = resultSet.getString(3); System.out.println(col1+ "\t" + col2 + "\t" + col3); } } @Test public void testmetadatalist() throws Exception { Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance(); Properties info = new Properties(); info.put("user", "ADMIN"); info.put("password", "KYLIN"); Connection conn = driver.connect("jdbc:kylin://10.8.217.66:7070/learn_kylin", info); Statement state = conn.createStatement(); ResultSet resultSet = state.executeQuery("select * from kylin_sales"); //第三个是表名称,一般情况下如果要获取所有的表的话,可以直接设置为null,如果设置为特定的表名称,则返回该表的具体信息。 ResultSet tables = conn.getMetaData().getTables(null, null, null, new String[]{"TABLE"}); while (tables.next()) { // for (int i = 0; i < 10; i++) { // System.out.println(tables.getString(i + 1)); // } String col1 = tables.getString(1); //表类别 String col2 = tables.getString(2); //表模式 String col3 = tables.getString(3); //表名称 System.out.println("表信息:"+col1+ "\t" + col2 + "\t" + col3); } } }
g) 支持ODBC
Apache Kylin不再提供预先构建的ODBC驱动程序。您可以自行从源代码来编译生成(在“ odbc”子目录中),或者从第三方厂商获得。
11、维度上限
Kylin对于维度的上限是64个。达到15个维度以上,需要对模型做深入优化(参考5时效影响),否则有性能问题。
指标没有上限。但一般很少过百。

