


Redis高性能内存数据库
(一)什么是Redis?
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。与Memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。[1]
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。
(二)Redis与Memcached的区别
u 持久化:
l Redis可以用来做缓存,也可以做存储;支持ADF和RDB两种持久化方式
l Memcached只能缓存数据
u 数据结构:
l Redis有丰富的数据类型:字符串、链表,Hash、集合,有序集合
l Memcached一般就是字符串和对象
(三)Redis的安装与配置
1.解压:tar -zxvf redis-3.0.5.tar.gz
2.make
3.make PREFIX=/root/training/redis install
4.cp ~/tools/redis-3.0.5/redis.conf /root/training/redis/etc/
Redis的核心配置文件:redis.conf

Redis的命令脚本:
redis-benchmark 性能测试工具
redis-check-aof 检查AOF日志
redis-check-dump 检查RDB日志
redis-cli 启动命令行客户端
redis-sentinel
redis-server 启动Redis服务
启动Redis:
./redis-server ../etc/redis6379.conf
./redis-server ../etc/redis6380.conf
这样就在6379和6380端口上,各自启动了一个Redis实例;也可以通过ps命令查看:

启动Redis的客户端:redis-cli
l 默认连接6739端口,也可以通过-p指定连接的端口号:
l ./redis-cli --help显式帮助信息
(四)Redis的操作
http://www.redis.cn/commands.html
key操作
redis 的 key 是以 string 储存的,redis 对于 key 常用的操作指令如下:
1.select db_name 使用指定数据库 select 1 # 使用数据库 1
2.exits key_name 检查指定的 key 是否存在
3.get key_name 获取指定 key 的 value
4.mget key1 [key2 ..] 获取指定多个 key 的 value,
5.randomkey 随机获取一个 key
6.set key_name key_value 设置 key-value
7.getset key_name key_value 设置 key-value,并返回 key 的旧值
8.setnx key_name value 只有在 key 不存在时,才设置 key
9.mset key1 val1[ key1 val2...] 同时设置多个 key-value
10.del key_name 删除指定的 key
11.rename key_name new_key_name 重命名指定key
12.type key_name 返回指定 key 的 value 的类型
13.dump key_name 序列化指定 key,并返回该 key 序列化后的 value
14.keys pattern 查找所有符合给定 pattern 的 key,支持使用 * 作为通配符;
15.keys a* # 查找所有以 ‘a’ 开头的 key
16.keys * # 查找所有 key
17.move key_name db_name 将指定 key-value 移动到指定数据库
18.expire key_name seconds pexpire key_name milliseconds
给指定key设置过期时间,单位分别为秒,毫秒
19.expireat key_name timestamp 设置指定的key 在指定的UNIX时间戳过期
20.ttl key_name pttl key_name
返回 key 的 TTL(Time to Live)生存时间,分别以 秒,毫秒为单位;
21.persist key_name 移除指定 key 的过期时间,该 key 将持久保存
22.flushdb 删除当前数据库的所有 key
23.flushall 删除所有数据库的 key
其他操作可进入链接查看
数据类型
① 字符串
② 链表
③ Hash

④ 无序集合
⑤ 有序集合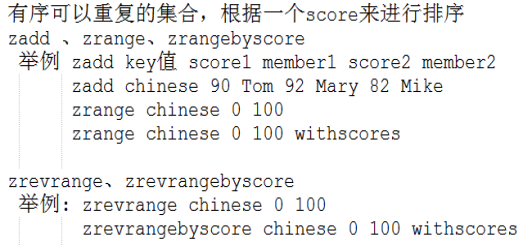
⑥ Redis数据类型案例分析:网站统计用户登录的次数
- 1亿个用户,有经常登录的,也有不经常登录的
- 如何来记录用户的登录信息
- 如何查询活跃用户:比如:一周内,登录3次的
解决方案一:采用关系型数据库
解决方案二:采用Redis存储登录信息
可以使用Redis的setbit,登录与否:有1和0就可以表示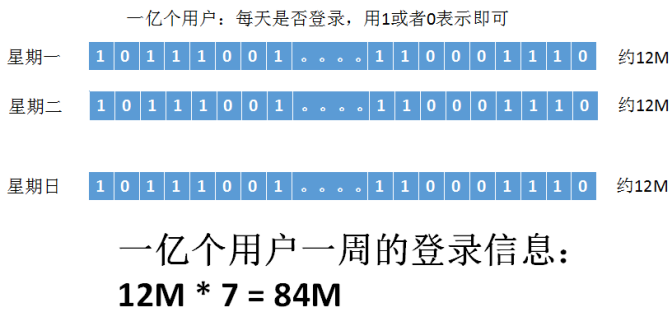
25.Java客户端
① 基本操作
② 连接池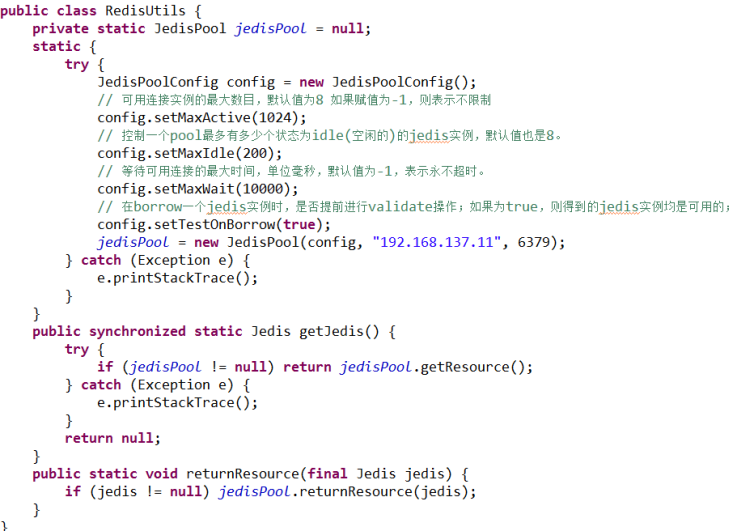
③ 使用Redis实现分布式锁
使用Maven搭建工程:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
(五)Redis的事务和消息机制
1.Redis的事务
Redis对事务的支持目前还比较简单。redis只能保证一个client发起的事务中的命令可以连续的执行,而中间不会插入其他client的命令。 由于redis是单线程来处理所有client的请求的所以做到这点是很容易的。一般情况下redis在接受到一个client发来的命令后会立即处理并 返回处理结果,但是当一个client在一个连接中发出multi命令有,这个连接会进入一个事务上下文,该连接后续的命令并不是立即执行,而是先放到一个队列中。当从此连接受到exec命令后,redis会顺序的执行队列中的所有命令。并将所有命令的运行结果打包到一起返回给client.然后此连接就 结束事务上下文。
Oracle数据库中的事务和Redis的事务对比
|
|
Oracle |
Redis |
|
开启事务的方式 |
自动开启事务 |
multi |
|
操作 |
DML语句 |
Redis命令 |
|
提交事务 |
commit |
exec |
|
回滚事务 |
rollback |
discard |
2.Redis的事务示例:银行转账
从Tom转100块钱给Mike
- set tom 1000
- set mike 1000
- multi
- decrby tom 100
- incrby mike 100
- exec
3.Redis的锁机制:watch
l 举例:买票
4.Java应用程序中的事务和锁
① 事务
② 锁
5.Redis的消息机制:消息的发布与订阅,适合做在线聊天
publish:发布消息
格式:publish channel名称 “消息内容”
subscribe: 订阅消息
格式:subscribe channel名称
psubscribe: 使用通配符定义消息
格式:psubscribe channel*名称
使用Java程序实现消息的发布与订阅,需要继承JedisPubSub类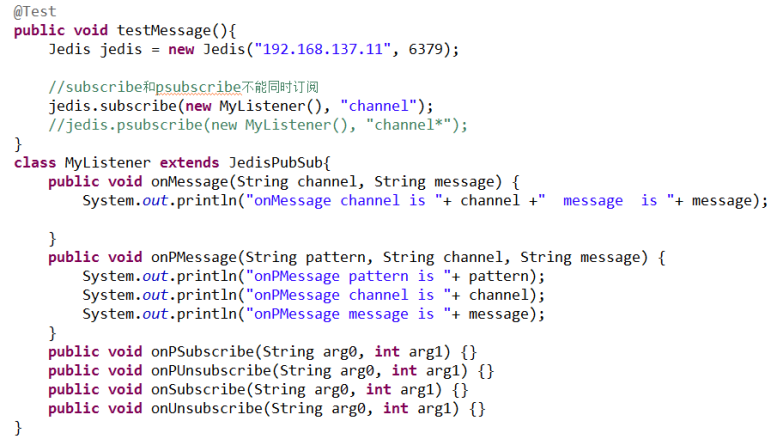
(六)Redis的持久化
Redis 提供了多种不同级别的持久化方式:
- RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
- AOF (Append-only file)持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。
- Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
- 你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
1、RDB
工作原理:每隔一定时间给内存照一个快照,将内存中的数据写入文件(rdb文件)配置参数:redis.conf文件(在conf文件中找到对应位置)
- RDB示例测试:可以使用redis-benchmark进行压力测试
- ./bin/redis-benchmark -n 100000 表示执行100000个操作
- RDB的缺点:
- 在两次快照之间,如果发生断电,数据会丢失
- 举例:在生成rdb后,插入新值。突然断电,数据可能会丢失
2、AOF:通过日志的方式
- 工作原理:记录操作的命令
- 配置参数:

- 什么是AOF的重写:rewrite
- 将内存中的key逆向生成命令,如同一个可以,反复操作了100次,aof文件会记录100次操作,这样会导致AOF文件过大
例如:
set age 0
incr age
incr age
... 100次
最后 age的值是100
经过重写后,直接执行: set age 100
2.可以通过观察aof日志文件的大小
3、Redis持久化注意的问题
- RDB恢复的速度快
- 如果RDB和AOF都有,默认使用AOF进行恢复
(七)Redis的集群
1.集群的作用
l 主从备份 防止主机宕机
l 读写分离,分担master的任务
l 任务分离,如从服分别分担备份工作与计算工作
2.Redis 集群的两种部署方式
3.Redis主从服务的通信原理
4.配置Redis的集群(主从模式)
- 主节点:关闭rdb和aof即可
- 从节点:slaveof localhost 6379 开启rdb和aof
5.Redis集群的高可用性
- Redis 2.4+自带了一个HA实现Sentinel
- 配置文件:sentinel.conf

- redis-sentinel ../etc/sentinel.conf
- 查看日志:

6.实现Redis的代理分片
- Twemproxy是一种代理分片机制,由Twitter开源。
- Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。
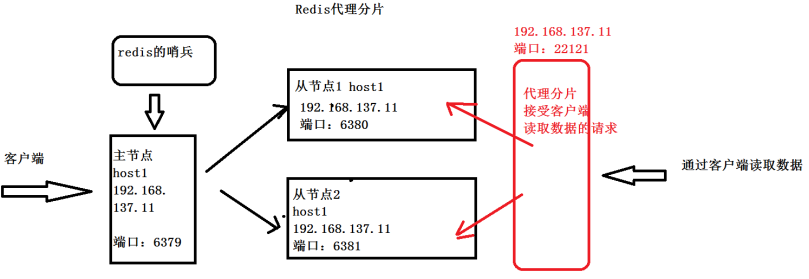
- 安装
./configure --prefix=/root/training/proxy
make
make install
- 配置文件
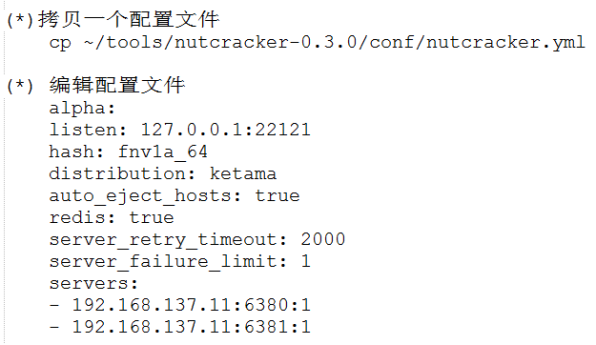
- 检查配置文件是否正确
./nutcracker -t conf/nutcracker.yml - 启动代理服务器
./nutcracker -d -c conf/nutcracker.yml
(八)Redis Cluster分布式解决方案
1.什么是Redis Cluster?
Redis Cluster是Redis的分布式解决方案,在Redis 3.0版本正式推出的,有效解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构达到负载均衡的目的。
- redis使用中遇到的瓶颈
我们日常在对于redis的使用中,经常会遇到一些问题:
(1) 高可用问题,如何保证redis的持续高可用性。
(2) 容量问题,单实例redis内存无法无限扩充,达到32G后就进入了64位世界,性能下降。
(3) 并发性能问题,redis号称单实例10万并发,但也是有尽头的。
- redis-cluster的优势
(1) 官方推荐,毋庸置疑。
(2) 去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
(3) 管理方便,后续可自行增加或摘除节点,移动分槽等等。
(4) 简单,易上手。
2.数据分布理论与Redis的数据分区
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。常见的分区规则有哈希分区和顺序分区。Redis Cluster采用哈希分区规则。
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。比如Redis Cluster槽的范围是0 ~ 16383。槽是集群内数据管理和迁移的基本单位。
Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
3.Redis Cluster的体系架构
我们以6个节点为例,来介绍Redis Cluster的体系架构。其中:三个为master节点,另外三个为slave节点。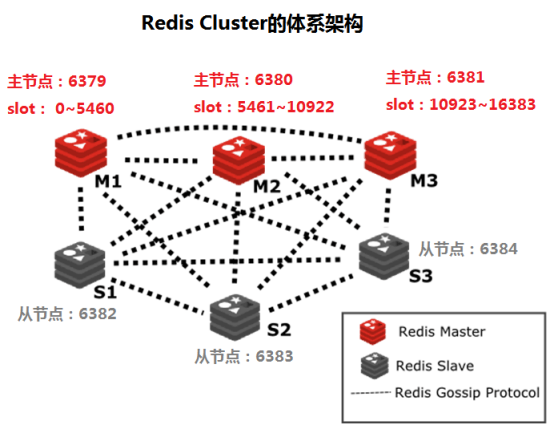
4.安装与部署(方式一:使用配置文件)
① Redis的编译安装
- 安装Linux操作系统和GCC编译
- 编译安装Redis
解压:tar -zxvf redis-3.0.5.tar.gz
make
make PREFIX=/root/training/redis install
cp ~/tools/redis-3.0.5/redis.conf /root/training/redis/etc/
② 安装Ruby环境和Ruby Redis接口
由于创建和管理需要使用到redis-trib 工具,该工具位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群,检查集群,或者对集群进行重新分片(reshared)等工作,所以需要安装Ruby环境和相应的Redis接口
下面是可以使用yum来安装Ruby:
[media]
name=Red Hat Enterprise Linux 7.4
baseurl=file:///cdroom
enabled=1
gpgcheck=1
gpgkey=file:///cdroom/RPM-GPG-KEY-redhat-release
③ 以6个节点为例,安装和部署Redis Cluster
- 主节点:6379、6380、6381
- 从节点:6382、6383、6384
- 需要修改的参数如下:其中红色字体部分需要每个实例修改。
daemonize yes
port 6379
cluster-enabled yes
cluster-config-file nodes/nodes-6379.conf
cluster-node-timeout 15000
dbfilename dump6379.rdb
appendonly yes
appendfilename "appendonly6379.aof"
- 配置文件一共六个:
redis6379.conf
redis6380.conf
redis6381.conf
redis6382.conf
redis6383.conf
redis6384.conf
④ 启动Redis 实例
bin/redis-server conf/redis6379.conf
bin/redis-server conf/redis6380.conf
bin/redis-server conf/redis6381.conf
bin/redis-server conf/redis6382.conf
bin/redis-server conf/redis6383.conf
bin/redis-server conf/redis6384.conf
通过ps命令查看进程: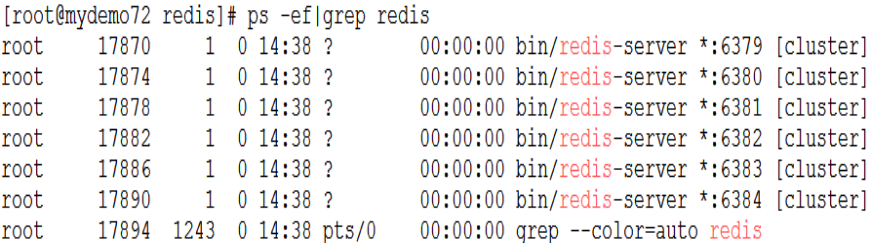
⑤ 使用redis-trib.rb自动部署方式
bin/redis-trib.rb create --replicas 1 192.168.56.72:6379 192.168.56.72:6380 192.168.56.72:6381 192.168.56.72:6382 192.168.56.72:6383 192.168.56.72:6384
注意:redis-trib.rb位于 Redis 源码的 src 文件夹中,拷贝到bin目录下。
其中:–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。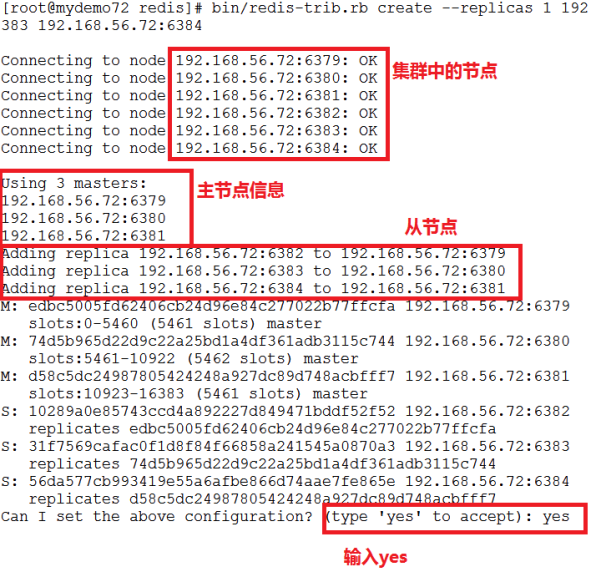
开始配置集群:
⑥ 测试Redis Cluster
- 使用客户端登录:bin/redis-cli -c -p 6379
-c表示:登录集群
可以使用:cluster nodes命令查看集群中的节点
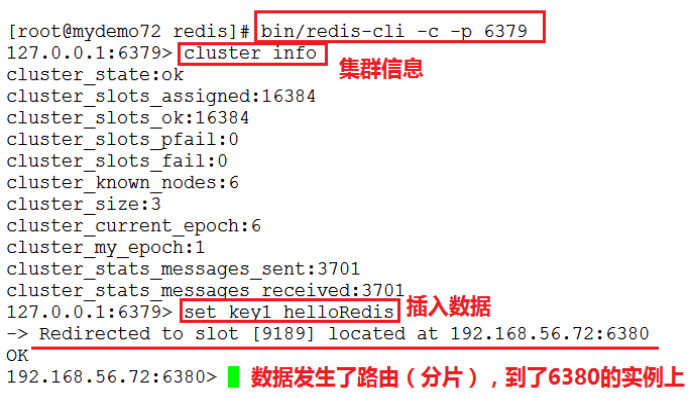
5.安装与部署(方式二:使用create-cluster命令)
将源码的utils/create-cluster目录下,将create-cluster拷贝到安装目录的bin目录下
修改create-cluster命令的路径

- 启动和创建Redis集群
- bin/create-cluster start
- bin/create-cluster create
- 使用客户端测试集群
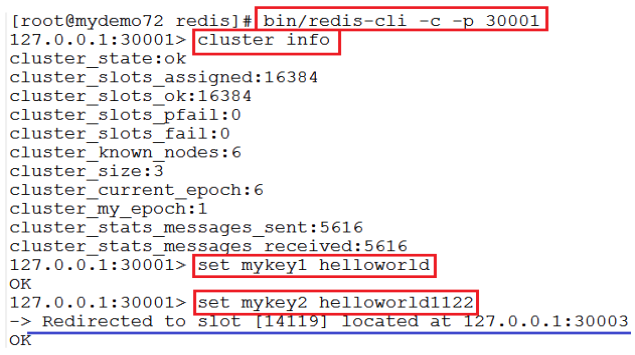
6.使用Java程序测试Redis Cluster
jar包:commons-pool2-2.3.jar jedis-2.7.0.jar


import java.util.HashSet; import redis.clients.jedis.HostAndPort; import redis.clients.jedis.JedisCluster; public class TestRedisCluster { public static void main(String[] args) throws Exception { // 指定集群的节点 HashSet<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("192.168.56.72", 6379)); nodes.add(new HostAndPort("192.168.56.72", 6380)); nodes.add(new HostAndPort("192.168.56.72", 6381)); nodes.add(new HostAndPort("192.168.56.72", 6382)); nodes.add(new HostAndPort("192.168.56.72", 6383)); nodes.add(new HostAndPort("192.168.56.72", 6384)); // 创建集群 JedisCluster cluster = new JedisCluster(nodes); // 插入3*16383条数据 for (int i = 0; i < 3 * 16383; i++) { System.out.println("插入数据:" + i); cluster.set("mykey" + i, "myvalue:" + i); } // 关闭集群客户端 cluster.close(); System.out.println("完成"); } }
7.基本的Redis Cluster管理
使用cluster <command> 命令来管理Redis Cluster:
|
命令 |
说明 |
|
info |
打印集群的信息。 |
|
nodes |
列出集群当前已知的所有节点(node)的相关信息。 |
|
meet <ip> <port> |
将ip和port所指定的节点添加到集群当中。 |
|
addslots <slot> [slot ...] |
将一个或多个槽(slot)指派(assign)给当前节点。 |
|
delslots <slot> [slot ...] |
移除一个或多个槽对当前节点的指派。 |
|
slots |
列出槽位、节点信息。 |
|
slaves <node_id> |
列出指定节点下面的从节点信息。 |
|
replicate <node_id> |
将当前节点设置为指定节点的从节点。 |
|
saveconfig |
手动执行命令保存保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件。 |
|
keyslot <key> |
列出key被放置在哪个槽上。 |
|
flushslots |
移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。 |
|
countkeysinslot <slot> |
返回槽目前包含的键值对数量。 |
|
getkeysinslot <slot> <count> |
返回count个槽中的键。 |
|
setslot <slot> node <node_id> |
将槽指派给指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽,然后再进行指派。 |
|
setslot <slot> migrating <node_id> |
将本节点的槽迁移到指定的节点中。 |
|
setslot <slot> importing <node_id> |
从 node_id 指定的节点中导入槽 slot 到本节点。 |
|
setslot <slot> stable |
取消对槽 slot 的导入(import)或者迁移(migrate) |
|
failover |
手动进行故障转移。 |
|
forget <node_id> |
从集群中移除指定的节点,这样就无法完成握手,过期时为60s,60s后两节点又会继续完成握手。 |
|
reset [HARD|SOFT] |
重置集群信息,soft是清空其他节点的信息,但不修改自己的id,hard还会修改自己的id,不传该参数则使用soft方式。 |
|
count-failure-reports <node_id> |
列出某个节点的故障报告的长度。 |
|
SET-CONFIG-EPOCH |
设置节点epoch,只有在节点加入集群前才能设置。 |
命令详解:cluster info
命令详解:cluster nodes(可以使用excel 导入命令输出,方便查看)
几点说明:
- ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过.
- pong-recv: 最近一次收到pong的时间,使用unix时间戳表示.
- config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。
命令详解:cluster slots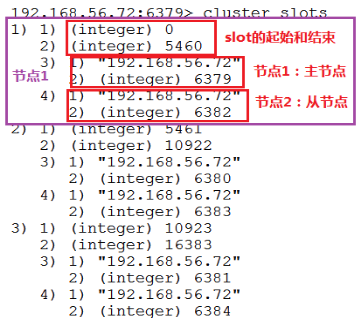
其他几个命令:
节点的添加与删除
- 增加节点(每次添加2个)
① 增加新的配置文件:redis6385.conf 和 redis6386.conf
② 按照之前的配置修改对应参数
③ 启动新的节点
bin/redis-server conf/redis6385.conf
bin/redis-server conf/redis6386.conf
④ 添加主节点
bin/redis-trib.rb add-node 192.168.56.72:6385 192.168.56.72:6379
其中:
192.168.56.72:6385是新添加的节点
192.168.56.72:6379是集群中,任一个旧节点
⑤ 检查集群的节点信息
bin/redis-trib.rb check 192.168.56.72:6379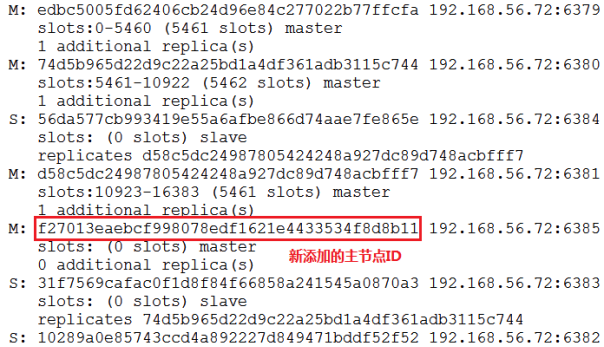
⑥ 添加从节点
bin/redis-trib.rb add-node --slave --master-id f27013eaebcf998078edf1621e4433534f8d8b11 192.168.56.72:6386 192.168.56.72:6379
其中:
--slave:表示添加的是一个从节点
--master-id:表示该从节点的主节点
192.168.56.72:6386:新添加的从节点
192.168.56.72:6379:是集群中,任一个旧节点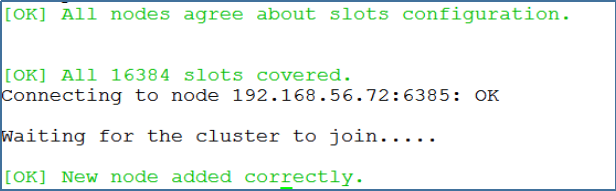
⑦ 重新检查集群的状态信息
bin/redis-trib.rb check 192.168.56.72:6379
⑧ 重新分配slot
bin/redis-trib.rb reshard 192.168.56.72:6379
⑨ 重新查看集群的节点槽的信息,可以看到新添加的节点信息。
cluster slots
或者使用:
bin/redis-trib.rb check 192.168.56.72:6379
删除节点
① 先删除从节点:
bin/redis-trib.rb del-node 192.168.56.72:6385 21e3e82610ce206708aa8f4189e2c9b2f3d1c540
② 再删除主节点
bin/redis-trib.rb del-node 192.168.56.72:6386 f757ce35102b3aaff3621b539e2dc675eafe3c01
③ 如果出现以下错误,需要先清空(移动)该节点上的slot,再删除
第一步:bin/redis-trib.rb reshard 192.168.56.72:6386
第二步:bin/redis-trib.rb del-node 192.168.56.72:6386 f757ce35102b3aaff3621b539e2dc675eafe3c01
④ 重新检查集群的信息,发生节点已经被删除
bin/redis-trib.rb check 192.168.56.72:6379
8.Redis Cluster节点的失败迁移
① 首先,为了看到演示的效果,清除一下之前的设置,还是以六个节点为例
② 启动每个节点,并创建集群
bin/redis-server conf/redis6379.conf
bin/redis-server conf/redis6380.conf
bin/redis-server conf/redis6381.conf
bin/redis-server conf/redis6382.conf
bin/redis-server conf/redis6383.conf
bin/redis-server conf/redis6384.conf
bin/redis-trib.rb create --replicas 1 192.168.56.72:6379 192.168.56.72:6380 192.168.56.72:6381 192.168.56.72:6382 192.168.56.72:6383 192.168.56.72:6384
③ 检查集群状态
bin/redis-trib.rb check 192.168.56.72:6379
④ 杀掉6379上的主节点,并重新检查集群的状态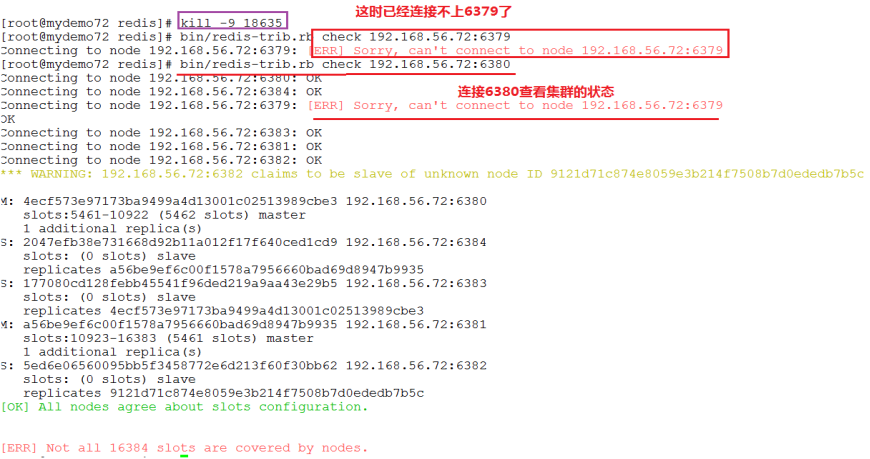
⑤ 稍等一段时间,重新检查集群的状态
⑥ 如果重新启动6379上的实例,它将变成6382的从节点

