
Kafka 分布式发布-订阅消息系统
1. Kafka 概述
1.1什么是 Kafka
Apache Kafka 是分布式发布-订阅消息系统(消息中间件)。它最初由 LinkedIn 公司开发,之后成为 Apache 项目的一部分。Kafka 是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
简单说明什么是Kafka:
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100 个鸡蛋,消费者1 秒钟只能吃50 个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们
放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”Kafka“。鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是Kafka 的扩容。Kafka 就是例子中的"篮子"。
传统消息中间件服务 RabbitMQ、Apache ActiveMQ 等。
Apache Kafka 与传统消息系统相比,有以下不同:
1.它是分布式系统,易于向外扩展;
2.它同时为发布和订阅提供高吞吐量;
3.它支持多订阅者,当失败时能自动平衡消费者;
4.它将消息持久化到磁盘,因此可用于批量消费,例如 ETL,以及实时应用程序。
1.2Kafka 术语
|
术语 |
解释 |
||
|
Broker |
Kafka 集群包含一个或多个服务器,这种服务器被称为 broker |
||
|
Topic |
每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物 理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处) |
||
|
Partition |
Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition. |
||
|
Producer |
负责发布消息到 Kafka broker |
||
|
Consumer |
消息消费者,向 Kafka broker 读取消息的客户端 |
||
|
Consumer Group |
每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group) |
||
|
replica |
partition 的副本,保障 partition 的高可用 |
||
|
leader |
replica 中的一个角色, producer 和 consumer 只跟 leader 交互 |
||
|
follower |
replica 中的一个角色,从 leader 中复制数据 |
||
|
controller |
Kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover |
||
小白理解:
producer:生产者,就是它来生产“鸡蛋”的。
consumer:消费者,生出的“鸡蛋”它来消费。
topic:把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的“鸡蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃”了。
broker:就是篮子了。
如果从技术角度,topic标签实际就是队列,生产者把所有“鸡蛋(消息)”都放到对应的队列里了,消费者到指定的队列里取。
2. Kafka 安装
2.1下载
Apache kafka 官方: http://kafka.apache.org/downloads.html
Scala 2.11 - kafka_2.11-0.10.2.0.tgz (asc, md5)
2.1. Kafka 集群安装
2.1.1. 安装 JDK &配置 JAVA_HOME
2.1.2. 安装 Zookeeper
参照 Zookeeper 官网搭建一个 ZK 集群, 并启动 ZK 集群。
2.1.3. 解压 Kafka 安装包
2.1.3.1. 修改配置文件 config/server.properties
vi server.properties broker.id=0 //为依次增长的:0、1、2、3、4,集群中唯一id log.dirs=/kafkaData/logs // Kafka 的消息数据存储路径zookeeper.connect=master:2181,slave1:2181,slave2:2181 //zookeeperServers 列表,各节点以逗号分开 Vi zookeeper.properties dataDir=/root/zkdata #指向你安装的zk 的数据存储目录 # 将 Kafka server.properties zookeeper.properties 文件拷贝到其他节点机器 KAFKA_HOME/config>scp server.properties zookeeper.properties xx:$PWD
2.1.3.2. 启动 Kafka
在每台节点上启动:
bin/kafka-server-start.sh -daemon config/server.properties &
2.1.3.3. 测试集群
1-进入 kafka 根目录,创建 Topic 名称为: test 的主题
bin/kafka-topics.sh --create --zookeeper hadoop:2181,hadoop001:2181,hadoop002:2181 --replication-factor 3 --partitions 3 --topic testTopic
2-列出已创建的 topic 列表
bin/kafka-topics.sh --list --zookeeper localhost:2181
3-查看 Topic 的详细信息
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
第一行是对所有分区的一个描述,然后每个分区对应一行,因为只有一个分区所以下面一行。
leader:负责处理消息的读和写,leader 是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.
在例子中,节点 1 是作为 leader 运行。
4-模拟客户端去发送消息
bin/kafka-console-producer.sh --broker-list hadoop:9092,hadoop001:9092 --topic test
5-模拟客户端去接受消息
bin/kafka-console-consumer.sh --bootstrap-server hadoop:9092 --from-beginning --topic hellotopic
6-测试一下容错能力.
Kill -9 pid[leader 节点]
另外一个节点被选做了 leader,node 1 不再出现在 in-sync 副本列表中: bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
虽然最初负责续写消息的 leader down 掉了,但之前的消息还是可以消费的:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic test
3. Kafka 客户端开发
3.1. Java Client
3.1.1. 添加 pom.xml 依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.2.1</version> </dependency>
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.2.1</version> </dependency>
3.1.2. Producer 生产者


import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; /** * kafka 生产端Api开发 */ public class ProducerApi { public static void main(String[] args) throws Exception{ Properties props = new Properties(); props.setProperty("bootstrap.servers","hadoop:9092,hadoop001:9092,hadoop002:9092"); props.setProperty("key.serializer",StringSerializer.class.getName()); props.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); /** * 发送数据的时候是否需要应答 * 取值范围: * [all,-1,0,1] * 0:leader不做任何应答 * 1:leader会给producer做出应答 * all、-1:fllower->leader->producer * 默认值: 1 */ //props.setProperty("acks","1") /** * 自定义分区 * 默认值:org.apache.kafaka.clients.producer.internals.DefaultPartitoner */ //props.setProperty("partitioner.class","org.apache.kafaka.clients.producer.internals.DefaultPartitoner"); //创建一个生产者的客户端实例 KafkaProducer<Object, Object> kafkaproducer = new KafkaProducer<>(props); int count=0; while (count<1000){ int partitionNum=count%3; //封装一条消息 ProducerRecord record = new ProducerRecord("testTopic", partitionNum, "", count+""); //发送一条消息 kafkaproducer.send(record); count++; Thread.sleep(1*1000); } //释放 kafkaproducer.close(); } }
3.1.3. Consumer 消费者
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.util.Arrays; import java.util.HashMap; import java.util.Iterator; import java.util.Properties; /** * 消费端Api开发 */ public class ConsumerApi { public static void main(String[] args) { Properties config = new Properties(); HashMap<String, Object> props = new HashMap<>(); config.put("bootstrap.servers","hadoop:9092,hadoop001:9092,hadoop002:9092"); config.put("key.deserializer",StringDeserializer.class.getName()); config.put("value.deserializer",StringDeserializer.class.getName()); config.put("group.id","day12_001"); /** * 从哪个位置开始获取数据 * 取值范围: * [latest,earliest,none] * 默认值: * latest */ config.put("auto.offset.reset","earliest"); /** * 是否要自动递交偏移量(offset)这条数据在某个分区所在位置的编号 */ config.put("enable.auto.commit",true); /** * 设置500毫秒递交一次offset值 */ config.put("auto.commit.interval.ms",500); //创建一个客户端实例 KafkaConsumer<Object, Object> kafkaConsumer = new KafkaConsumer<>(config); //订阅主题 kafkaConsumer.subscribe(Arrays.asList("testTopic")); while (true){ //拉取数据,会从kafka所以分区下拉取数据 ConsumerRecords<Object, Object> records = kafkaConsumer.poll(2000); Iterator<ConsumerRecord<Object, Object>> iterator = records.iterator(); while (iterator.hasNext()){ ConsumerRecord<Object, Object> record = iterator.next(); System.out.println("record"+record); } } } }
4. Kafka 原理
4.1. Kafka 的拓扑结构
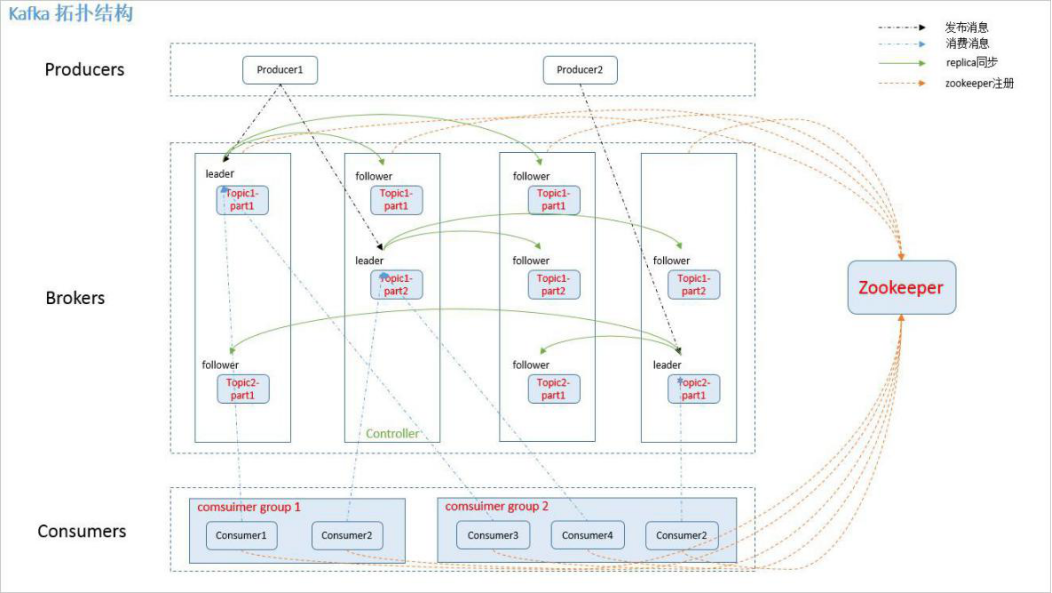
如上图所示,一个典型的 Kafka 集群中包含若干 Producer,若干 broker(Kafka 支持水平扩展, 一般 broker 数量越多,集群吞吐率越高),若干 Consumer Group,以及一个 Zookeeper 集群。Kafka 通过 Zookeeper 管理集群配置,选举 leader。Producer 使用 push 模式将消息发布到 broker,Consumer 使用 pull 模式从 broker 订阅并消费消息。
4.2. Zookeeper 节点
4.3. Producer 发布消息
- producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 partition
中,属于顺序写磁盘。
主题是发布记录的类别或订阅源名称。Kafka的主题总是多用户; 也就是说,一个主题可以有零个,一个或多个消费者订阅写入它的数据。
对于每个主题,Kafka群集都维护一个如下所示的分区日志:

- producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。
1.指定了 partition,则直接使用;
2.未指定 partition 但指定 key,通过对 key 的 value 进行 hash 选出一个 partition
3.partition 和 key 都未指定,使用轮询选出一个 partition 。
4.3.1. 写数据流程

- producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR(in-sync replicas) 中的 replica 的 ACK 后向 producer 发送 ACK
4.4. Broker 存储消息
4.4.1. 消息存储方式
物理上把 topic 分成一个或多个 partition(对应 server.properties 中的 num.partitions=3 配置),每个 partition 物理上对应一个文件夹(该文件夹存储该 partition 的所有消息和索引文件),如下:
4.4.2. 消息存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
log.retention.hours=168 #基于时间
log.retention.bytes=1073741824 #基于大小
4.5. Kafka log 的存储解析
Partition 中的每条 Message 由 offset 来表示它在这个 partition 中的偏移量,这个 offset 不是该 Message 在 partition 数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了
partition 中的一条 Message。因此,可以认为 offset 是 partition 中 Message 的 id。partition
中的每条 Message 包含了以下三个属性:
offset
MessageSize
data
其中 offset 为 long 型,MessageSize 为 int32,表示 data 有多大,data 为 message 的具体内容。
我们来思考一下,如果一个partition 只有一个数据文件会怎么样?
1) 新数据是添加在文件末尾,不论文件数据文件有多大,这个操作永远都是高效的。
2) 查找某个offset 的Message是顺序查找的。因此,如果数据文件很大的话,查找的效率就低。
那 Kafka 是如何解决查找效率的的问题呢?有两大法宝:1) 分段 2) 索引。
Ø 数据文件的分段
Kafka 解决查询效率的手段之一是将数据文件分段,比如有 100 条 Message,它们的 offset 是从 0 到 99。假设将数据文件分成 5 段,第一段为 0-19,第二段为 20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中最小的 offset 命名。这样在查找指定 offset 的 Message 的时候,用二分查找就可以定位到该 Message 在哪个段中。
Ø 为数据文件建索引
数据文件分段使得可以在一个较小的数据文件中查找对应 offset 的 Message 了,但是这依然需要顺序扫描才能找到对应 offset 的 Message。为了进一步提高查找的效率,Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条 Message 的索引。索引包含两个部分,分别为相对 offset 和 position。
1.相对 offset:因为数据文件分段以后,每个数据文件的起始 offset 不为 0,相对 offset 表示这条 Message 相对于其所属数据文件中最小的 offset 的大小。举例,分段后的一个数据文件的 offset 是从 20 开始,那么 offset 为 25 的 Message 在 index 文件中的相对 offset 就是 25-20 = 5。存储相对 offset 可以减小索引文件占用的空间。
2.position,表示该条 Message 在数据文件中的绝对位置。只要打开文件并移动文件指针到这个 position 就可以读取对应的 Message 了。
index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存储的方式, 每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引 文件保留在内存中。但缺点是没有建立索引的 Message 也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
我们以几张图来总结一下 Message 是如何在 Kafka 中存储的,以及如何查找指定 offset 的Message 的。
Message 是按照 topic 来组织,每个 topic 可以分成多个的 partition,比如:有 5 个 partition的名为为 page_visits 的 topic 的目录结构为:
partition 是分段的,每个段叫 Segment,包括了一个数据文件和一个索引文件,下图是某个partition 目录下的文件:
可以看到,这个 partition 有 4 个 Segment。图示 Kafka 是如何查找 Message 的。

比如:要查找绝对 offset 为 7 的 Message:
首先是用二分查找确定它是在哪个 LogSegment 中,自然是在第一个 Segment 中。
打开这个 Segment 的 index 文件,也是用二分查找找到 offset 小于或者等于指定 offset 的索引条目中最大的那个 offset。自然 offset 为 6 的那个索引是我们要找的,通过索引文件我们知道 offset 为 6 的 Message 在数据文件中的位置为 9807。
打开数据文件,从位置为9807 的那个地方开始顺序扫描直到找到offset 为7 的那条Message。这套机制是建立在 offset 是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
一句话,Kafka 的 Message 存储采用了分区(partition),分段(LogSegment)和稀疏索引这几个手段来达到了高效性。

