Spark学习之scala编程
一、Scala语言基础
1、Scala语言简介
Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。
学习Scala编程语言,为后续学习Spark奠定基础。

2、为什么要学Scala
l 优雅:这是框架设计师第一个要考虑的问题,框架的用户是应用开发程序员,API是否优雅直接影响用户体验。
l 速度快:Scala语言表达能力强,一行代码抵得上Java多行,开发速度快;Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多。
l 能融合到Hadoop生态圈:Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。JVM语言大部分可能会想到Java,但Java做出来的API太丑,或者想实现一个优雅的API太费劲。

l 德国的一位资深Java专家Adam Bien在参加JavaOne 2008大会(他在会上有一个技术讲座)期间,亲耳听到,有人问Java之父James Gosling“除了Java之外,你现在最希望在JVM上使用什么语言?”的时候,他出人意料的回答:“Scala!”几乎是脱口而出。

3、安装JDK
因为Scala是运行在JVM平台上的,所以安装Scala之前要安装JDK,安装JDK1.8版本
4、下载和安装Scala
① Windows安装Scala编译器
访问Scala官网http://www.scala-lang.org/下载Scala编译器安装包,目前最新版本是2.12.x,但是目前大多数的框架都是用2.11.x编写开发的,Spark2.x使用的就是2.11.x,所以这里推荐2.11.x版本,下载scala-2.11.12.msi后点击下一步就可以了
1) 安装JDK
2) 下载Scala:http://www.scala-lang.org/download/
3) 安装Scala:
设置环境变量:SCALA_HOME和PATH路径
4) 验证Scala
② Linux安装Scala编译器
下载Scala地址http://downloads.typesafe.com/scala/2.11.12/scala-2.11.12.tgz然后解压Scala到指定目录
tar -zxvf scala-2.11.12.tgz -C /usr/java
配置环境变量,将scala加入到PATH中
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin:/usr/java/scala-2.11.12/bin
5、Scala的运行环境
l REPL(Read Evaluate Print Loop):命令行
l IDE:图形开发工具
n The Scala IDE (Based on Eclipse):http://scala-ide.org/
n IntelliJ IDEA with Scala plugin:http://www.jetbrains.com/idea/download/
n Netbeans IDE with the Scala plugin
6、Scala开发工具安装(IDEA)
由于IDEA的Scala插件更优秀,大多数Scala程序员都选择IDEA,可以到http://www.jetbrains.com/idea/download/下载社区免费版,点击下一步安装即可,安装时如果有网络可以选择在线安装Scala插件。这里我们使用离线安装Scala插件:
l 安装IDEA,点击下一步即可。由于我们离线安装插件,所以点击Skip All and Set Defaul
l 下载IEDA的scala插件,地址http://plugins.jetbrains.com/plugin/1347-scala
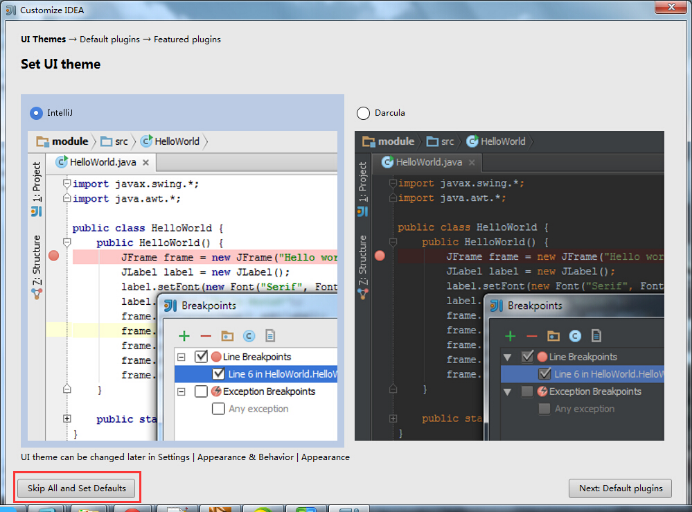
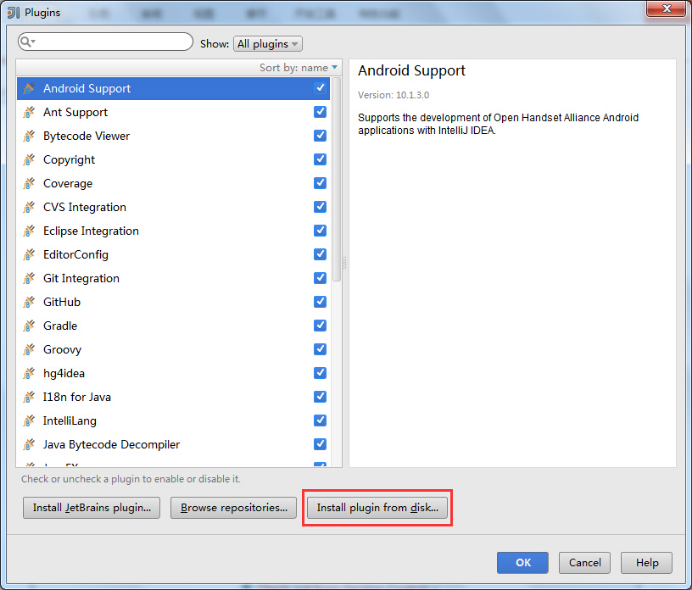
1.安装Scala插件:Configure -> Plugins -> Install plugin from disk -> 选择Scala插件 -> OK -> 重启IDEA


7、Scala的常用数据类型
注意:在Scala中,任何数据都是对象。例如:

③ 数值类型:Byte,Short,Int,Long,Float,Double
l Byte: 8位有符号数字,从-128 到 127
l Short: 16位有符号数据,从-32768 到 32767
l Int: 32位有符号数据
l Long: 64位有符号数据
例如:
val a:Byte = 10
a+10
得到:res9: Int = 20
这里的res9是新生成变量的名字
val b:Short = 20
a+b
注意:在Scala中,定义变量可以不指定类型,因为Scala会进行类型的自动推导。
④ 字符类型和字符串类型:Char和String
对于字符串,在Scala中可以进行插值操作。

注意:前面有个s;相当于执行:"My Name is " + s1
⑤ Unit类型:相当于Java中的void类型
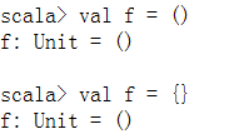
⑥ Nothing类型:一般表示在执行过程中,产生了Exception
例如,我们定义一个函数如下:
8、Scala变量的申明和使用
l 使用val和var申明变量
例如:scala> val answer = 8 * 3 + 2
可以在后续表达式中使用这些名称
l val:value 简写,表示的意思为值,不可变
要申明其值可变的变量:val
l var:variable 简写,表示的变量,可以改变值
要申明其值不可变的变量:var
l 例子
|
//变量名在前,类型在后
|
注意:可以不用显式指定变量的类型,Scala会进行自动的类型推到
9、Scala的条件表达式
Scala的if/else语法结构和Java或C++一样。
不过,在Scala中,if/else是表达式,有值,这个值就是跟在if或else之后的表达式的值。
- Scala的的条件表达式比较简洁,例如:
|
|
10、块表达式
|
|
11、Scala的循环
Scala拥有与Java和C++相同的while和do循环
Scala中,可以使用for和foreach进行迭代
- 使用for循环案例:
![]()

注意:
(*) <- 表示Scala中的generator,即:提取符
(*)第三种写法是第二种写法的简写
- 在for循环中,还可以使用yield关键字来产生一个新的集合
![]()

在上面的案例中,我们将list集合中的每个元素转换成了大写,并且使用yield关键字生成了一个新的集合。
- 使用while循环:注意使用小括号,不是中括号

- 使用do ... while循环

- 使用foreach进行迭代
![]()

注意:在上面的例子中,foreach接收了另一个函数(println)作为值
12、Scala的Lazy值(懒值)
当val被申明为lazy时,它的初始化将被推迟,直到我们首次对它取值。
一个更为复杂一点的例子:读取文件:
13、异常的处理
Scala异常的工作机制和Java或者C++一样。直接使用throw关键字抛出异常。
使用try...catch...finally来捕获和处理异常:
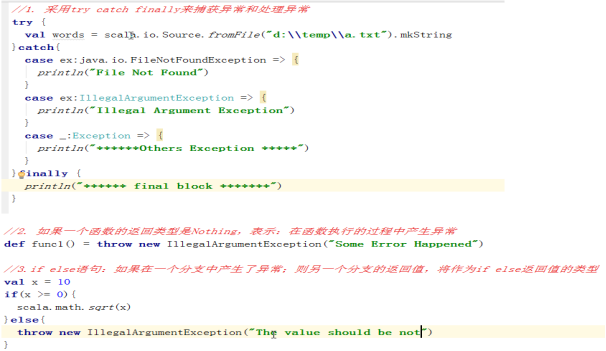
14、Scala中的数组
Scala数组的类型:
l 定长数组:使用关键字Array
l 变长数组:使用关键字ArrayBuffer

l 遍历数组
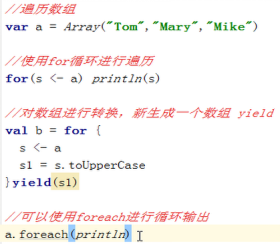
l Scala数组的常用操作
l Scala的多维数组
l 和Java一样,多维数组是通过数组的数组来实现的。
l 也可以创建不规则的数组,每一行的长度各不相同。
二、数组、映射、元组
1、 数组
① 定长数组和变长数组
|
import scala.collection.mutable.ArrayBuffer
|
② 遍历数组
- 增强for循环
- 好用的until会生成脚标,0 until 10 包含0不包含10
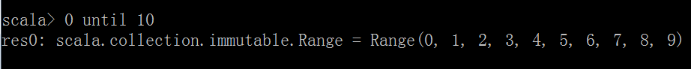
|
object ForArrayTest {
|
③ 数组转换
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变

|
|
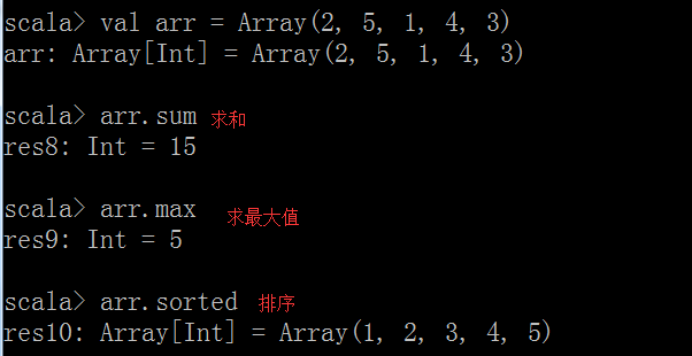
④ 数组常用算法
在Scala中,数组上的某些方法对数组进行相应的操作非常方便!
2、 映射
在Scala中,把哈希表这种数据结构叫做映射
① 构建映射

② 获取和修改映射中的值

好用的getOrElse

注意:在Scala中,有两种Map,一个是immutable包下的Map,该Map中的内容不可变;另一个是mutable包下的Map,该Map中的内容可变
例子:

注意:通常我们在创建一个集合是会用val这个关键字修饰一个变量(相当于java中的final),那么就意味着该变量的引用不可变,该引用中的内容是不是可变,取决于这个引用指向的集合的类型
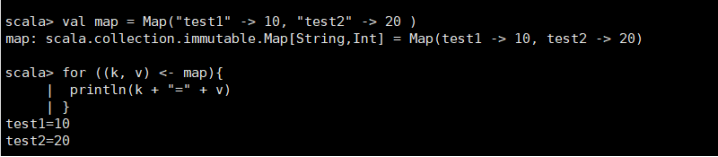
例子:如下这段超简单的循环即可遍历映射中所有的键/值对偶
3、 元组
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值。
① 创建元组

② 获取元组中的值

③ 将对偶的集合转换成映射

④ 拉链操作
zip命令可以将多个值绑定在一起
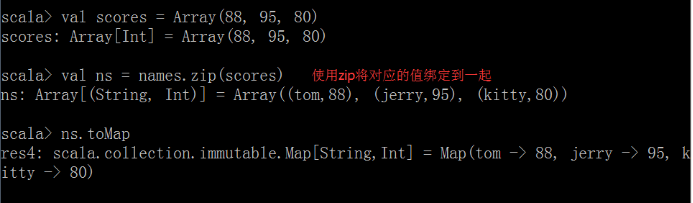
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
三、Scala语言的函数式编程
4、 调用方法和函数
Scala中的+ - * / %等操作符的作用与Java一样,位操作符 & | ^ >> <<也一样。只是有
一点特别的:这些操作符实际上是方法。例如:
a + b
是如下方法调用的简写:
a.+(b)
a 方法 b可以写成 a.方法(b)
5、 定义方法和函数
① 定义方法
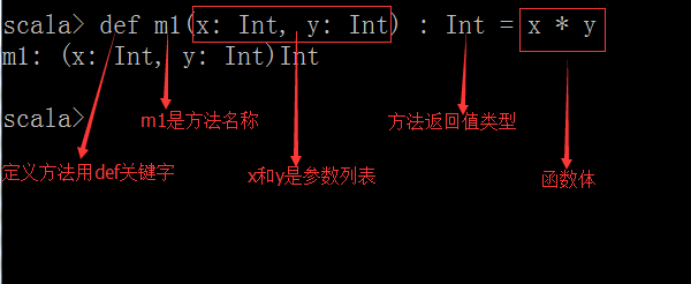
方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归方法,必须指定返回类型
② 定义函数
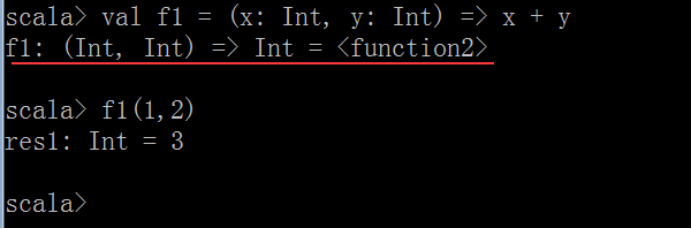
③ 方法和函数的区别
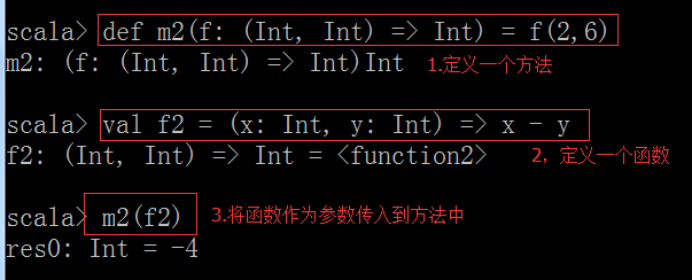
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作
案例:首先定义一个方法,再定义一个函数,然后将函数传递到方法里面
|
//返回值类型也是Int类型
|
④ 将方法转换成函数(神奇的下划线)
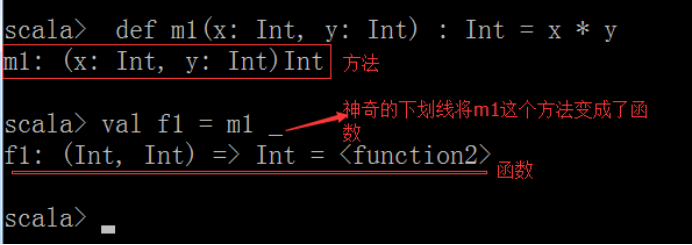
6、 Scala的函数和方法的使用
l 可以使用Scala的预定义函数
例如:求两个值的最大值

l 也可以使用def关键字自定义函数
语法:

示例:

7、 Scala函数的求值策略
- Scala中,有两种函数参数的求值策略
l Call By Value:对函数实参求值,且仅求一次
l Call By Name:函数实参每次在函数体内被用到时都会求值
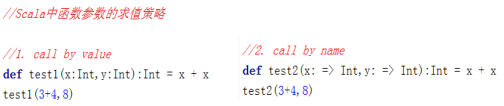
我们来分析一下,上面两个调用执行的过程:
一份复杂一点的例子:
- Scala中的函数参数
l 默认参数
l 代名参数
l 可变参数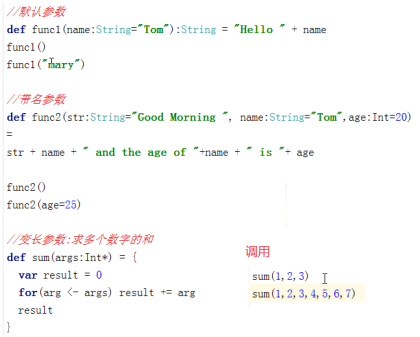
8、 Scala中的函数
在Scala中,函数是“头等公民”,就和数字一样。可以在变量中存放函数,即:将函数作为变量的值(值函数)。
9、 匿名函数
![]()
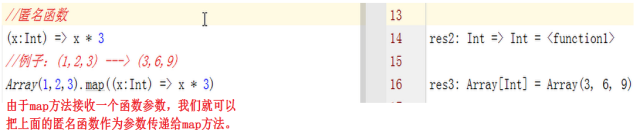
10、 带函数参数的函数,即:高阶函数
示例1:
(*)首先,定义一个最普通的函数
(*)再定义一个高阶函数

(*)分析这个高阶函数调用的过程 
示例2:
在这个例子中,首先定义了一个普通的函数mytest,然后定义了一个高阶函数myFunction;myFunction接收三个参数:第一个f是一个函数参数,第二个是x,第三个是y。而f是一个函数参数,本身接收两个Int的参数,返回一个Int的值。
11、 闭包
就是函数的嵌套,即:在一个函数定义中,包含另外一个函数的定义;并且在内函数中可以访问外函数中的变量。
测试上面的函数:
12、 柯里化:Currying
柯里化函数(Curried Function)是把具有多个参数的函数转换为一条函数链,每个节点上是单一参数。
一个简单的例子:
13、 高阶函数示例
![]()
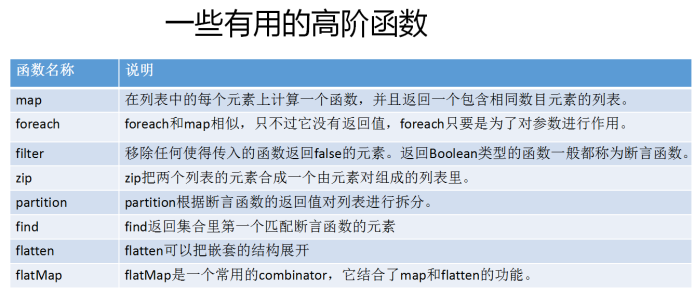
示例1:

示例2 :
示例3 :
示例4 :
示例5 :
在这个例子中,可以被2整除的被分到一个分区;不能被2整除的被分到另一个分区。
示例6 :
示例7 :
示例8 :
在这个例子中,分为两步:
(1)将(1,2,3)和(4,5,6)这两个集合合并成一个集合
(2)再对每个元素乘以2
三、Scala语言的面向对象
1、 面向对象的基本概念
把数据及对数据的操作方法放在一起,作为一个相互依存的整体——对象
面向对象的三大特征:
封装
继承
多态
2、 类的定义
简单类和无参方法:
案例:注意没有class前面没有public关键字修饰。
如果要开发main方法,需要将main方法定义在该类的伴生对象中,即:object对象中,(后续做详细的讨论)。
3、 属性的getter和setter方法
l 当定义属性是private时候,scala会自动为其生成对应的get和set方法
private var stuName:String = "Tom"
- get方法: stuName ----> s2.stuName() 由于stuName是方法的名字,所以可以加上一个括号
- set方法: stuName_= ----> stuName_= 是方法的名字
l 定义属性:private var money:Int = 1000 希望money只有get方法,没有set方法??
- 办法:将其定义为常量private val money:Int = 1000
l private[this]的用法:该属性只属于该对象私有,就不会生成对应的set和get方法。如果这样,就不能直接调用,例如:s1.stuName ---> 错误
4、 内部类(嵌套类)
我们可以在一个类的内部在定义一个类,如下:我们在Student类中,再定义了一个Course类用于保存学生选修的课程。
开发一个测试程序进行测试:
5、 类的构造器
类的构造器分为:主构造器、辅助构造器
l 主构造器:和类的声明结合在一起,只能有一个主构造器
Student4(val stuName:String,val stuAge:Int)
(1) 定义类的主构造器:两个参数
(2) 声明了两个属性:stuName和stuAge 和对应的get和set方法
l 辅助构造器:可以有多个辅助构造器,通过关键字this来实现
6、 Scala中的Object对象
Scala没有静态的修饰符,但Object对象下的成员都是静态的 ,若有同名的class,这其作为它的伴生类。在Object中一般可以为伴生类做一些初始化等操作。
下面是Java中的静态块的例子。在这个例子中,我们对JDBC进行了初始化。
而Scala中的Object就相当于Java中静态块。
Object对象的应用
单例对象
使用应用程序对象:可以省略main方法;需要从父类App继承。
7、 Scala中的apply方法
遇到如下形式的表达式时,apply方法就会被调用:
Object(参数1,参数2,......,参数N)
通常,这样一个apply方法返回的是伴生类的对象;其作用是为了省略new 关键字
Object的apply方法举例:
8、 Scala中的继承
Scala和Java一样,使用extends关键字扩展类。
l 案例一:Employee类继承Person类
l 案例二:在子类中重写父类的方法
l 案例三:使用匿名子类
l 案例四:使用抽象类。抽象类中包含抽象方法,抽象类只能用来继承。
l 案例五:使用抽象字段。抽象字段就是一个没有初始值的字段
9、 Scala中的trait(特质)
trait就是抽象类。trait跟抽象类最大的区别:trait支持多重继承

10、 包的使用
Scala的包和Java中的包或者C++中的命名空间的目的是相同的:管理大型程序中的名称。

Scala中包的定义和使用:
包的定义
包的引入:Scala中依然使用import作为引用包的关键字,例如
而且Scala中的import可以写在任意地方

11、 包对象
包可以包含类、对象和特质,但不能包含函数或者变量的定义。很不幸,这是Java虚拟机的局限。
把工具函数或者常量添加到包而不是某个Utils对象,这是更加合理的做法。Scala中,包对象的出现正是为了解决这个局限。
Scala中的包对象:常量,变量,方法,类,对象,trait(特质)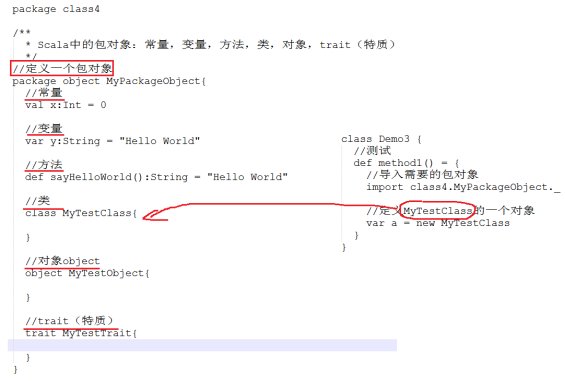
12、 Scala中的文件访问
l 读取行
l 读取字符
其实这里的source就指向了这个文件中的每个字符。
l 从URL或其他源读取:注意指定字符集UTF-8

l 读取二进制文件:Scala中并不支持直接读取二进制,但可以通过调用Java的InputStream来进行读入。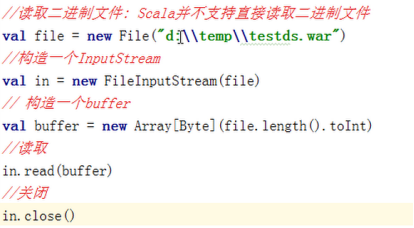
l 写入文本文件
四、Scala中的集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质
在Scala中集合有可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后就不能改变了(注意与val修饰的变量进行区别)
1、 可变集合和不可变集合
l 可变集合
l 不可变集合:
集合从不改变,因此可以安全地共享其引用。
甚至是在一个多线程的应用程序当中也没问题。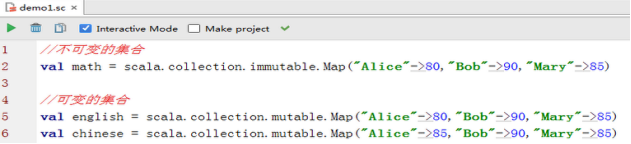
集合的操作:
2、 列表
l 不可变列表(List)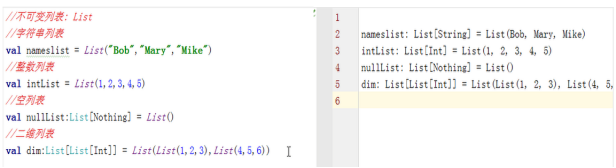
不可变列表的相关操作:
l 可变列表(LinkedList):scala.collection.mutable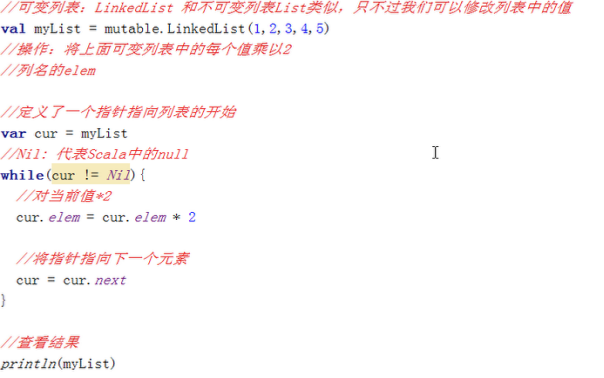
3、 序列
常用的序列有:Vector和Range
Vector是ArrayBuffer的不可变版本,是一个带下标的序列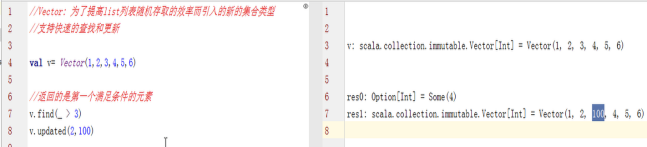
Range表示一个整数序列

4、 集(Set)和集的操作
l 集Set是不重复元素的集合
l 和列表不同,集并不保留元素插入的顺序。默认以Hash集实现
示例1:创建集
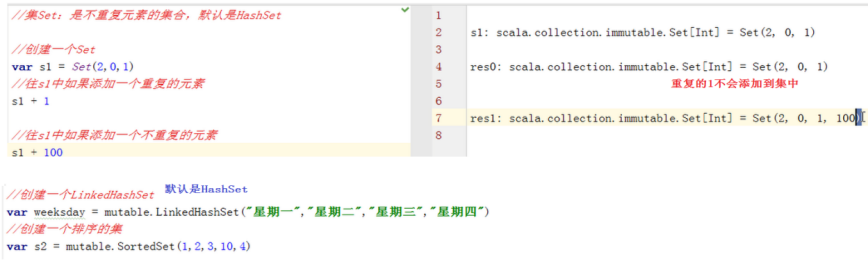
示例2 :集的操作
5、 模式匹配
Scala有一个强大的模式匹配机制,可以应用在很多场合:
switch语句
类型检查
Scala还提供了样本类(case class),对模式匹配进行了优化
模式匹配示例:
l 更好的switch
l Scala的守卫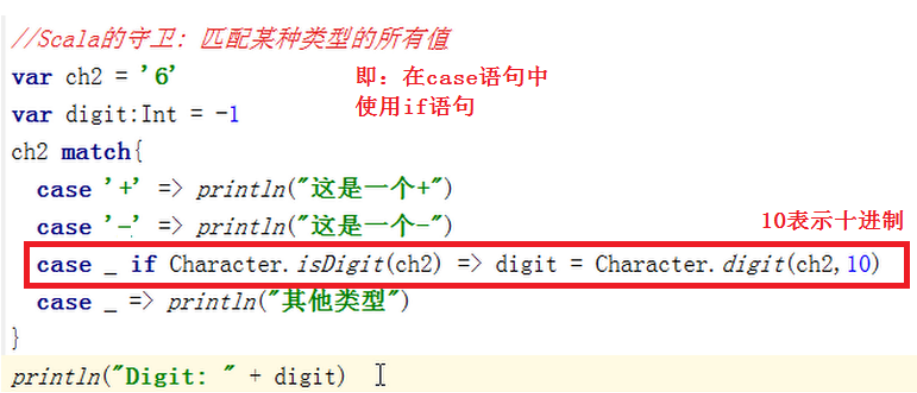
l 模式匹配中的变量
l 类型模式
l 匹配数组和列表
6、 样本类(CaseClass)
简单的来说,Scala的case class就是在普通的类定义前加case这个关键字,然后你可以对这些类来模式匹配。
case class带来的最大的好处是它们支持模式识别。
首先,回顾一下前面的模式匹配:
其次,如果我们想判断一个对象是否是某个类的对象,跟Java一样可以使用isInstanceOf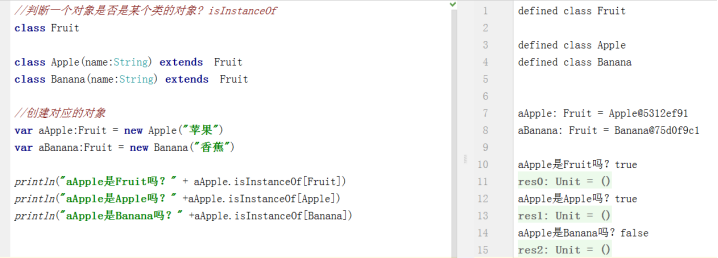
最后,在Scala中有一种更简单的方式来判断,就是case class
注意:需要在class前面使用case关键字。
五、Scala语言的高级特性
1、 什么是泛型类
和Java或者C++一样,类和特质可以带类型参数。在Scala中,使用方括号来定义类型参数
测试程序:
2、 什么是泛型函数
函数和方法也可以带类型参数。和泛型类一样,我们需要把类型参数放在方法名之后。
注意:这里的ClassTag是必须的,表示运行时的一些信息,比如类型。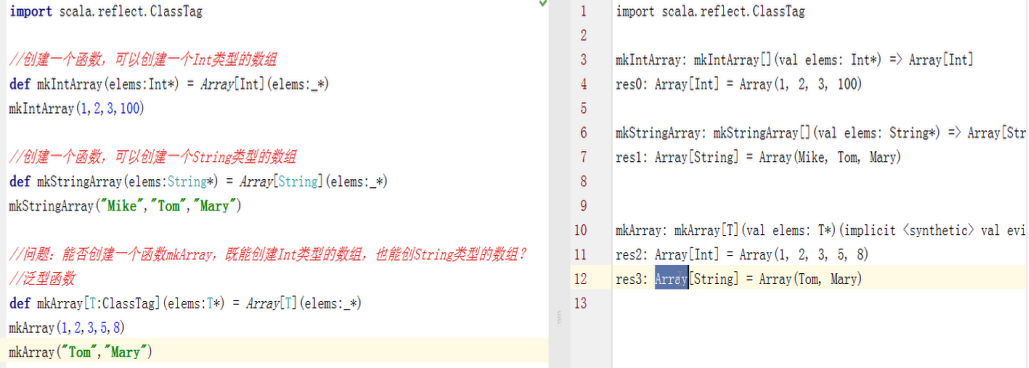
3、 Upper Bounds 与 Lower Bounds
类型的上界和下界,是用来定义类型变量的范围。它们的含义如下:
S <: T
这是类型上界的定义。也就是S必须是类型T的子类(或本身,自己也可以认为是自己的子类。
U >: T
这是类型下界的定义。也就是U必须是类型T的父类(或本身,自己也可以认为是自己的父类)。
l 一个简单的例子:
l 一个复杂一点的例子(上界):
l 再来看一个例子:
4、 视图界定(View bounds)
它比 <: 适用的范围更广,除了所有的子类型,还允许隐式转换过去的类型。用 <% 表示。尽量使用视图界定,来取代泛型的上界,因为适用的范围更加广泛。
示例:
l 上面写过的一个列子。这里由于T的上界是String,当我们传递100和200的时候,就会出现类型不匹配。
l 但是100和200是可以转成字符串的,所以我们可以使用视图界定让addTwoString方法接收更广泛的数据类型,即:字符串及其子类、可以转换成字符串的类型。
注意:使用的是 <% 
l 但实际运行的时候,会出现错误:
这是因为:Scala并没有定义如何将Int转换成String的规则,所以要使用视图界定,我们就必须创建转换的规则。
l 创建转换规则
l 运行成功
5、 协变和逆变
l 协变:
Scala的类或特征的范型定义中,如果在类型参数前面加入+符号,就可以使类或特征变为协变了。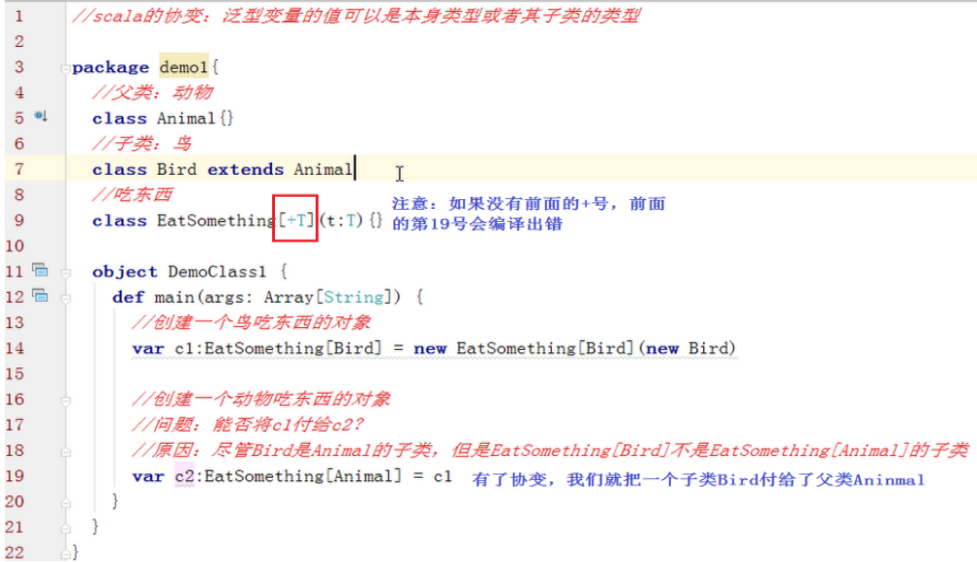
逆变:
在类或特征的定义中,在类型参数之前加上一个-符号,就可定义逆变范型类和特征了。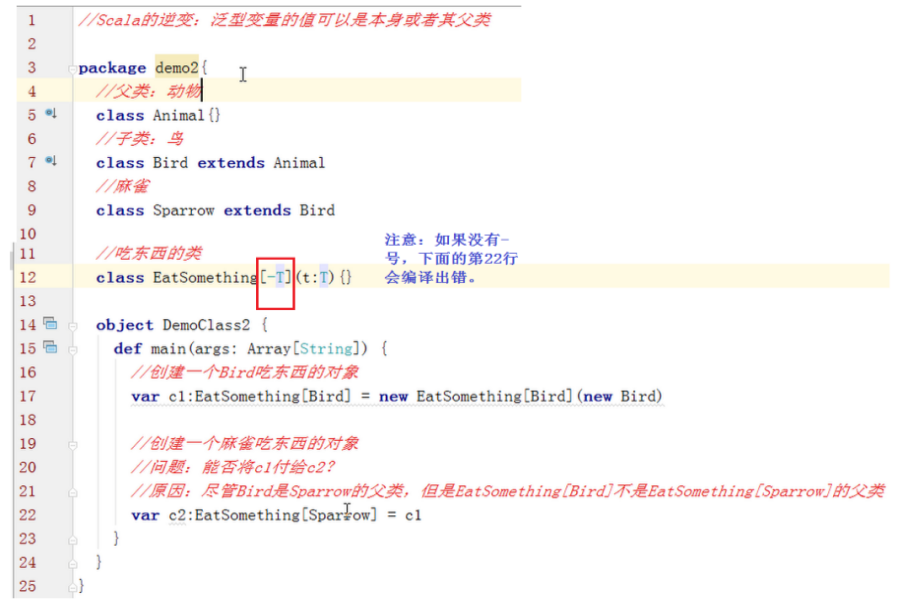
总结一下:Scala的协变:泛型变量的值可以是本身类型或者其子类的类型
Scala的逆变:泛型变量的值可以是本身类型或者其父类的类型
6、 隐式转换函数
所谓隐式转换函数指的是以implicit关键字申明的带有单个参数的函数。
l 前面讲视图界定时候的一个例子:
l 再举一个例子:我们把Fruit对象转换成了Monkey对象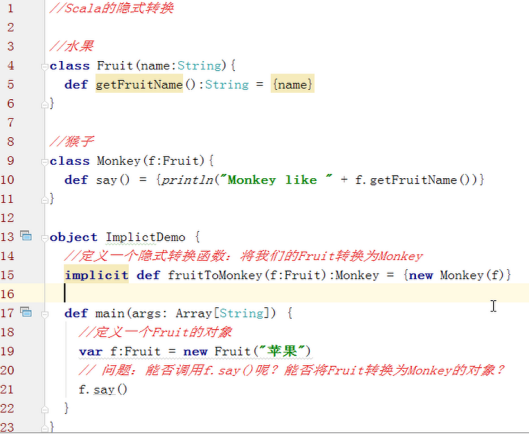
7、 隐式参数
使用implicit申明的函数参数叫做隐式参数。我们也可以使用隐式参数实现隐式的转换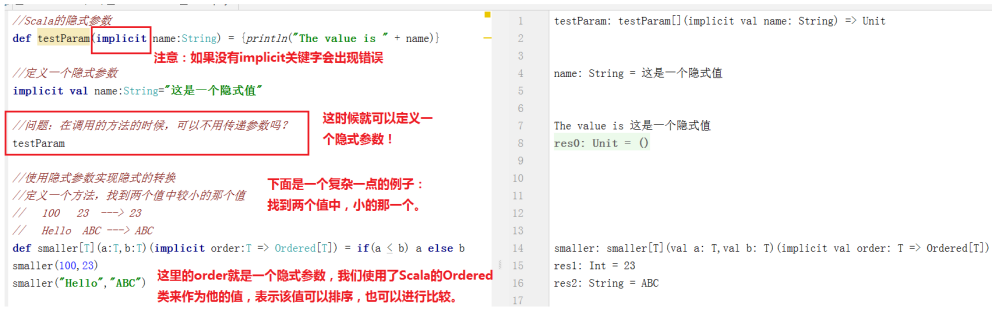
8、 隐式类
所谓隐式类: 就是对类增加implicit 限定的类,其作用主要是对类的功能加强!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号