基于zookeeper实现分布式锁
1.什么是分布式锁
要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。
(1)线程锁:主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
(2)进程锁:为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
(3)分布式锁:当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
一、分布式锁应该具备哪些条件
1.在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2.高可用的获取锁与释放锁;
3.高性能的获取锁与释放锁;
4.具备可重入特性;
5.具备锁失效机制,防止死锁;
6.具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
二、分布式实现方法(三种)
1.基于数据库实现分布式锁;
2.基于缓存(Redis等)实现分布式锁;
3.基于Zookeeper实现分布式锁;
三、三种分布式的区别(理解难易程度、实现程度、性能、可靠性)
1.从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
2.从实现的复杂性角度(从低到高)
Zookeeper >= 缓存 > 数据库
3.从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
4.从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
四、Zookeeper分布式锁实现
1.原理
ZooKeeper核心是一个精简的文件系统,它提供了一些简单的文件操作以及附加的功能 ,它的数据结构原型是一棵znode树(类似Linux的文件系统),并且它们是一些已经被构建好的块,可以用来构建大型的协作数据结构和协议 。
2.每个锁都需要一个路径来指定(如:/lqq/lock)
(1)根据指定的路径, 查找zookeeper集群下的这个节点是否存在.(说明已经有锁了)
(2)如果存在, 根据查询者的一些特征数据(如ip地址/hostname), 当前的锁是不是查询者的
(3)如果不是查询者的锁, 则返回null, 说明创建锁失败
(4)如果是查询者的锁, 则把这个锁返回给查询者
(5)如果这个节点不存在, 说明当前没有锁, 那么创建一个临时节点, 并将查询者的特征信息写入这个节点的数据中, 然后返回这个锁.
据以上5部, 一个分布式的锁就可以创建了.
3.创建的锁有三种状态:
(1)创建失败(null), 说明该锁被其他查询者使用了.
(2)创建成功, 但当前没有锁住(unlocked), 可以使用
(3)创建成功, 但当前已经锁住(locked)了, 不能继续加锁.
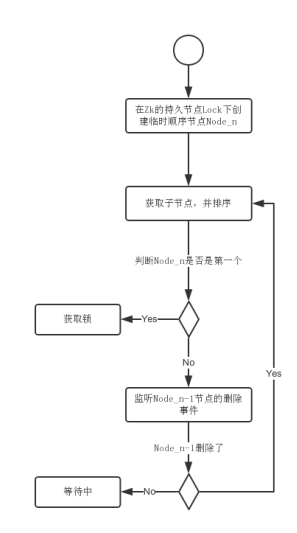
4.Zookeeper的分布式锁流程分析
总体思路可以如下:
(1)获取分布式锁时在Lock节点下创建临时顺序节点,释放锁的时候删除该临时节点。
(2)客户端调用createNode方法在Lock节点下创建临时顺序节点。然后调用getChildren获取所有子节点。
如果发现当前自己创建的节点的序号是最小的话,就认定该客户端获取到锁。
如果发现不是最小的节点。说明获取锁失败,此时客户端需要找到比自己小的节点,对其注册事件监听器。
(3)当前获取到锁的客户端删除当前最小节点,那么注册过事件监听器的客户端会收到通知,此时再次判断是否自己的节点是最小的,是的话直接获取到锁,不是的话重复步骤监听比自己小的节点的事件。
1.Zookeeper的分布式锁流程图: