pytorch入门--土堆深度学习快速入门教程
工具函数
dir函数,让我们直到工具箱,以及工具箱中的分隔区有什么东西
help函数,让我们直到每个工具是如何使用的,工具的使用方法
示例:在pycharm的console环境,输入
import torch
dir(torch.cuda.is_available())
即可查看该工具包
help(torch.cuda.is_available())
DataSet
DataSet提供一种方式去获取数据及其label
DataLoader为网络提供不同数据形式
使用PIL的Image来读取图片:
from PIL import Image
img_path = "your_filename"
img = Image.open(img_path)
img.show()
此时则会打开指定的图片
创建
写自己需要的类时,需要继承Dataset,然后重写getitem方法和len方法
初始化init主要是用来写路径
getitem主要是用来获取每条数据
len方法获取数据集长度
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.listdir(self.path)
def __getitem__(self, idx):
image_name = self.image_path[idx]
image_item_path = os.path.join(self.root_dir, self.label_dir, image_name)
img = Image.open(image_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.image_path)
root_dir = "./dataset/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
if __name__ == "__main__":
img, label = ants_dataset[0]
img.show()
print(len(ants_dataset))
输出了一张图片和长度
Tensorboard
tensorboard原本是tensorflow的可视化工具,pytorch从1.2.0开始支持
安装
pip install tensorboard
tensorboard使用逻辑:
- 将代码运行过程中的,某些你关心的数据保存在一个文件夹中(由代码中的writer完成)
- 再读取这个文件夹中的数据,用浏览器显示出来(通过在命令行运行tensorboard完成)
from torch.utils.tensorboard import SummaryWriter
# 数据将以特定格式存储在logs文件夹中
writer = SummaryWriter("logs")
# writer.add_image()
# writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)
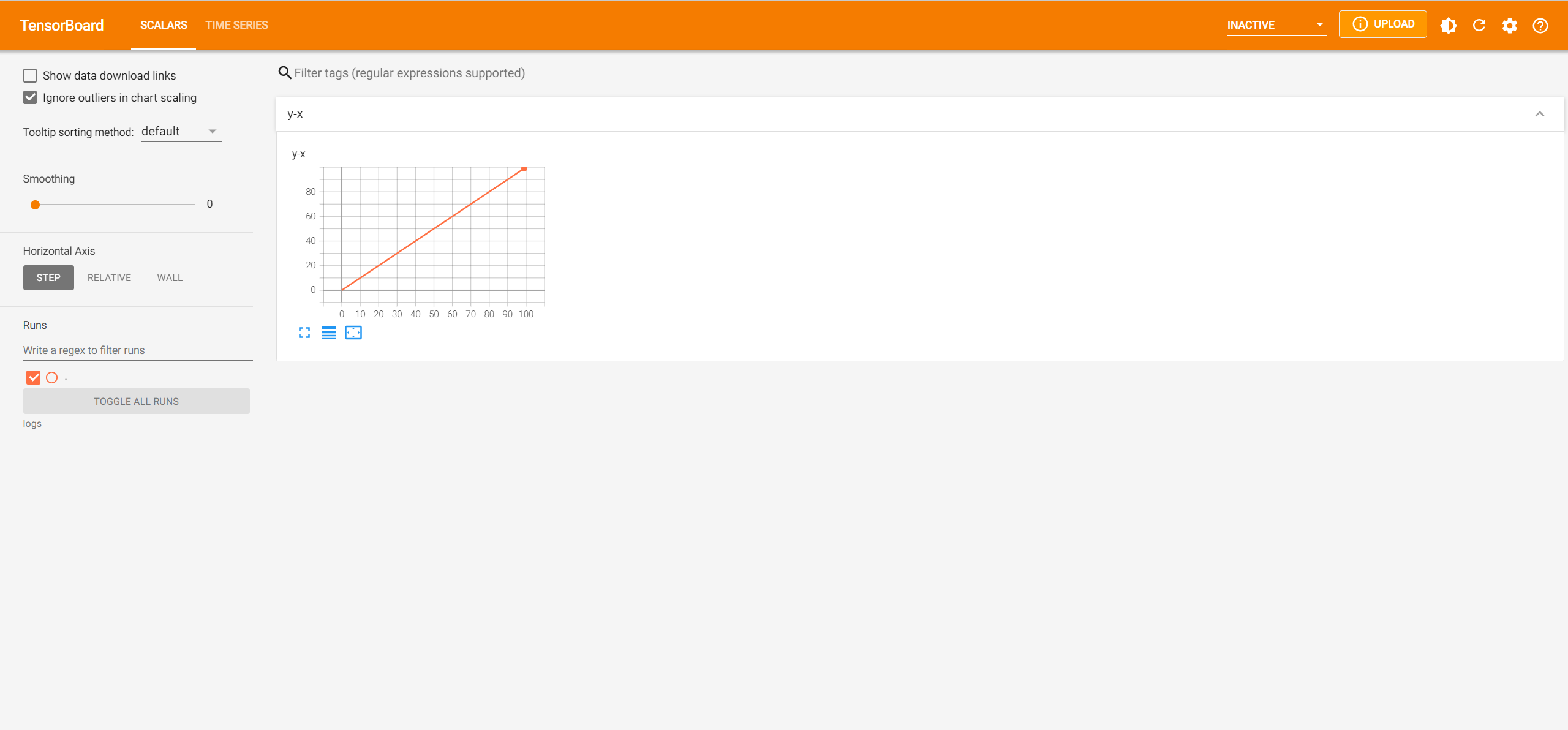
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
接下来在命令行输入:
tensorboard --logdir=logs --port=6007

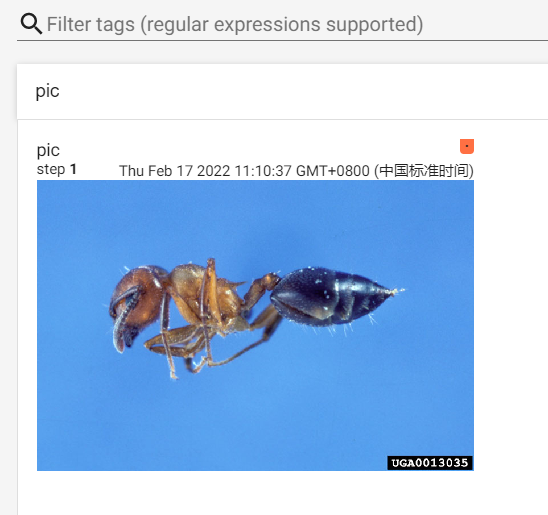
接下来读图片:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
# 数据将以特定格式存储在logs文件夹中
writer = SummaryWriter("logs")
img_PIL = Image.open(r"dataset/hymenoptera_data/train/ants/0013035.jpg")
img_array = np.array(img_PIL)
# writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
# writer.add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')
writer.add_image("test",img_array,1,dataformats="HWC")
# writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
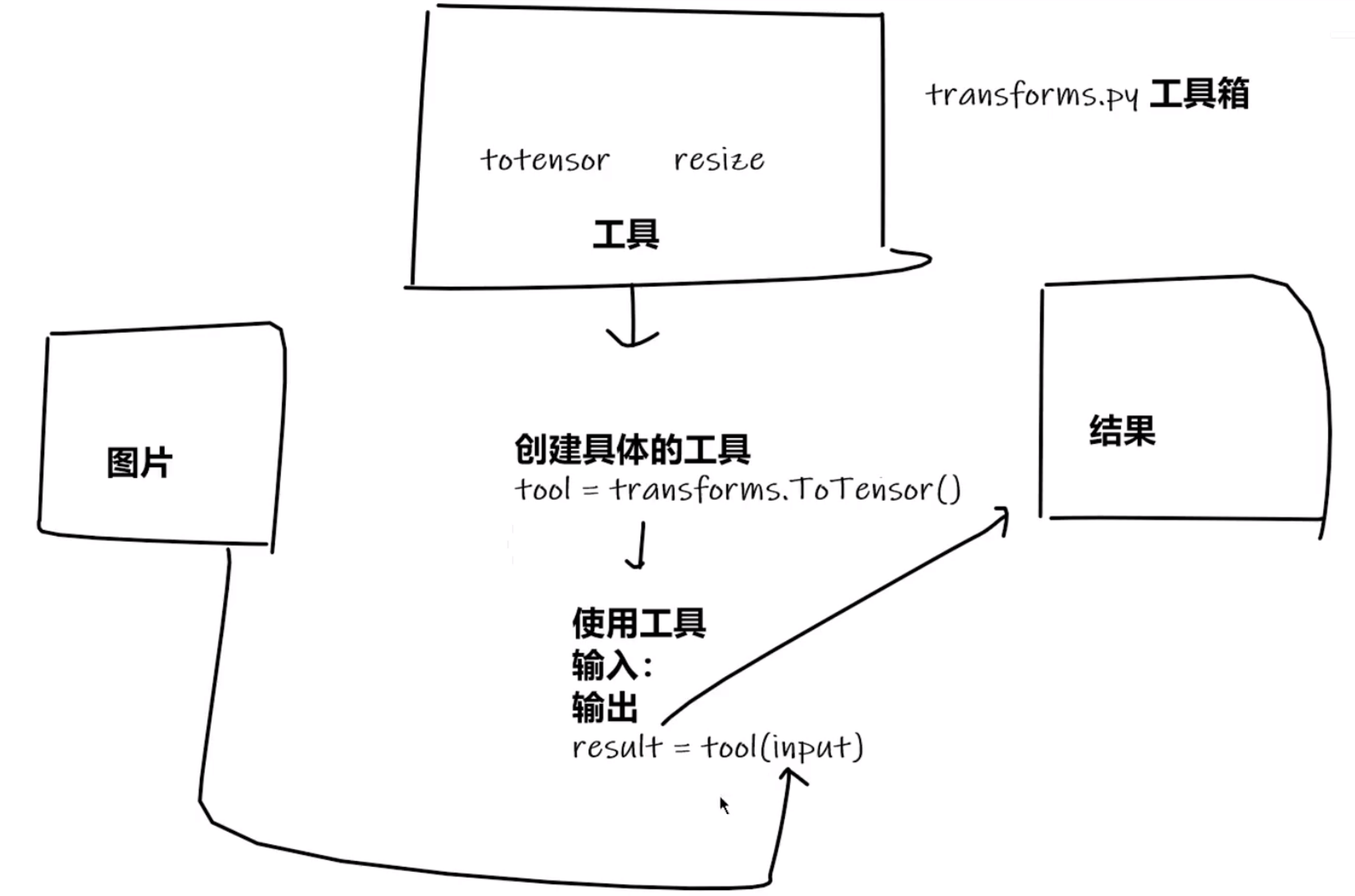
Transforms
Transforms本质上是一个数据类型转换的工具,常用于转换图片成tensor
from torchvision import transforms
from PIL import Image
image_path = "dataset/hymenoptera_data/train/ants/0013035.jpg"
trans_kit = transforms.ToTensor()
img = Image.open(image_path)
img_tensor = trans_kit(img)
print(img_tensor)
也就是说tansforms包含ToTensor在内的工具,先创建这样的类,然后直接调用即可
transforms常用函数为ToTensor、Normalize、Resize、ToPILImage
Compose函数把多个步骤整合到一起,如:
transforms.Compose([
transforms.CenterCrop(10),
transforms.ToTensor(),
])
理解魔法函数,可参见这篇文章:
class Person:
def __call__(self, name):
print("__call__"+" hello "+name)
def hello(self,name):
print(" hello "+name)
person = Person()
person("zhangsan")
person.hello("lisi")
__call__ hello zhangsan
hello lisi
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants/6240338_93729615ec.jpg")
# 首先使用ToTensor方法
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor",img_tensor)
# 然后使用Nomalize方法
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_nomalize = trans_norm(img_tensor)
writer.add_image("Nomalize",img_nomalize)
# Resize方法
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize)
# Compose
trans_resize2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize2,trans_totensor])
img_resize2 = trans_compose(img)
writer.add_image("Compose",img_resize2)
writer.close()
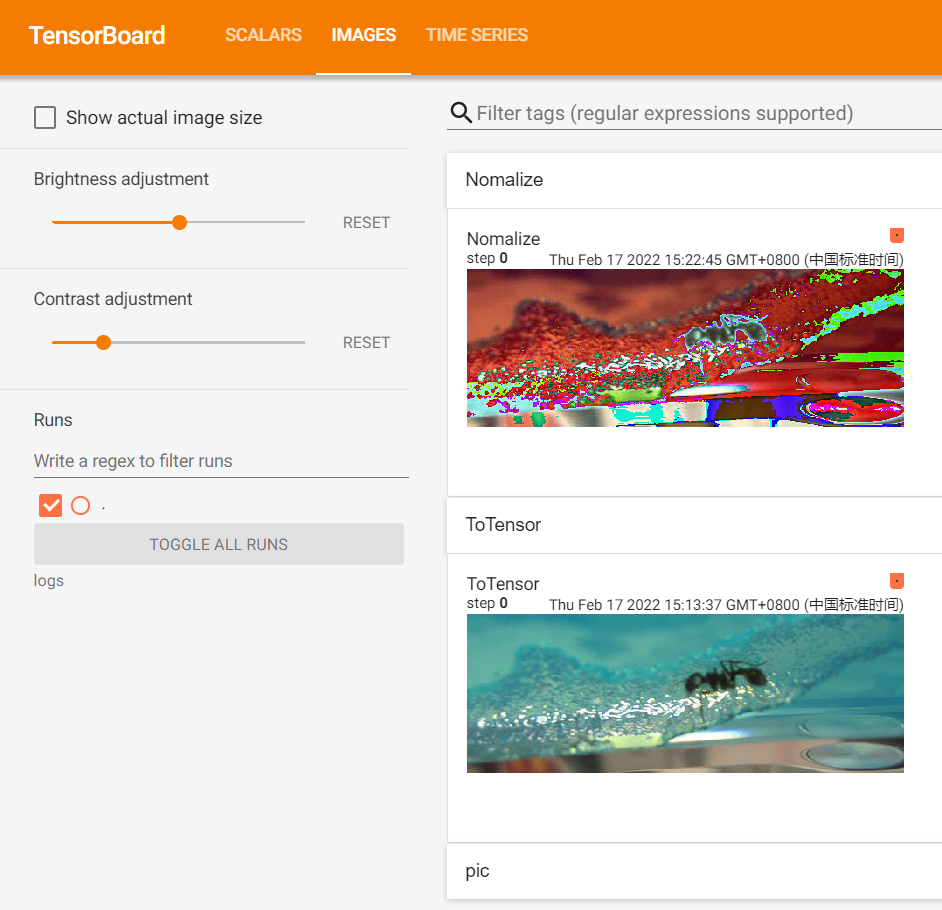
在这里只是简单地把均值和方差都设为0.5,出来的效果不是很好
Torchvision
torchvision主要使用他的数据集和transforms
import torchvision
from torch.utils.tensorboard import SummaryWriter
trans_compose = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]
)
train_set = torchvision.datasets.CIFAR10(root="./data",train=True,transform=trans_compose,download=True)
test_set = torchvision.datasets.CIFAR10(root="./data",train=False,transform=trans_compose,download=True)
print(test_set[0])
# print(test_set[1])
print(test_set.classes)
img,target = test_set[0]
print(type(img))
print(target)
print(test_set.classes[target])
# img.show()
writer = SummaryWriter("logs")
writer.add_image("cat",img,10)
writer.close()
Dataloader
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("cifar10",imgs,step)
step += 1
writer.close()
需要注意的是,如果是传很多张图片,则需要使用add_images而不是add_image,这里需要小心

torch
nn.Module
import torch
from torch import nn
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
def forward(self,input):
output = input+1
return output
module = Module()
x = torch.tensor(1.0)
output = module(x)
print(output)
定义神经网络需要继承nn.Module,然后初始化,再写一个forward函数,这样传入数据之后,就会直接执行forward函数
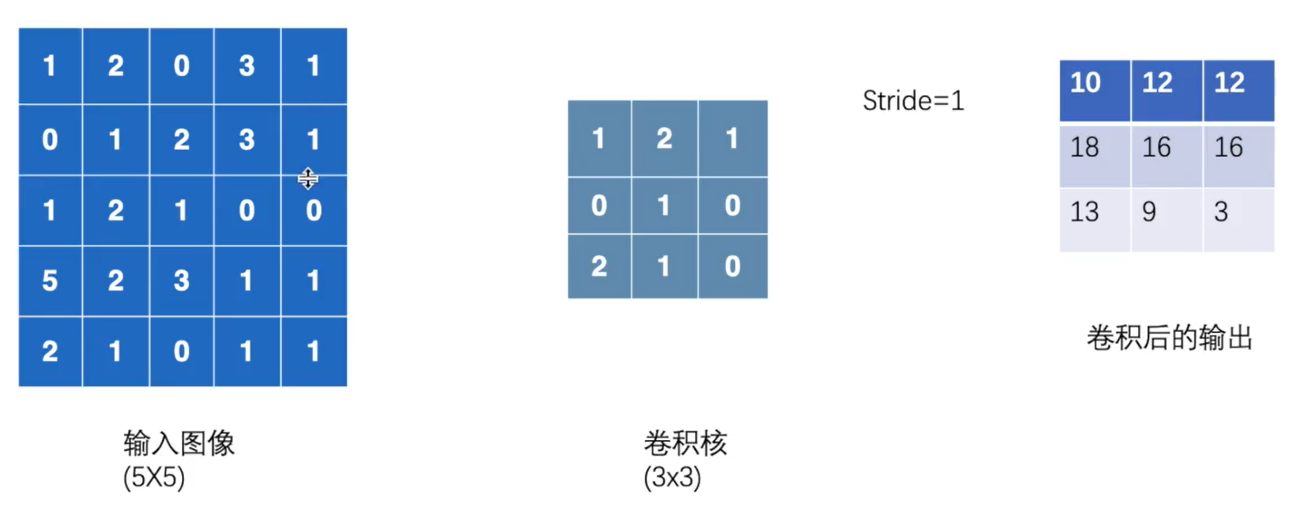
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# input.resize(1,1,5,5)
input = torch.reshape(input,[1,1,5,5])
# print(input)
# print(input.shape)
output = torch.reshape(kernel,[1,1,3,3])
result = F.conv2d(input,output,stride=1)
result2 = F.conv2d(input,output,stride=2)
result3 = F.conv2d(input,output,stride=1,padding=1)
# print(result.shape)
print(result2)
print(result3)
nn.Conv2d
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x = self.conv1(x)
return x
step = 0
net = Net()
writer = SummaryWriter("./logs")
for data in dataloader:
imgs,targets = data
output = net(imgs)
output = torch.reshape(output,[-1,3,30,30])
writer.add_images("inputs",imgs,step)
writer.add_images("outputs",output,step)
step += 1
writer.close()
nn.MaxPool2d
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.maxpool = nn.MaxPool2d(kernel_size=3)
def forward(self,input):
output = self.maxpool(input)
return output
writer = SummaryWriter("./newlogs")
net = Net()
step = 0
for data in dataloader:
imgs,target = data
output = net(imgs)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step+=1
writer.close()
nn.Sigmoid
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.sigmoid = Sigmoid()
def forward(self,input):
output = self.sigmoid(input)
return output
writer = SummaryWriter("./softmaxlog")
step = 0
net = Net()
for data in dataloader:
imgs,target = data
writer.add_images("input",imgs,step)
output = net(imgs)
writer.add_images("output",output,step)
step += 1
writer.close()
nn.Sequential

上图是对cifar10搭建的一个神经网络,首先是一个chanel为3的32*32的图片,经过一个5*5大小的卷积,得到32通道的32*32的层,然后经过一个池化层,再经过一个卷积层和一个池化层,再经过一个卷积和一个池化,然后就拉直,再线性层输出
代码如下:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# self.conv1 = Conv2d(3,32,kernel_size=5,padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,kernel_size=5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,kernel_size=5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024,64)
# self.linear2 = Linear(64,10)
self.model = Sequential(
Conv2d(3, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model(x)
return x
net = Net()
x = torch.ones((64,3,32,32))
output = net(x)
print(net)
print(output.shape)
writer = SummaryWriter("./nnlogs")
writer.add_graph(net,x)
writer.close()

交叉熵
额外补充一下交叉熵的内容:
熵的定义:无损编码事件信息的最小平均编码长度,对于N种情况进行编码,最小编码长度为$log_2 N$,把N换成$\frac{1}{N}$,那么就变成了$-log_2 P$,P此时指每种情况的概率,那么平均最小长度$Entropy = -\displaystyle\sum^{}_{i}{P(i)log_2P(i)}$
如果熵比较大(即平均编码长度较长),意味着这一信息有较多的可能状态,相应的每个状态的可能性比较低;因此每当来了一个新的信息,我们很难对其作出准确预测,即有着比较大的混乱程度/不确定性/不可预测性
“熵是服从某一特定概率分布事件的理论最小平均编码长度”,只要我们知道了任何事件的概率分布,我们就可以计算它的熵;那如果我们不知道事件的概率分布,又想计算熵,该怎么做呢?那我们来对熵做一个估计吧,熵的估计的过程自然而然的引出了交叉熵
前缀属性,遵守该属性的编码称为前缀编码:任何码字都不应该是另一个码字的前缀
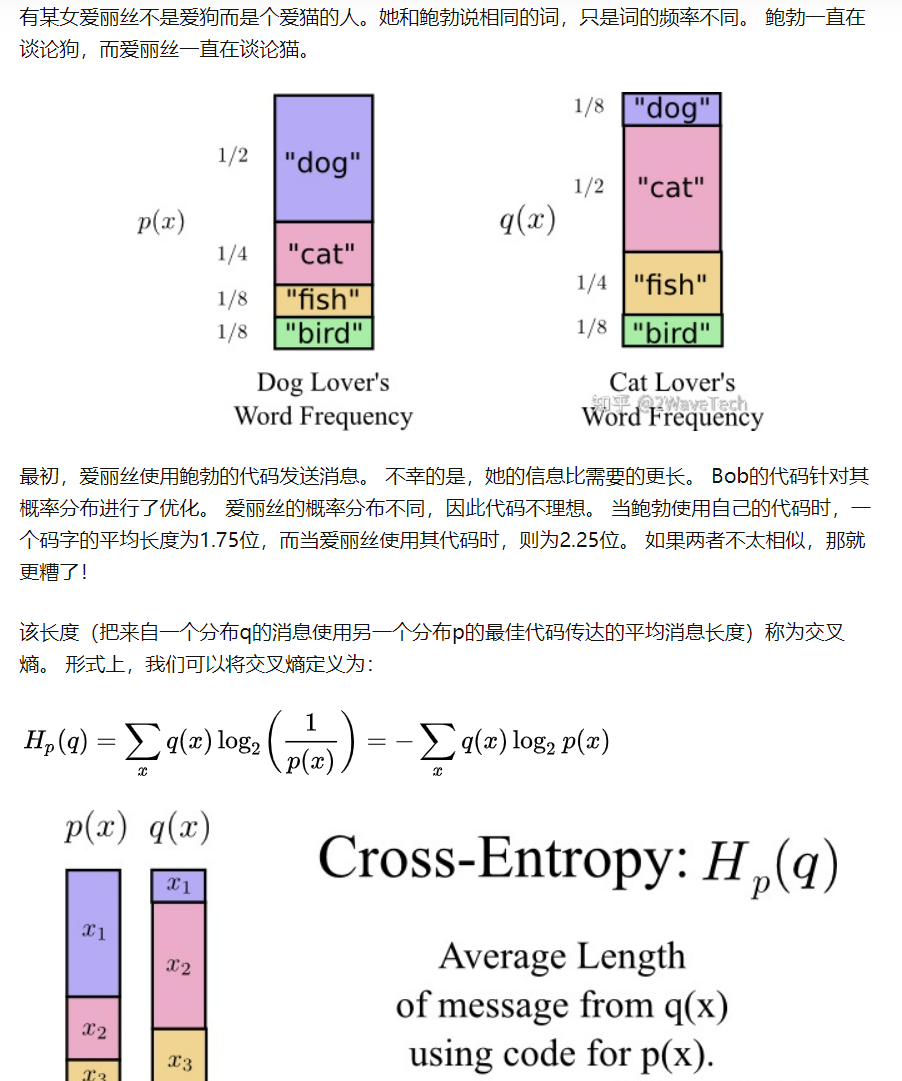
和
的分布越不相同,
相对于
的交叉熵将越大于
的熵
接下来是非常难懂的pytorch中的交叉熵公式
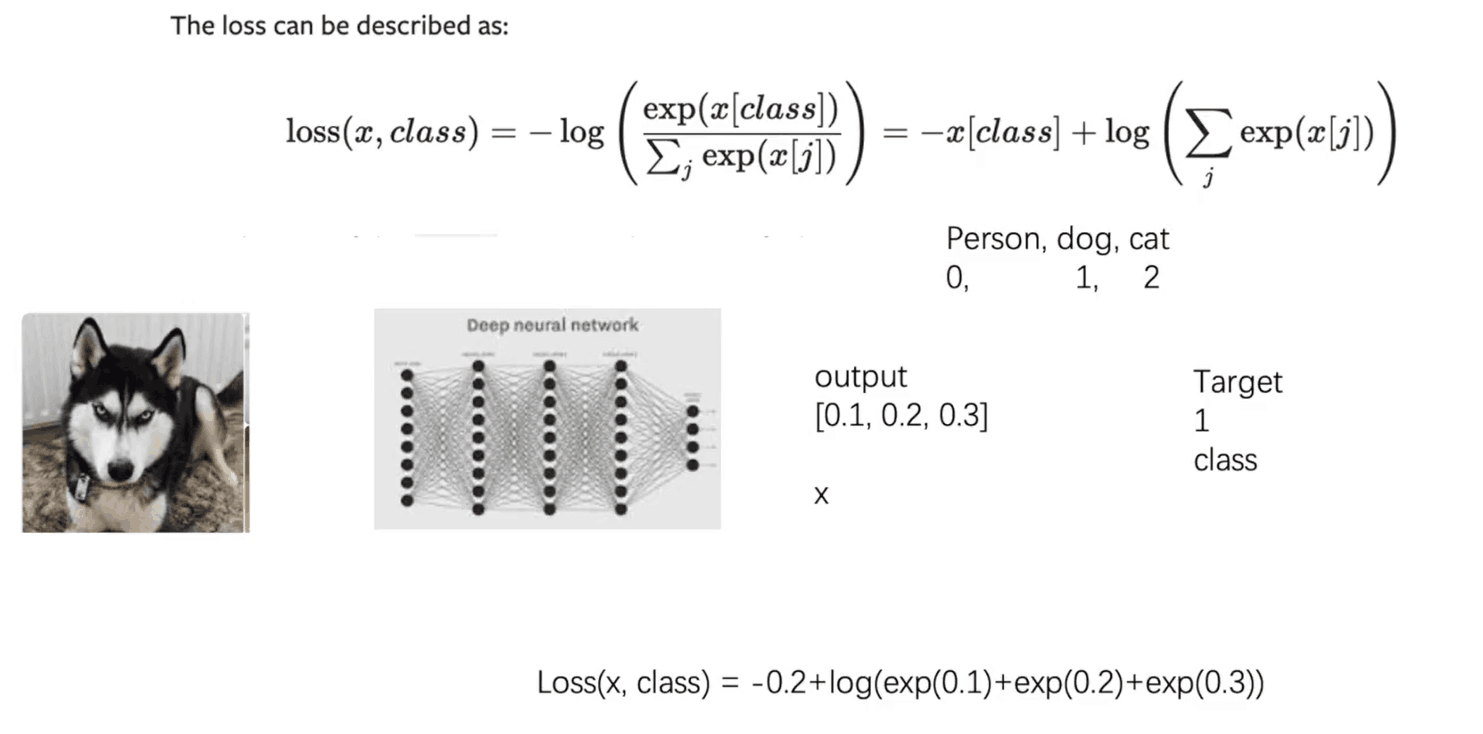
给出自己的理解,首先,如果分类不是指定的,那么p(x)为0,直接不计算,那么剩下的就是分类为指定的,比如上图中target为1(dog),那么person和cat对应的p(x)都不计算,然后先经过一个softmax,再进行交叉熵计算。这里的交叉熵计算就得到了$loss(x,class)=-x[class]+log(\displaystyle \sum^{}_{j}{exp(x[j])})$

上面是2022/2/22在pytorch官网的公式,上面也写了${y_n≠ignore_index}$
代码实现交叉熵如下:
import torch
from torch.nn import CrossEntropyLoss
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,[1,3])
loss_cross = CrossEntropyLoss()
result_loss = loss_cross(x,y)
print(result_loss)
nn.optim
优化使用起来比较简单,这里直接放教程的代码:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
模型修改与使用
import torchvision
from torch.nn import Linear
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_false = torchvision.models.vgg16(pretrained=True)
print(vgg16_false)
train_data = torchvision.datasets.CIFAR10("./data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
# 添加
vgg16_false.add_module("add_linear",Linear(1000,10))
# print(vgg16_false)
# 在指定层添加
vgg16_false.classifier.add_module("add_linear",Linear(1000,10))
# print(vgg16_false)
# 修改
vgg16_false.classifier[6] = Linear(4096,10)
print(vgg16_false)
模型保存与加载
import torch
import torchvision
vgg16_false = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16_false,"./vgg16_false.pth")
# 加载方式1
vgg16 = torch.load("./vgg16_false.pth")
# print(vgg16)
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16_false.state_dict(),"./vgg16_false2.pth")
# 加载方式2
vgg16_2 = torchvision.models.vgg16(pretrained=False)
vgg16_2.load_state_dict(torch.load("vgg16_false2.pth"))
print(vgg16_2)
整合
import torch.optim
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10("./data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
train_dataloader = DataLoader(train_data,batch_size=64,drop_last=True)
test_dataloader = DataLoader(test_data,batch_size=64,drop_last=True)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
net = Net()
net = net.cuda()
loss_fn = CrossEntropyLoss()
loss_fn = loss_fn.cuda()
learning_rate = 0.01
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("./trainLogs")
for i in range(epoch):
print("----第{}轮训练开始----".format(i+1))
for data in train_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = net(imgs)
train_loss = loss_fn(outputs,targets)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step%100 == 0:
print("训练次数:{},loss:{}".format(total_train_step,train_loss.item()))
writer.add_scalar("train_loss",train_loss.item(),total_train_step)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
# torch.no_grad可参见:https://blog.csdn.net/sazass/article/details/116668755
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = net(imgs)
test_loss = loss_fn(outputs,targets).cuda()
total_test_loss += test_loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
torch.save(net,"net_{}".format(i))
print("模型已保存")
writer.close()
正确率并不是很高,训练轮次增加会好点


 浙公网安备 33010602011771号
浙公网安备 33010602011771号