

NLTK基础学习
学习视频来自:Youtube
学习文档来自:简书
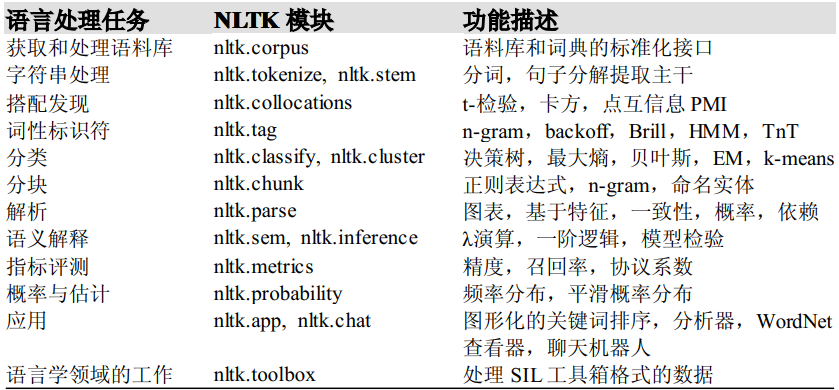
NLTK:自然语言工具包
目的:将段落拆分为句子、拆分词语,识别这些词语的词性,高亮主题,帮助机器了解文本关于什么。这个小节将解决意见挖掘或情感分析的领域
一、分析单词或句子
常见简单词汇,希望快速掌握吧:
- 语料库
Corpus:文本的正文,理解为电子文本库,corpora是其复数形式 - 词库
Lexicon:词汇及含义 - 标记
Token:拆分出来的东西。每个实体都是根据规则分割的一部分,一个句子被拆分成单词时,每个单词都是一个标记,如果拆分成句子,则句子是标记
from nltk.tokenize import sent_tokenize, word_tokenize
EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."
print(sent_tokenize(EXAMPLE_TEXT))
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]
注意这里sent_tokenize是分割句子,word_tokenize是分割词
print(word_tokenize(EXAMPLE_TEXT))
['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
这里需要注意一下,标点符号也被当作了标记,以及n't是由should't分割而来
二、NLTK与停止词
想将单词转换为数值或信号模式,那么需要预处理,预处理中有一步非常关键:过滤掉无用的数据(这里主要有降维的作用,我理解的)
将停止词理解为不含任何含义的词,进行删除
from nltk.corpus import stopwords
set(stopwords.words('english'))
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
example_sent = "This is a sample sentence, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence
# 和下面的内容等价
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(word_tokens)
print(filtered_sentence)
['This', 'is', 'a', 'sample', 'sentence', ',', 'showing', 'off', 'the', 'stop', 'words', 'filtration', '.']
['This', 'sample', 'sentence', ',', 'showing', 'stop', 'words', 'filtration', '.']
三、NLTK词干提取
词干的概念是一种规范化方法,除涉及时态之外,许多词语的变体都具有相同的含义
提取词干的原因是为了缩短查找的时间,使句子正常化
词干提取三种常用的方法:Porter、Snowball、Lancaster
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
example_words = ["python","pythoner","pythoning","pythoned","pythonly"]
for w in example_words:
print(ps.stem(w))
new_text = "It is important to by very pythonly while you are pythoning with python. All pythoners have pythoned poorly at least once."
words = word_tokenize(new_text)
for w in words:
print(ps.stem(w))
四、NLTK词性标注
把一个句子中的单词标注为名词、形容词、动词等
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
# print(train_text)
为了了解一下state_union,进行了打印,我理解的是一个数据集
训练Punkt标记器,你要问我Punkt标记器是什么,我只能说是一个无监督分词器

custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
上述train_text是训练数据,sample_text是实际要分词的数据
先看一下tokenized前五行
for i in tokenized[:5]:
print(i)
PRESIDENT GEORGE W. BUSH'S ADDRESS BEFORE A JOINT SESSION OF THE CONGRESS ON THE STATE OF THE UNION
January 31, 2006
THE PRESIDENT: Thank you all.
Mr. Speaker, Vice President Cheney, members of Congress, members of the Supreme Court and diplomatic corps, distinguished guests, and fellow citizens: Today our nation lost a beloved, graceful, courageous woman who called America to its founding ideals and carried on a noble dream.
Tonight we are comforted by the hope of a glad reunion with the husband who was taken so long ago, and we are grateful for the good life of Coretta Scott King.
(Applause.)
President George W. Bush reacts to applause during his State of the Union Address at the Capitol, Tuesday, Jan.
sample_test内容
'PRESIDENT GEORGE W. BUSH\'S ADDRESS BEFORE A JOINT SESSION OF THE CONGRESS ON THE STATE OF THE UNION\n \nJanuary 31, 2006\n\nTHE PRESIDENT: Thank you all. Mr. Speaker, Vice President Cheney, members of Congress, members of the Supreme Court and diplomatic corps, distinguished guests,...
tokenized内容
["PRESIDENT GEORGE W. BUSH'S ADDRESS BEFORE A JOINT SESSION OF THE CONGRESS ON THE STATE OF THE UNION\n \nJanuary 31, 2006\n\nTHE PRESIDENT: Thank you all.",
'Mr. Speaker, Vice President Cheney, members of Congress, members of the Supreme Court and diplomatic corps, distinguished guests,...
然后先看一下pos_tag的简单用法:
result = nltk.pos_tag(['I','have','a','pen'])
result
[('I', 'PRP'), ('have', 'VBP'), ('a', 'DT'), ('pen', 'NN')]
现在进行整合:
def process_content():
try:
for i in tokenized[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
print(tagged)
except Exception as e:
print(str(e))
process_content()
# 空间有限,这里只查看第一条
[('PRESIDENT', 'NNP'), ('GEORGE', 'NNP'), ('W.', 'NNP'), ('BUSH', 'NNP'), ("'S", 'POS'), ('ADDRESS', 'NNP'), ('BEFORE', 'IN'), ('A', 'NNP'), ('JOINT', 'NNP'), ('SESSION', 'NNP'), ('OF', 'IN'), ('THE', 'NNP'), ('CONGRESS', 'NNP'), ('ON', 'NNP'), ('THE', 'NNP'), ('STATE', 'NNP'), ('OF', 'IN'), ('THE', 'NNP'), ('UNION', 'NNP'), ('January', 'NNP'), ('31', 'CD'), (',', ','), ('2006', 'CD'), ('THE', 'NNP'), ('PRESIDENT', 'NNP'), (':', ':'), ('Thank', 'NNP'), ('you', 'PRP'), ('all', 'DT'), ('.', '.')]
这里作为分割线先把上面的内容消化一下
PunktSentenceTokenizer是一个无监督分词器,上面的例子中先是对train_txt进行了训练,再对sample_txt进行了分词,其实我们也可以使用默认的,直接进行分词,如下
In [1]: import nltk
In [2]: tokenizer = nltk.tokenize.punkt.PunktSentenceTokenizer()
In [3]: txt =""" This is one sentence. This is another sentence."""
In [4]: tokenizer.tokenize(txt)
Out[4]: [' This is one sentence.', 'This is another sentence.']
五、分块
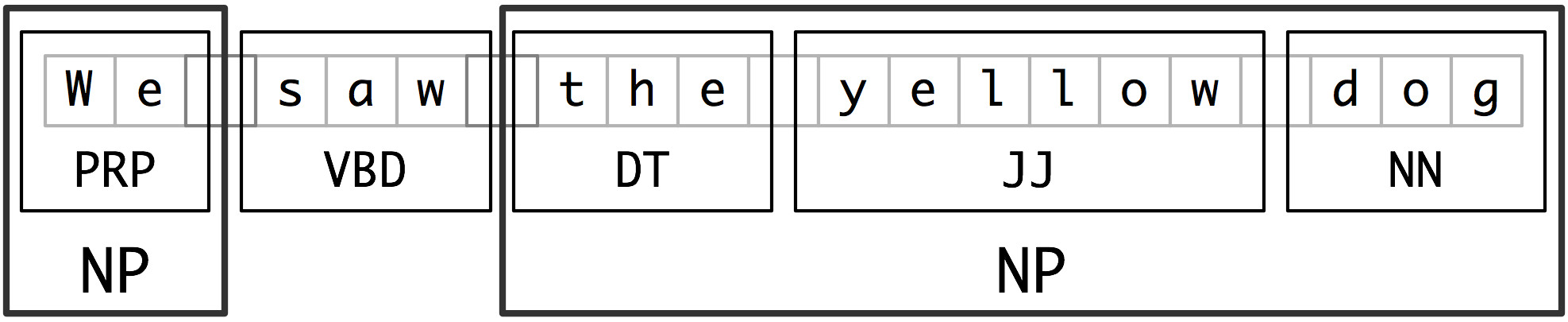
import nltk
sent = sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"),("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
grammer = 'NP:{<DT>*<JJ>*<NN>+}'
cp = nltk.RegexpParser(grammer)
tree = cp.parse(sent)
print tree
tree.draw()
NLTK中用RegexpParser来进行分块,传入一个正则表达式,这里的语法是如何分块的?
首先是DT*,然后是JJ*,最后是NN+,意思是这个块命名为NP,且这个NP中DT有0个以上,紧接着JJ有0个以上,最后NN必须有1个以上,这个需要一点正则表达式的知识
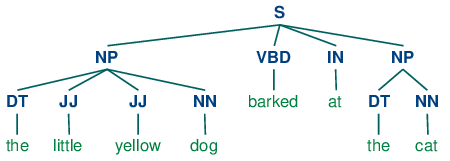
再看文档中的分块:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
作者的分块规则中NNP必须有1个以上
还可以查看子树
六、添加缝隙
chinking和chunk的区别是,chinking用}{来删除块中的块,如将原来的正则表达式规则
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
变为
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
表示不要<VB.?|IN|DT|TO>+
七、命名实体识别
前面讲了分块,这里的命名实体识别也是分块的一种,NLTK内置的,分块成如人物、地点、位置等
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
namedEnt.draw()
except Exception as e:
print(str(e))
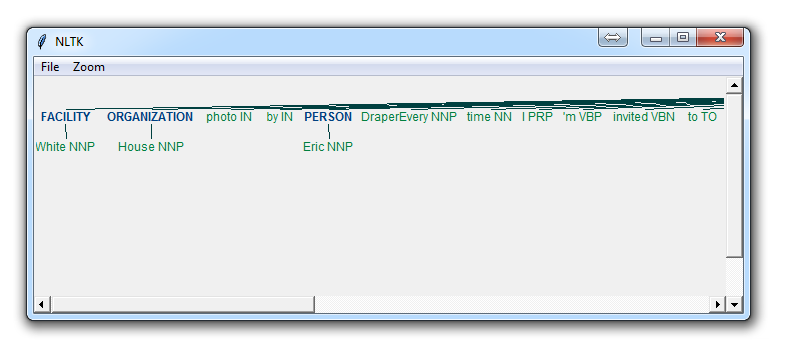
上面两张图是对属性binary设置产生不同的结果
八、词形还原
词干提取用stem,词形还原用lemmatize
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("cats"))
print(lemmatizer.lemmatize("cacti"))
print(lemmatizer.lemmatize("geese"))
print(lemmatizer.lemmatize("rocks"))
print(lemmatizer.lemmatize("python"))
print(lemmatizer.lemmatize("better", pos="a"))
print(lemmatizer.lemmatize("best", pos="a"))
print(lemmatizer.lemmatize("run"))
print(lemmatizer.lemmatize("run",'v'))
cat
cactus
goose
rock
python
good
best
run
run
注意,可以通过参数pos设置词性,如果不提供,默认是名词
九、NLTK语料库
WordNet常用文件夹有三个:omw、wordnet和wordnet_ic
omw中的文件是各个国家和地区的研究人员基于英文wordnet所做的本国语言的wordnet,cmn是简体中文
wordnet是本体
十、WordNet
- 查看同义词
from nltk.corpus import wordnet as wn
syns = wn.synsets("program")
syns
[Synset('plan.n.01'),
Synset('program.n.02'),
Synset('broadcast.n.02'),
Synset('platform.n.02'),
Synset('program.n.05'),
Synset('course_of_study.n.01'),
Synset('program.n.07'),
Synset('program.n.08'),
Synset('program.v.01'),
Synset('program.v.02')]
分别为单词、词性、序号
有点不好理解,查看定义
- 查看定义
print(wn.synset('program.n.03').definition())
print(wn.synset('broadcast.n.02').definition())
'a radio or television show'
'a radio or television show'
- 查看使用例子
wn.synset('program.n.03').examples()
['did you see his program last night?']
- 查看某条词(获得某条词)
syns[0].name()
'plan.n.01'
- 查看同义词集合
syns[0].lemma_names()
['plan', 'program', 'programme']
- 反义词
synonyms = []
antonyms = []
for syn in wordnet.synsets("good"):
# 词形还原lemmas
for l in syn.lemmas():
synonyms.append(l.name())
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(set(synonyms))
print(set(antonyms))
- 相似性
w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))
十一、文本分类
用NLTK中的copora里面的movie_reviews数据

标签分为正和负,文件夹里面都是相关txt
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
print(documents[1])
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])
documents是一个列表,但是每项都是元组
这里的shuffle没用上
words函数如果不传参数,则会把所有txt的内容输出
fileids会获得neg和pos下的txt的list形式,就有了
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
FreqDist感觉和numpy的argsort有点像
将单词转换为特征
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:3000]
print((find_features(movie_reviews.words('neg/cv000_29416.txt'))))
featuresets = [(find_features(rev), category) for (rev, category) in documents]
朴素贝叶斯分类器
本来想按照教程走完,复制粘贴就算自己学会了,但是实在没搞明白一些东西,然后觉得教程错了,遂与大家分享一下
在上面的例子中,在我们的正面和负面的文档中找到这些前 3000 个单词,将他们的存在标记为是或否,本来使用了FreqDist方法,然后再调用keys得到键,应该确实是按照FreqDist已经排好序的方法得到
all_words = nltk.FreqDist(all_words) word_features = list(all_words.keys())[:3000]
但是,当我在我的环境中(python=3.8.8)查看word_features的内容时,却不是我想要的
all_words
# FreqDist({',': 77717, 'the': 76529, '.': 65876, 'a': 38106, 'and': 35576, 'of': 34123, 'to': 31937, "'": 30585, 'is': 25195, 'in': 21822, ...})
word_features
# ['plot',
':',
'two',
'teen',
'couples',
'go',
'to',
'a',
'church',
'party',
',',...]
这就不是取前3000个,而是直接从neg的里面取的
思考之后,查找了一下字典的keys用法,有说是python版本问题
于是我安装了python=3.4,发现nltk的版本是3.2.2,并且升级不了
而我的python=3.8.8环境中,nltk是3.6.5,降级不成功
在python=3.4.5,且nltk=3.2.2的环境中输入代码如下
import nltk
import random
from nltk.corpus import movie_reviews
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
word_features = list(all_words.keys())[:3000]
all_words
#FreqDist({'meekness': 2,
'breached': 1,
'emerging': 9,
'raft': 5,
'crops': 3,
'embrace': 17,
'embarrassment': 19,
'reacquaint': 1,
'hildyard': 1,
'thumper': 1,
'easton': 1,...]
word_features
# ['meekness',
'restricts',
'breached',
'emerging',
'pammy',
'raft',
'crops',
'fiel',
'cretins',...]
嗯,与想象中很不一样
鉴于此,已经不知道现在的nltk到底如何得到最前面的3000个词,于是转而使用sklearn来调用nltk


