
20213306李鹏宇《Python程序设计》实验四实验报告
20213306《Python程序设计》实验四报告
课程:《Python程序设计》
班级:2133
姓名:李鹏宇
学号:20213306
实验教师:王志强
实验日期:2022年5月24日
必修/选修: 公选课
1.实验内容
用python对个人b站账号数据进行推送
2. 实验过程及结果
2.1 灵感
作为一个游戏爱好者,我偶尔也会发布一些新游体验视频到b站,而有时候就想看看自己的视频有没有人看,正好学习了python的网络爬虫,想着能不能做一个推送服务。
2.2 过程
2.2.1.1 1.0版本
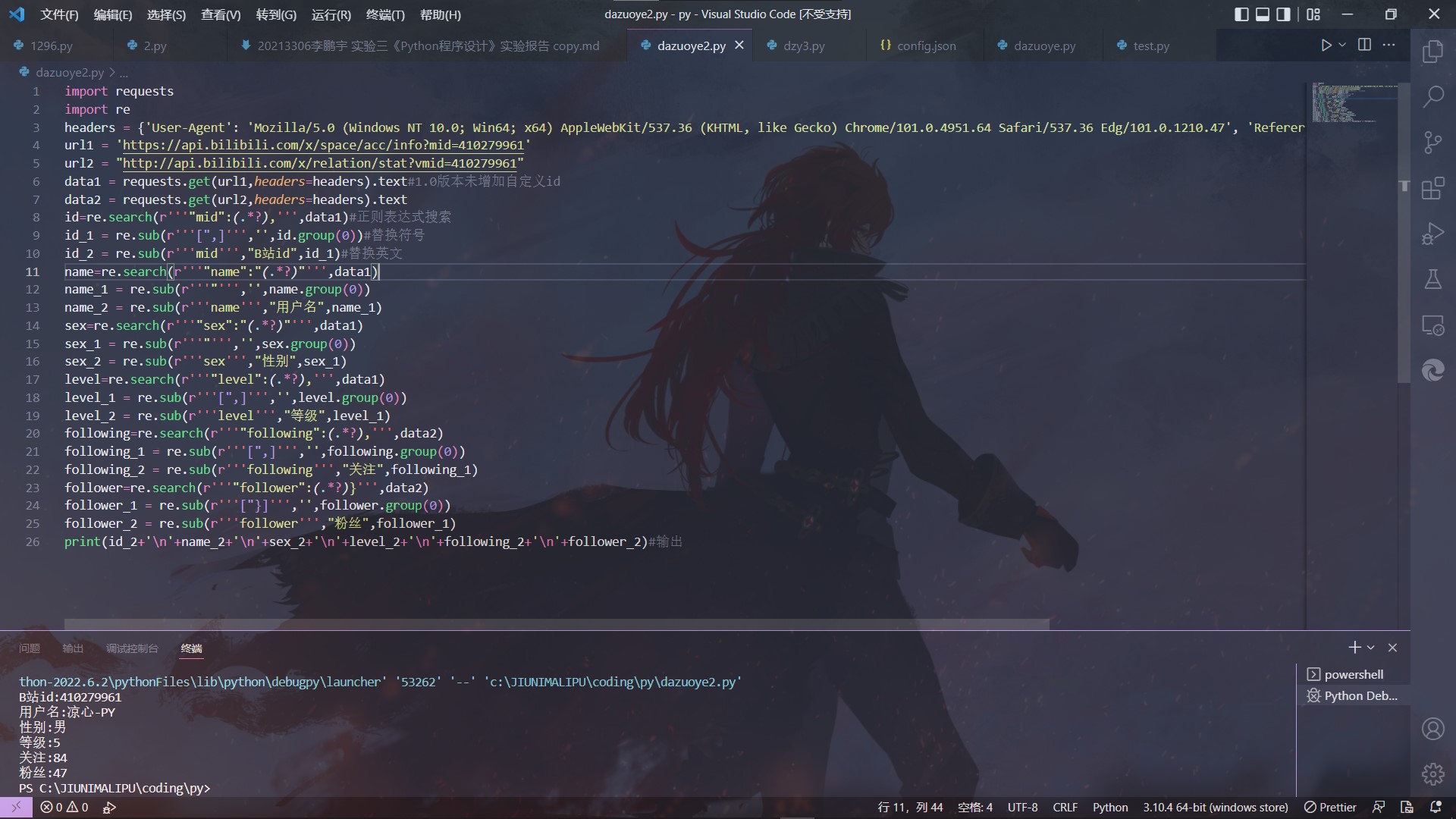
最开始只是想单纯的查看一下b站api公开的个人数据,于是照着网上的教程自己修修补补,简单地写了一个:
2.2.1.2 1.0代码
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.47', 'Referer': 'https://space.bilibili.com/410279961'}
url1 = 'https://api.bilibili.com/x/space/acc/info?mid=410279961'
url2 = "http://api.bilibili.com/x/relation/stat?vmid=410279961"
data1 = requests.get(url1,headers=headers).text#1.0版本未增加自定义id
data2 = requests.get(url2,headers=headers).text
id=re.search(r'''"mid":(.*?),''',data1)#正则表达式搜索
id_1 = re.sub(r'''[",]''','',id.group(0))#替换符号
id_2 = re.sub(r'''mid''',"B站id",id_1)#替换英文
name=re.search(r'''"name":"(.*?)"''',data1)
name_1 = re.sub(r'''"''','',name.group(0))
name_2 = re.sub(r'''name''',"用户名",name_1)
sex=re.search(r'''"sex":"(.*?)"''',data1)
sex_1 = re.sub(r'''"''','',sex.group(0))
sex_2 = re.sub(r'''sex''',"性别",sex_1)
level=re.search(r'''"level":(.*?),''',data1)
level_1 = re.sub(r'''[",]''','',level.group(0))
level_2 = re.sub(r'''level''',"等级",level_1)
following=re.search(r'''"following":(.*?),''',data2)
following_1 = re.sub(r'''[",]''','',following.group(0))
following_2 = re.sub(r'''following''',"关注",following_1)
follower=re.search(r'''"follower":(.*?)}''',data2)
follower_1 = re.sub(r'''["}]''','',follower.group(0))
follower_2 = re.sub(r'''follower''',"粉丝",follower_1)
print(id_2+'\n'+name_2+'\n'+sex_2+'\n'+level_2+'\n'+following_2+'\n'+follower_2)#输出
2.2.2.1 2.0版本
让我感觉十分不解的是,公开的api里竟然没有个人硬币数量?!
作为一个手握700+硬币的白嫖怪,这我坚决不能忍!
之前了解到,cookie可以记录登录状态,所以我尝试加入cookie
但是,我爬到的与b站的网页完全不一致,怎样能使爬取结果与实际网页相同呢?
我想起了老师之前发出的selenium模拟打卡教程
通过selenium控制firefox浏览器登录b站后,得到的结果仍然相同,但是我仍然找到了解决办法:
通过网上找到的一个firefox拓展可以让自动化状态下的firefox也被看做正常运行,下面第二个链接是原文,就不在这里放出浏览器拓展的内容了
2.2.2.2 2.0版本代码
from cgitb import html
import requests
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium.webdriver import FirefoxOptions
def isElementExist(self,element):
flag=True
browser=self
try:
browser.find_element(by=By.XPATH,value=element)
return flag
except:
flag=False
return flag
opts = FirefoxOptions()
opts.add_argument("--headless")
opts.add_argument("--disable-gpu")
browser1 = webdriver.Firefox(options=opts)
url = 'https://space.bilibili.com'
url2 = "https://member.bilibili.com/platform/home"
url3 = 'https://member.bilibili.com/platform/data-up/video/dataCenter/video'
browser1.install_addon(os.path.realpath('C:\linshi'), temporary=True)
browser1.get(url)
cookies ={
#这里是你的cookie
}
for i in cookies:
browser1.add_cookie({"name":i,"value":cookies[i],"domain":".bilibili.com","path":'/'})
browser1.refresh()
time.sleep(5)
tx = browser1.find_element(by=By.XPATH, value=r'''/html/body/div[1]/div/div/div[3]/div[2]/div[1]/span''')
ActionChains(browser1).move_to_element(tx).perform()
time.sleep(1)
name = browser1.find_element(by=By.XPATH, value=r'''/html/body/div[4]/div/p''').text
vip = browser1.find_element(by=By.XPATH, value=r'''/html/body/div[4]/div/div[2]/a''').text
level = browser1.find_element(by=By.XPATH, value=r'''/html/body/div[4]/div/div[3]/div[1]/span[1]''').text+'\t经验:'+browser1.find_element(by=By.XPATH, value=r'''/html/body/div[4]/div/div[3]/div[1]/span[2]''').text
coin = '硬币:'+browser1.find_element(by=By.XPATH, value=r'/html/body/div[4]/div/div[4]/div/div[1]/a[1]/span').text
bcoin = 'B币:'+browser1.find_element(by=By.XPATH, value=r'/html/body/div[4]/div/div[4]/div/div[1]/a[2]/span').text
following = '关注:'+browser1.find_element(by=By.XPATH, value='//*[@id="n-gz"]').text
follower = '粉丝:'+browser1.find_element(by=By.XPATH, value='//*[@id="n-fs"]').text
tougao = '总投稿:'+browser1.find_element(by=By.XPATH,value='/html/body/div[2]/div[2]/div/div[1]/div[1]/a[3]/span[3]').text
zan = browser1.find_element(by=By.XPATH, value='/html/body/div[2]/div[2]/div/div[1]/div[3]/div[1]').get_attribute("title")
bofang = browser1.find_element(by=By.XPATH, value='/html/body/div[2]/div[2]/div/div[1]/div[3]/div[2]').get_attribute("title")
browser1.get(url2)
time.sleep(7)
if isElementExist(browser1,'/html/body/div[2]/div/div/img'):
browser1.find_element(by=By.XPATH,value='/html/body/div[2]/div/div/img').click()
time.sleep(1)
date = '今天是你'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[1]/div/div[2]/div[1]').text
dcl = browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[1]/div[1]/div[2]/a').text
pinglun = '总评论:'+browser1.find_element(by=By.XPATH, value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[2]/div[1]/div[3]/div/div/div[2]/span').text
dm = '总弹幕:'+browser1.find_element(by=By.XPATH, value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[2]/div[1]/div[4]/div/div/div[2]/span').text
share = '总转发:'+browser1.find_element(by=By.XPATH, value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[2]/div[2]/div[2]/div/div/div[2]/span').text
save = '总收藏:'+browser1.find_element(by=By.XPATH, value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[2]/div[2]/div[3]/div/div/div[2]/span').text
tb = '总投币:'+browser1.find_element(by=By.XPATH, value='/html/body/div/div[3]/div[4]/div[2]/div[3]/div/div[2]/div[2]/div[4]/div/div/div[2]/span').text
money = '收益-电池:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div[4]/div[2]/div/div/p').text
browser1.get(url3)
time.sleep(5)
if isElementExist(browser1,'/html/body/div[2]/div/div/img'):
browser1.find_element(by=By.XPATH,value='/html/body/div[2]/div/div/img').click()
browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[1]/div/div[2]/div/div[1]/div/div/span').click()
time.sleep(1)
browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[1]/div/div[2]/div/div[1]/div/div/span').click()
time.sleep(1)
bofang = bofang+'(昨日增加:'+browser1.find_element(by=By.XPATH,value="/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/span").text+')'
follower = follower+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[3]/div[1]/div[2]/span').text+')'
zan = zan+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[4]/div[1]/div[2]/span').text+')'
save = save+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[5]/div[1]/div[2]/span').text+')'
tb = tb+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[6]/div[1]/div[2]/span').text+')'
pinglun = pinglun+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[7]/div[1]/div[2]/span').text+')'
dm = dm+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[8]/div[1]/div[2]/span').text+')'
share = share+'(昨日增加:'+browser1.find_element(by=By.XPATH,value='/html/body/div/div[3]/div[4]/div[2]/div/micro-app/micro-app-body/div/div/div/div[2]/div[2]/div[2]/div[9]/div[1]/div[2]/span').text+')'
shuchu = name+'\n'+vip+'\n'+level+'\n'+coin+'\n'+bcoin+'\n创作信息:\n'+date+'\n'+tougao+'\n'+dcl+'\n'+follower+'\n'+following+'\n'+zan+'\n'+bofang+'\n'+pinglun+'\n'+dm+'\n'+share+'\n'+save+'\n'+tb+'\n'+money
print(shuchu)
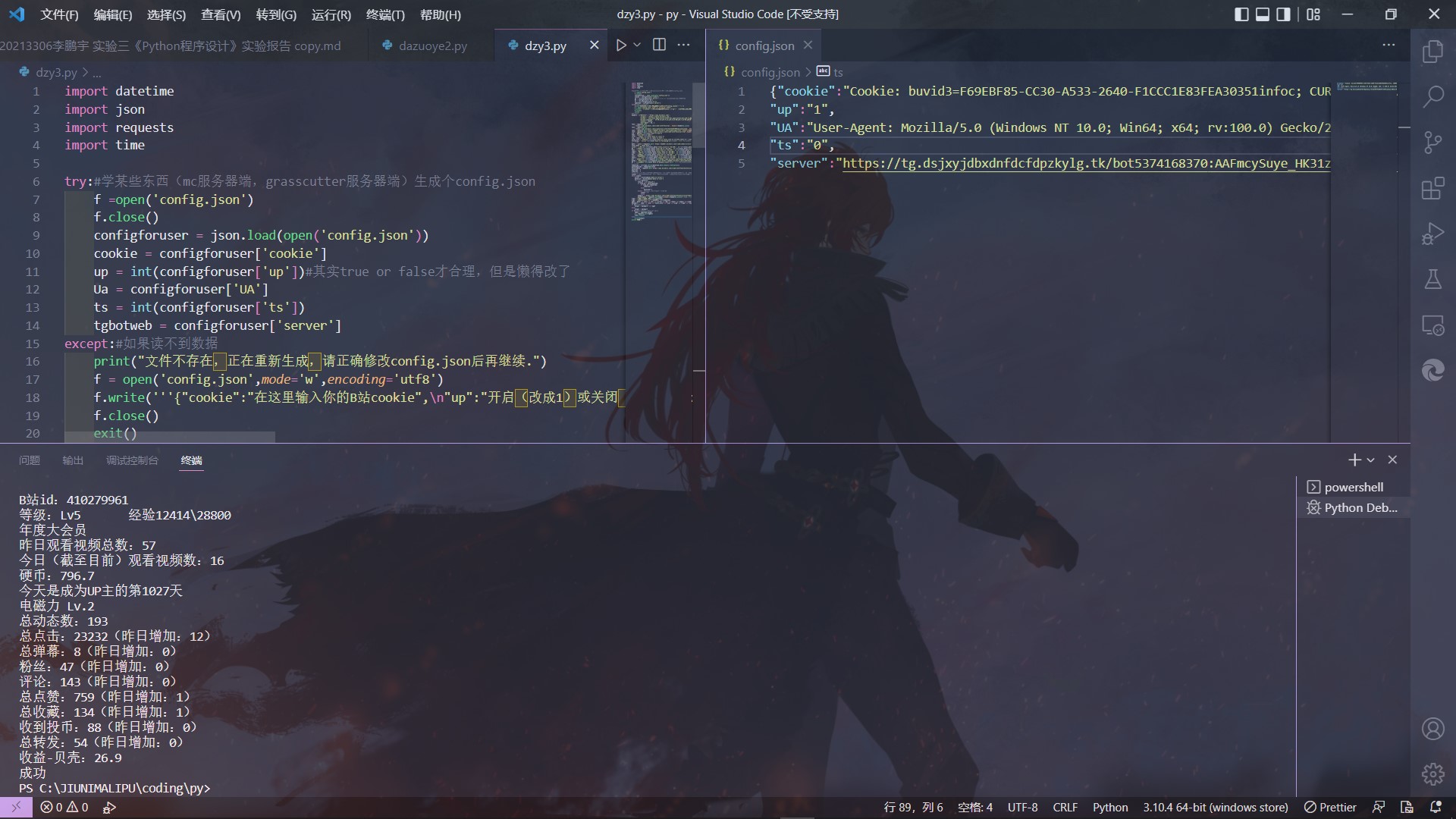
2.2.3.1 3.0版本
虽然上面的版本在我的电脑上成功运行,但是在我给ecs服务器装上firefox后(注:eular os yum还是dnf库里都没有firefox,只能用openeuler),启动python程序直接报错,原因是selenium版本与firefox不匹配,同时在多次安装更新无果后(甚至某次更新gcc某库时彻底使服务器指令链接失效,见下方参考链接),最终还是放弃了在服务器上使用selenium的方案
于是我又回到了正常的请求上来,最终经过查找了解到,原来动态网页是通过调用不同的请求来显示内容的,而这些内容使用f12开发人员工具是可以找到的,最终,经过了一系列寻找和改进之后,我完成了本次实验代码的最终版本(由于代码几乎没有借鉴,所以会显得很呆。。。)
2.2.3.2 3.0版本代码
import datetime
import json
import requests
import time
try:#学某些东西(mc服务器端,grasscutter服务器端)生成个config.json
f =open('config.json')
f.close()
configforuser = json.load(open('config.json'))
cookie = configforuser['cookie']
up = int(configforuser['up'])#其实true or false才合理,但是懒得改了
Ua = configforuser['UA']
ts = int(configforuser['ts'])
tgbotweb = configforuser['server']
except:#如果读不到数据
print("文件不存在,正在重新生成,请正确修改config.json后再继续.")
f = open('config.json',mode='w',encoding='utf8')
f.write('''{"cookie":"在这里输入你的B站cookie",\n"up":"开启(改成1)或关闭(改成0)up主模式",\n"UA":"填入你的浏览器UA",\n"ts":"推送,开为1关为0",\n"server":"暂时只做了tg bot,输入api网页链接至text=即可"}''')
f.close()
exit()
#报头
headers = {"Referer": r"https://www.bilibili.com/",
'origin': r'https://space.bilibili.com',
"Accept": 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
"Accept-Language": 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
"Cookie": cookie,
'User-Agent': Ua, }
res2 = requests.get(
r'https://api.bilibili.com/x/web-interface/nav', headers=headers).json()
res1 = requests.get(
r'https://api.bilibili.com/x/space/acc/info?mid=410279961&jsonp=jsonp', headers=headers).json()
res3 = requests.get('https://member.bilibili.com/x/web/index/stat',headers=headers).json()
res4 = requests.get(r'https://api.bilibili.com/x/web-interface/nav/stat',headers=headers).json()
uid = 'B站id:'+str(res1['data']['mid'])
name = res1['data']['name']
coins = '硬币:'+str(res1['data']['coins'])
vip = res2['data']['vip']['label']['text']
level_info = '等级:Lv'+str(res2['data']['level_info']['current_level'])+'\t经验'+str(res2['data']['level_info']['current_exp'])+'\\'+str(res2['data']['level_info']['next_exp'])
following = '关注:'+str(res4['data']['following'])#读取你点开个人中心里的数据
#第二部分
date = '今天是'+requests.get(r'https://member.bilibili.com/x/web/index/scrolls',headers=headers).json()['data']['scrolls'][0]['name']
total_data = res3['data']
click = '总点击:'+str(total_data['total_click'])+'(昨日增加:'+str(total_data["incr_click"])+')'
dm = '总弹幕:'+str(total_data['total_dm'])+'(昨日增加:'+str(total_data["incr_dm"])+')'
fans = '粉丝:'+str(total_data['total_fans'])+'(昨日增加:'+str(total_data["incr_fans"])+')'
reply = '评论:'+str(total_data['total_reply'])+'(昨日增加:'+str(total_data["incr_reply"])+')'
like = '总点赞:'+str(total_data['total_like'])+'(昨日增加:'+str(total_data["inc_like"])+')'
fav = '总收藏:'+str(total_data['total_fav'])+'(昨日增加:'+str(total_data["inc_fav"])+')'
coin = '收到投币:'+str(total_data['total_coin'])+'(昨日增加:'+str(total_data["inc_coin"])+')'
share = '总转发:'+str(total_data['total_share'])+'(昨日增加:'+str(total_data["inc_share"])+')'
dcl = '电磁力 Lv.'+str(requests.get('https://api.bilibili.com/studio/up-rating/v3/rating/status',headers=headers).json()['data']['level'])
money = '收益-贝壳:'+str(requests.get('https://member.bilibili.com/x/web/elec/balance',headers=headers).json()['data']['bpay_account']['brokerage'])
dt = '总动态数:'+str(res4['data']['dynamic_count'])#点开创作中心后的数据(b站创作中心12点更新昨日数据)
#第三部分
todaytime = int(time.mktime(datetime.date.today().timetuple()))
yesterdaytime = todaytime-86400
historybase = requests.get('https://api.bilibili.com/x/web-interface/history/cursor',headers=headers).json()
yestview = 0
todaview = 0
#todalike = 0 b站在个人历史界面并没有给出“我是否点赞了该视频”的数据,一条一条视频爬效率过低,暂时搁置
isyest = 1#另:b站并不保存所有回放记录,我只想写一个推送工具,故只用时间戳统计昨日和今日的观看量,完全可以pandas累积多日生成表格
while isyest:
cursor = historybase['data']['cursor']
datalist = historybase['data']['list']
for i in datalist:
view_at = i['view_at']
if view_at>= yesterdaytime:
if view_at>=todaytime:
todaview+=1
else:
yestview+=1
else:#一条条向上爬取,直到超过昨天0:00
isyest = 0
break
tempurl = 'https://api.bilibili.com/x/web-interface/history/cursor?max={}&view_at={}&business=archive'.format(cursor['max'], cursor['view_at'])
historybase = requests.get(tempurl,headers=headers).json()#每次最多显示20条视频记录,故循环
zrgk = '昨日观看视频总数:'+str(yestview)
jrgk = '今日(截至目前)观看视频数:'+str(todaview)
upbf = date+'\n'+dcl+'\n'+dt+'\n'+click+'\n'+dm+'\n'+fans+'\n'+reply+'\n'+like+'\n'+fav+'\n'+coin+'\n'+share+'\n'+money
basepart = name+'\n'+uid+'\n'+level_info+'\n'+vip+'\n'+zrgk+'\n'+jrgk+'\n'+coins
if up:#读取config.json
output = basepart+'\n'+upbf
else:
output = basepart
if ts:#推送部分(cf反代tg bot api)
tgbot = tgbotweb+output
a = requests.post(tgbot)
time.sleep(5)
else:
print(output)
print('成功')
2.3 关于推送
其实刚开始是没有推送这一条的,但是之前有用过某面板的经历,所以正好有一个telegram的bot,之后还自己折腾给装上了cloudflare的反向代理。于是就用上了(注:telegram走谷歌fcm能给国内推送但看不全。。。)
2.4 运行截图

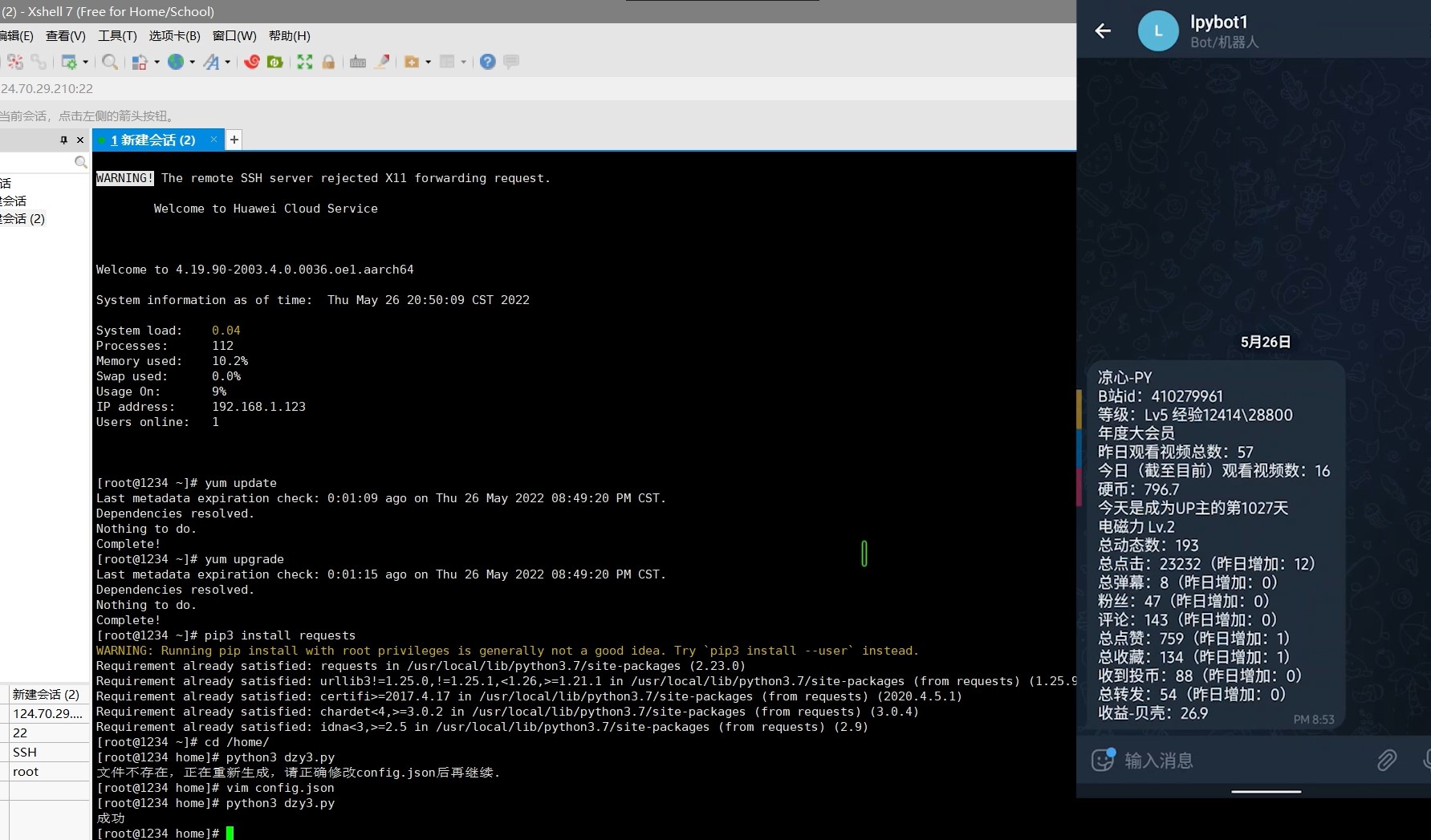
3. 实验过程中遇到的问题和解决过程
太多了,尤其是在给ecs装selenium,给eular os装桌面还有升级编译gcc尤其是更新glibc的时候(误)
解决办法 :一点一点上网查,调试,运行,修改,再调试(大不了重装服务器)
以下为部分查阅过的资料......
4. 参考资料
- 给openeuler装桌面
- Python爬取B站历史观看记录并用Bokeh做数据可视化
- python selenium判断元素是否存在
- python获取id标签对应数据_关于python 用selenium获取div里面的文本跟文本对应的id值?
- 使用浏览器扩展在运行 Selenium 的 Firefox 浏览器中伪装 navigator.webdrive
- Python selenium的webdriver之鼠标悬停
- 仙人刺也能看懂的Python爪巴虫教程——爬取b站弹幕+用户信息
- selenium 获取登录cookies,并添加cookies自动登录
- selenium获取html源代码
- 解决WebDriverException: Message: Service chromedriver unexpectedly exited. Status code was: 1
- GCC for openEuler介绍
- 安装GCC for openEuler
- Linux下GLIBCXX和GLIBC版本低造成的编译错误的解决方案
- Glibc编译报错:*** LD_LIBRARY_PATH shouldn't contain the current directory when*** building glibc. Please change the environment variable
- 编译glibc(gcc)以及过程中遇到的一些错误
- rm: relocation error: /lib64/libc.so.6: symbol _dl_starting_up, version GLIBC_PRIVATE not defined in
- python读取json文件报错AttributeError: ‘str‘ object has no attribute ‘read‘
- JSON 如何注释
- Python 日期和时间
- python 获取当天凌晨零点的时间戳
- Python 异常处理
- requests.get()获取的网页代码与浏览器源码不一样,怎么解决?
- Python—爬虫之Network,XHR,json & 带参数请求数据(爬取歌单、歌词)
5.结课感悟
Python正式结课了,相对于我们必修课程的C语言,Python确实易用,并且相对于C语言现在只能靠命令行输入输出,Python在各类模块的加持下可以更快更明显地进入实践解毒丹见到效果。
在高中时我和几个喜欢折腾的同学用旧手机开过我的世界的服务器,当时用termux,用anlinux等等因此对vnc,ssh等等工具都有所了解,同时也逐渐开始了解到一些编程语言,毕竟你得能看懂config.json吧(现在有个非常好的多服务器管理工具叫MCDR,是个开箱即用的python模组)
当我看到选修课里有Python时,我第一反应就是报名这门选修,当然,我也在这门课上正式地学习了(其实也只是初步认识了)Python,也知道了很多很多其他编程语言也会用到的知识。度过了一段美好的学习时光。很开心能够学习到这门选修课,也希望自己能够在以后保持使用和学习Python。毕竟
Life is short, you need python.
