

用node爬取网页上的内容
如何用node简单的爬取网页上的内容:
1.安装express以及生成器
express官网:http://www.expressjs.com.cn/
npm install express --save npm install express-generator -g
2.用生成器创建新Express应用,进入项目并安装依赖包
express myapp cd myapp npm install
3.安装superagent
superagent官网:http://visionmedia.github.io/superagent/
npm install superagent
4.安装cheerio
cheerio官网:https://cheerio.js.org/
npm install cheerio
5.在routes文件夹下新建路由文件news.js
var express = require("express"); const cheerio = require('cheerio'); const superagent = require('superagent'); var router = express.Router(); router.get('/', function (req, res, next) { // 抓取内容 superagent.get('http://www.donews.com/') .end(function (err, sres) { if (err) { return next(err); } var $ = cheerio.load(sres.text); var items = []; $('div.block h3.block a').each(function (idx, element) { var $element = $(element); items.push({ title: $element.text(), href: $element.attr('href') }); }); res.send(items); }); }); module.exports = router;
superagent.get('抓取网页的地址')
网页的 html 内容存储在 sres.text 里面
用 cheerio.load 加载得到的html内容并赋给变量 $
后面选择需要的内容部分语法和jQuery选择器基本一致,选择需要的元素进行遍历
然后返回遍历的内容
6.在app.js中引入路由文件
var createError = require('http-errors'); var express = require('express'); var path = require('path'); var cookieParser = require('cookie-parser'); var logger = require('morgan'); var newsRouter = require('./routes/news'); var app = express();// 创建实例 var myLogger = function (req, res, next) { console.log('LOGGED'); next(); } var requestTime = function (req, res, next) { req.requestTime = Date.now(); console.log(req.requestTime); next(); } // view engine setup app.set('views', path.join(__dirname, 'views')); app.set('view engine', 'pug'); app.use(logger('dev')); app.use(express.json()); app.use(express.urlencoded({ extended: false })); app.use(cookieParser()); app.use(express.static(path.join(__dirname, 'public')));// 将 public 目录下的图片、CSS 文件、JavaScript 文件对外开放访问(此写法为绝对路径) app.use(myLogger); app.use(requestTime); app.use('/news', newsRouter); //设置跨域请求 app.use('*', function (req, res, next) { res.header("Access-Control-Allow-Origin", "*"); res.header('Access-Control-Allow-Headers', 'Content-Type, Content-Length, Authorization, Accept, X-Requested-With , yourHeaderFeild'); res.header("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS"); res.header("X-Powered-By", ' 3.2.1') res.header("Content-Type", "application/json;charset=utf-8"); next(); }); // catch 404 and forward to error handler app.use(function(req, res, next) { next(createError(404)); }); // error handler app.use(function(err, req, res, next) { // set locals, only providing error in development res.locals.message = err.message; res.locals.error = req.app.get('env') === 'development' ? err : {}; // render the error page res.status(err.status || 500); res.render('error'); }); module.exports = app;
引入路由的代码:
var newsRouter = require('./routes/news');
app.use('/news', newsRouter);
7.运行
npm start
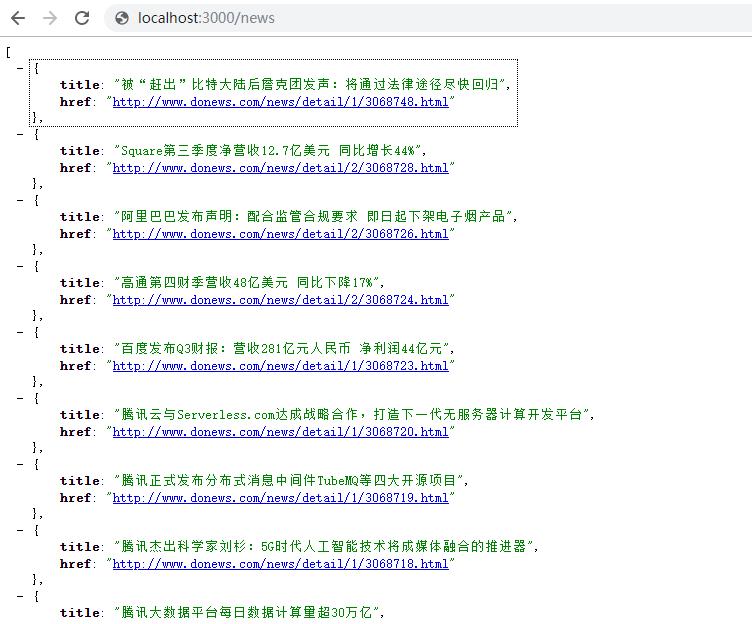
浏览器打开项目即可看到爬取的数据


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程