
阅读笔记:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
DualGAN:用于图像转换的无监督双向学习
作者:Zili Yi、Hao (Richard) Zhang、Ping Tan 和 Minglun Gong 纽芬兰纪念大学 西蒙弗雷泽大学
论文发表时间:2017年4月
摘要
使用条件生成对抗网络(cGAN)进行跨域图像转换在过去一年中取得了重大改进【3】【6】【7】【9】【15】【18】。 根据任务的复杂程度,训练cGANs需要成千上万甚至数百万张标注图像对。然而,人工标注非常昂贵,有时甚至是不切实际的。受自然语言翻译中双向学习模式的成功所启发【20】,我们开发了一种新颖的 dual-GAN(双向GAN) 机制,使图像生成器能够从两组未标记的图像中进行训练,每组图像分别代表一个域。在我们的架构中,原始GAN 学习将
域中的图像转换为 域中的图像,而对偶GAN(dual GAN) 则学习将 域中的图像转换为 域中的图像。原始任务和对偶(dual)任务所形成的闭合回路可以将任一领域的图像进行转换,然后进行重建。因此,可以使用考虑图像重建误差的损失函数来训练转换模型。在多种无标签数据的图像转换任务上的实验表明,我们的dual-GAN架构相比于单一GAN有显著的性能提升。在某些任务中,我们的模型甚至可以取得与在完全标记数据上训练的cGAN相当或更好的结果。
引言
许多图像处理和计算机视觉任务,例如边缘检测、图像分割、风格化和抽象化,都可以看作是图像转换问题【3】,即将物体或场景的一种视觉表示转换成另一种视觉表示。传统上,这些任务由于其内在差异而被分开处理【3】【6】【7】【9】【15】【18】。直到近两年,才出现了通用的、能够完整处理多种任务的深度学习框架,特别是那些使用全卷积网络(FCNs)【8】和条件生成对抗网络(cGANs)【3】的框架,使得对这些任务进行统一处理成为可能。
迄今为止,这些通用方法都是在大量标记和匹配图像对的监督和训练下完成的。但在实际操作中,获取此类训练数据可能非常耗时(例如,逐一像素或逐块标记),甚至不现实。例如,虽然有大量的照片或素描可供使用,但描绘相同姿势下的相同人物的照片-素描图像对却很少。在其他一些情况下,比如将白天场景转换为夜晚场景,即使可以使用固定摄像头获得有标签的匹配图像对,但它们也没有精确对齐,可能包含略有不同的内容。
在本文中,我们旨在开发一种用于通用图像转换的无监督学习框架,该框架仅依赖于未标记的图像数据,例如用于照片到素描转换任务的两组照片和素描图像。显然这其中的技术难题是如何在没有任何可以表征正确转换的数据的情况下训练生成器。我们的方法受自然语言处理中的双向学习所启发【20】。双向学习通过最小化两个翻译器嵌套应用所产生的重构损失,同时训练两个 "相反 "的语言翻译器(例如,英译法和法译英)。这两个翻译器构成一个 原始-对偶 对,它们嵌套应用形成一个闭环,从而允许应用强化学习。具体来说,单语数据(英语或法语)上的重建误差会生成有用的反馈信息来训练双语翻译模型。
我们的研究首次为图像转换开发了双向学习框架,并且与Xia等人的原始NLP双向学习方法在两个关键方面上有所不同【20】。首先,NLP方法依赖于预训练的(英语和法语)语言模型,以表明翻译器输出在各自目标语言中是自然句子的可信度。考虑到通用处理的需求,我们意识到对于许多图像转换任务,很难获得这样的预训练模型。因此,我们工作开发了与图像转换模型对抗训练的GAN判别器【2】,旨在捕捉领域分布。因此,我们将我们的学习架构称为 DualGAN。此外,我们采用 FCN 作为转换模型,它能自然地适应图像的二维结构,而不是 LSTM 或 GUT 等序列到序列的转换模型。
DualGAN 将两组未标记的图像作为输入,每组图像代表一个图像域,DualGAN同时学习两个从一个域到另一个域的可靠图像生成器,因此可以完成各种图像转换任务。通过与 GAN(带有图像条件生成器和原始判别器)【3】和cGAN的比较,验证了其有效性。比较结果表明,在某些应用中,DualGAN的性能优于基于标记数据训练的监督方法。
相关工作
生成式对抗网络(GANs)
自 2014 年 Goodfellow 等人的开创性工作以来【2】,已经出现了一系列用于各种问题的GAN方法。原始的 GAN 通过引入一个对抗判别器来不断区分真实数据和生成数据,从而训练生成器以捕捉真实数据的分布【2】。随后,各种cGAN(cGAN)被提出,用于基于类别标签【10】、特征【11】【21】、文本【12】和图像等条件来生成图像【3】【6】【7】【9】【15】【18】。
在图像条件模型中,大多数都是为特定应用而开发的,例如超分辨率【6】、纹理合成【7】、从法线图(用于表示表面的法线方向信息)到图像的风格迁移【18】和视频预测【9】,而很少有针对通用处理而设计的模型【3】【15】。Isola 等人提出的图像转换的通用解决方案需要大量标记的图像对【3】。Taigman等人提出的跨域图像转换的无监督机制【15】可以在没有配对图像的情况下训练一个图像条件生成器,但依赖于一个复杂的预训练函数,该函数将任意域的图像映射到一个中间表示,这需要其他格式的有标签数据。与这些方法不同的是,我们的dual-GAN机制只需要来自两个相关域的无标签图像,并且不需要任何作为两者之间桥梁的第三方表征。此外,它能同时训练原始GAN和对偶GAN,从而利用重建误差项生成信息反馈信号。虽然我们的DualGAN采用了GAN的关键理念,但DualGAN能通过自我优化的判别器使生成的数据更符合目标分布。
双向学习
双向学习最早由 Xia 等人提出【20】,目的是减少训练英译法和法译英翻译时对标记数据的要求。法译英是英译法的双向任务,两者可以并行训练。双向学习的关键思想是建立一个双向学习游戏,其中包括两个代理,每个代理只能理解一种语言,并能评估翻译后的句子在目标语言中是否自然,以及重建后的程度是否与原文一致。这种机制是双方交替进行的,使得翻译器只需从单语数据中训练。
尽管这种机制缺乏平行的双语数据,但仍可生成两类反馈信号:评估翻译文本属于目标语言可能性的成员得分,以及衡量重建句子与原文之间差异的重建误差。这两个信号都是在特定应用领域知识(即预先训练好的英语和法语语言模型)的帮助下进行评估的。在我们的工作中,我们的目标是为图像转换提供通用解决方案,因此没有利用任何特定领域的知识或预先训练的领域表征。相反,我们使用域自适应GAN判别器来评估转换样本的成员得分,而重建误差则以重建图像和原始图像之间绝对差异的平均值来衡量。
方法
假设我们有两组分别从图像域
和 中采样的无标签图像。原始任务是学习一个生成器 ,将图像 映射到图像 ,而对应的对偶任务是训练一个生成器 。为此,我们使用了两个GAN,即原始GAN和对偶GAN。原始GAN学习生成器 和一个判别器 ,判别器 用来区分 生成的伪造输出和域V中的真实成员。同样,对偶GAN学习生成器 和一个判别器 。整体架构和数据流如图1所示。
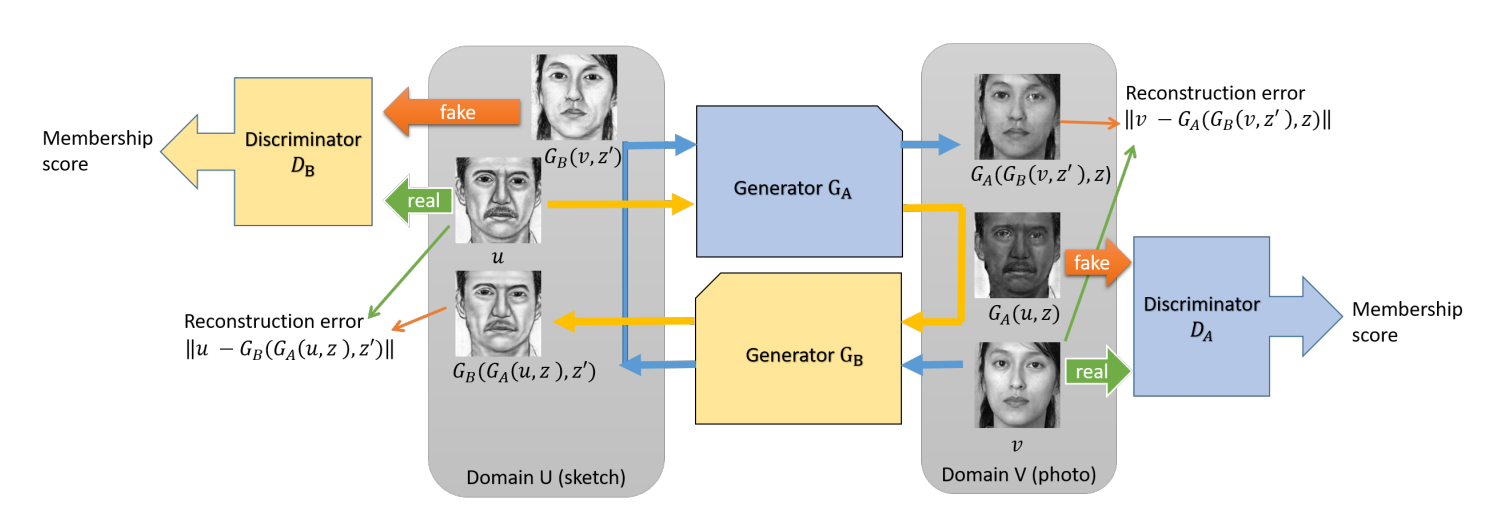
图1:双重学习机制的架构和数据流程图
如图1所示,原始数据
使用生成器 转换到域 。转换结果 在域 中的适配度由判别器 评估,其中 是随机噪声(下面出现的 也是随机噪声)。然后使用生成器 将 转换回域 ,输出 作为 的重建版本。同样地, 被转换到域 为 ,然后重建为 。判别器 以 为正样本,以 为负样本进行训练,而 以 为正样本,以 为负样本进行训练。生成器 和 被优化以生成“假”输出以迷惑相应的判别器 和 ,同时最小化重建损失 和 。
目标
如同传统的GAN一样,判别器的目标是区分生成的伪样本和真实样本。不过,在这里我们采用了WGAN(Wasserstein GAN)【1】倡导的损失形式,而不是原始GAN【2】使用的Sigmoid交叉熵损失。事实证明,前者在生成器收敛和样本质量方面表现更好,并且提高了优化过程的稳定性【1】。判别器
和 使用的相应损失函数定义如下: 其中
。
由于生成器和生成器 的目标相同,因此使用了相同的损失函数。以前的条件图像合成方法发现,将L2距离替换为L1距离通常效果更好,因为 L2 距离经常会导致图像模糊【5】【20】。因此,在这里我们使用 L1 距离来测量重建误差,并将其添加到GAN目标中,以强制转换样本服从域分布;见公式3。
其中
, , 和 是两个常数参数。根据具体应用, 和 通常设置为100.0到1,000.0。如果 是自然图像而 不是(例如航拍照片U-地图V),我们发现使用比 更小的 效果更好。
网络配置
我们对
和 采用相同的网络结构。生成器配置了相同数量的下采样层(池化层)和上采样层。此外,我们在生成器中配置了镜像下采样层和上采样层之间的跳跃连接,如文献【3】【10】所述,使其成为一个U型网络(见图11)。这种设计有益于使输入和输出之间可以共享低层次信息,因为许多图像转换问题都隐含地需要对齐输入和输出结构(例如,物体、形状、边缘、纹理、杂乱等)。如果没有跳跃连接层,所有信息都必须通过狭窄通道传递,这通常会导致高频信息的严重损失。此外,与文献【3】类似,我们没有明确地提供噪声向量 和 。它们仅以dropout(随即失活)的形式提供,并在训练和测试时应用于生成器的多个层:详情请参见文献【3】。
对于判别器,我们采用了Markovian PatchGAN结构(见文献【7】).该结构假定像素间的距离超过特定Patch(块)大小时,像素间的距离是独立的,并且仅在Patch(块)级别上对图像进行建模,而不是在完整的图像尺寸上。这种结构在捕获局部高频特征(如纹理和风格)方面非常有效,但在全局分布建模方面则效果不佳。不过它满足我们的需求,因为恢复损失鼓励保留全局和低频信息,而判别器则被指定用于捕获局部高频信息。这种结构的有效性已在各种图像转换任务中得到验证。类似于文献【20】,我们在图像上通过卷积方式运行这个判别器,将所有响应平均以提供最终输出。这种结构的另一个优点是所需参数更少,运行速度更快,而且对输入图像的大小没有限制。
训练过程
为了优化我们的网络,我们遵循WGAN【1】中提出的训练过程:见算法1.我们训练判别器
步,然后训练生成器一步。我们使用小批量随机梯度下降法(mini-batch Stochastic Gradient Descent),并应用RMSProp优化器,因为基于动量的方法(如Adam)偶尔会导致不稳定性,而RMSProp在高度非稳态问题上表现良好【1】【16】。我们通常将每次生成器迭代的判别器迭代次数 设置为2-4次,并将批量大小设置为1-4次,在实验中发现这对效果影响不大。截断参数 通常设置为0.01到0.1之间,具体取决于应用。
| 算法1 DualGAN训练过程 |
|---|
| 需求:图像集 |
| 1:随机初始化 |
| 2:重复执行 |
| 3: for t= 1,..., |
| 4: 从图像集 |
| 5: 更新 |
| 6: 更新 |
| 7: 将 |
| 8: 结束循环 |
| 9: 从图像集 |
| 10: 更新 |
| 11:直到收敛 |
对于传统的 GAN 来说,训练过程需要仔细平衡生成器和判别器之间的关系。这是因为,随着判别器的优化,sigmoid 交叉熵损失就会局部饱和,导致梯度消失。不同于传统的GAN,Wasserstein损失几乎在每个地方都是可微的,从而提高了判别器的性能。在每次迭代中,生成器在判别器经过
步训练后才进行训练。这种过程使得判别器能够提供更可靠的梯度信息【1】。
实验结果与评估
为了探索 DualGAN 的通用性,我们在多种图像到图像映射任务中对该方法进行了测试,包括照片-素描转换、标签-图像转换以及图像的艺术风格化。为了将我们的无监督 DualGAN 与 GAN 和 cGAN 【3】进行比较。我们使用了四个标注数据集: PHOTO-SKETCH【19】【22】、DAY-NIGHT【4】、LABELFACADES【17】和 AERIAL-MAPS(直接从 google 地图采集【3】)。这些数据集由从一个域映射到另一个域的图像对组成,因此可用于监督学习。不过,需要注意的是,这些数据集都不能保证像素级的精确特征对齐。例如,SKETCH-PHOTO 数据集中的素描图像是由艺术家绘制的,因此不能与相应的照片精确对齐;在 DAY-NIGHT 数据集中经常会出现移动物体和路灯;LABEL-FACADES 数据集中的标签也不总是精确的。这些问题也突显了获得高质量匹配图像对的困难。
我们的方法使我们能够利用网络上丰富的无标签资源。因此,我们还使用了两个额外的未标注数据集进行实验。MATERIAL(材料)数据集包括由不同材料制成的物体的图像,如石头、金属、塑料、织物和木材。这些图像是从Flickr(Flickr 是一个著名的图片和视频托管平台,允许用户上传、分享和浏览照片和视频。)上手动选择的,涵盖了各种照明条件、构图、颜色、纹理和材料子类型【14】。这个数据集最初用于材料识别,但在这里用于材料转换。OIL-CHINESE PAINTING数据集包括两种截然不同风格的艺术画作:油画和中国画。所有图像都是从搜索引擎上抓取的,包含各种质量、格式和大小的图像。我们重新格式化、裁剪和调整这些图像的大小以进行训练和评估。在上述两个数据集中,不同域之间的图像没有对应信息。
定性评估
使用这四个标注数据集,我们首先将我们的方法与GAN和cGAN【3】在以下图像转换任务上进行比较:白天→夜晚(图2)、建筑标签↔照片(图3和图10)、人脸照片↔素描(图4和图5)以及地图↔航拍照片(图8和图9)。
在所有这些任务中,cGAN是用标注数据训练的。在此,我们采用【3】中提供的模型和代码,并为每个任务选择最佳损失函数:facades→label任务使用L1损失,其他任务使用L1+cGAN损失(更多详细信息请参见文献【3】)。相比之下,DualGAN和GAN是在无监督的方式下进行训练的。也就是说,我们要先解除图像对的绑定,然后重新整理数据。通过在公式3中设置,值得注意的是,这个GAN不同于原始的GAN模型【2】,因为它采用了一个条件生成器。
三个模型都在相同的训练数据集上进行训练,并在不重叠的测试数据上进行测试。所有训练都在单个GeForce GTX Titan X GPU上进行。在测试时,所有模型在此GPU上运行的时间都不到一秒。
与GAN相比,DualGAN在几乎所有情况下都生成了更不模糊、包含更少伪影、更好地保留输入结构并捕捉目标域特征(如纹理、颜色、风格)的结果。我们将这种改进归因于额外的重建损失,这种损失迫使输入能够通过双生成器从输出中重建,从而加强了编码目标分布的反馈信号。
在许多情况下,我们的结果在清晰度和对输入图像的保真度方面也优于cGAN的结果;见图2、图3、图4、图5和图8。这令人鼓舞,因为后者(cGAN)利用了额外的图像和像素对应信息。不过,当任务是在照片和基于语义的标签之间进行转换时,如地图↔航拍和标签↔建筑立面(facades),仅基于目标分布通常不可能推断出像素颜色和标签之间的对应关系。因此,DualGAN可能会将像素映射到错误的标签(见图9和图10)或将标签映射到错误的颜色/纹理(见图3和图8)。
图6和图7进一步展示了使用两个未标注数据集获得的图像转换的结果,包括:油画↔中国画、塑料↔金属、金属↔石头、皮革↔织物和木材↔塑料。结果表明,即使在目标域中找不到相应的图像,也能生成视觉上令人信服的图像。这些结果通常比GAN的结果包含更少的伪影。

图2:日→夜转换的结果。cGAN使用标记数据进行训练,而DualGAN和GAN则以无监督的方式进行训练。DualGAN成功模拟了夜间场景,并保留了输入的纹理;相比之下,cGAN和GAN的结果包含的细节要少得多。
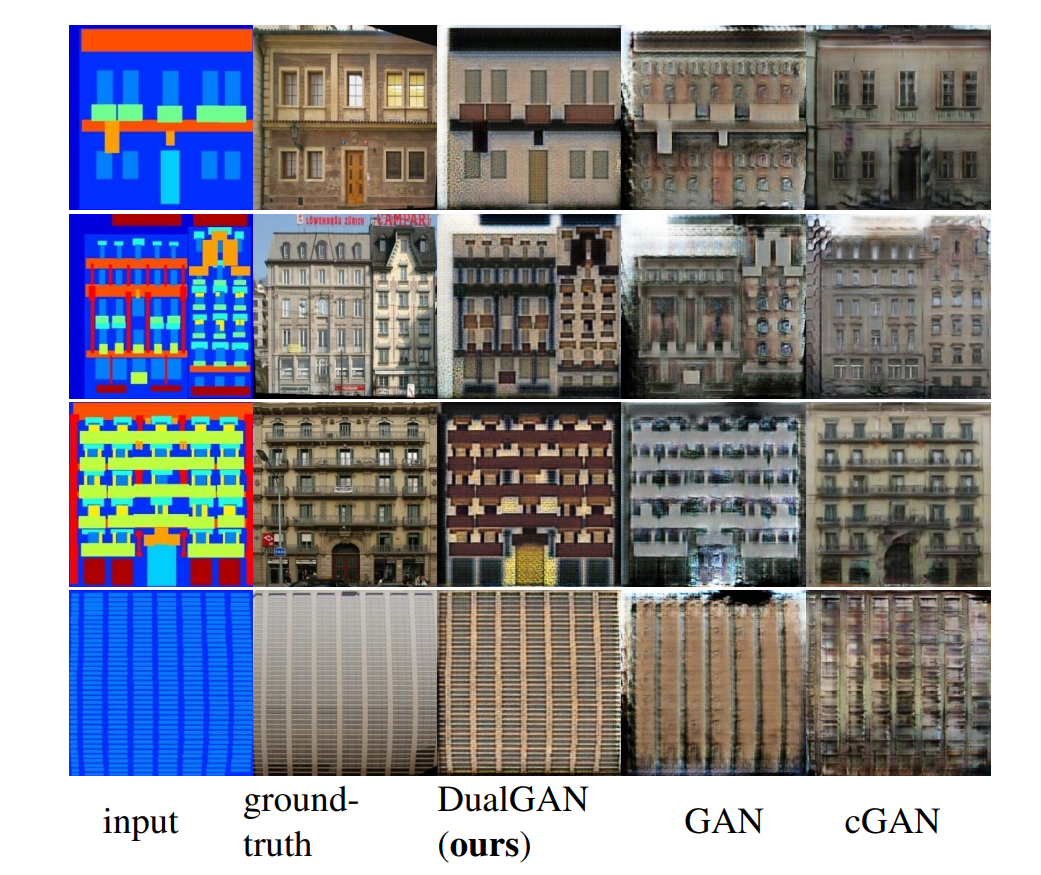
图3:建筑标签→照片转换的结果。DualGAN很好地保留了标签图像中的结构,即使有些标签与对应的照片不太匹配;例如,参见顶行的前两张图。相比之下,GAN和cGAN的结果包含许多伪影。在标签和照片经常不对齐的区域,cGAN通常会产生模糊的输出(例如,第2行的屋顶和第3行的入口)。

图4:照片→素描转换的结果。DualGAN的结果通常比cGAN的更清晰,即使前者使用未标记的数据进行训练,而后者使用的是标记数据。

图5:素描→照片转换的结果。与我们的结果相比,GAN和cGAN生成的结果中出现了更多的伪影和模糊。

图6:中国画→油画任务的实验结果。GAN 结果中显示的背景网格意味着 GAN 的输出不如 DualGAN 稳定。

图7:各种材质转换任务的实验结果:从上到下依次为,塑料→金属,金属→石头,皮革→织物,塑料↔木材。
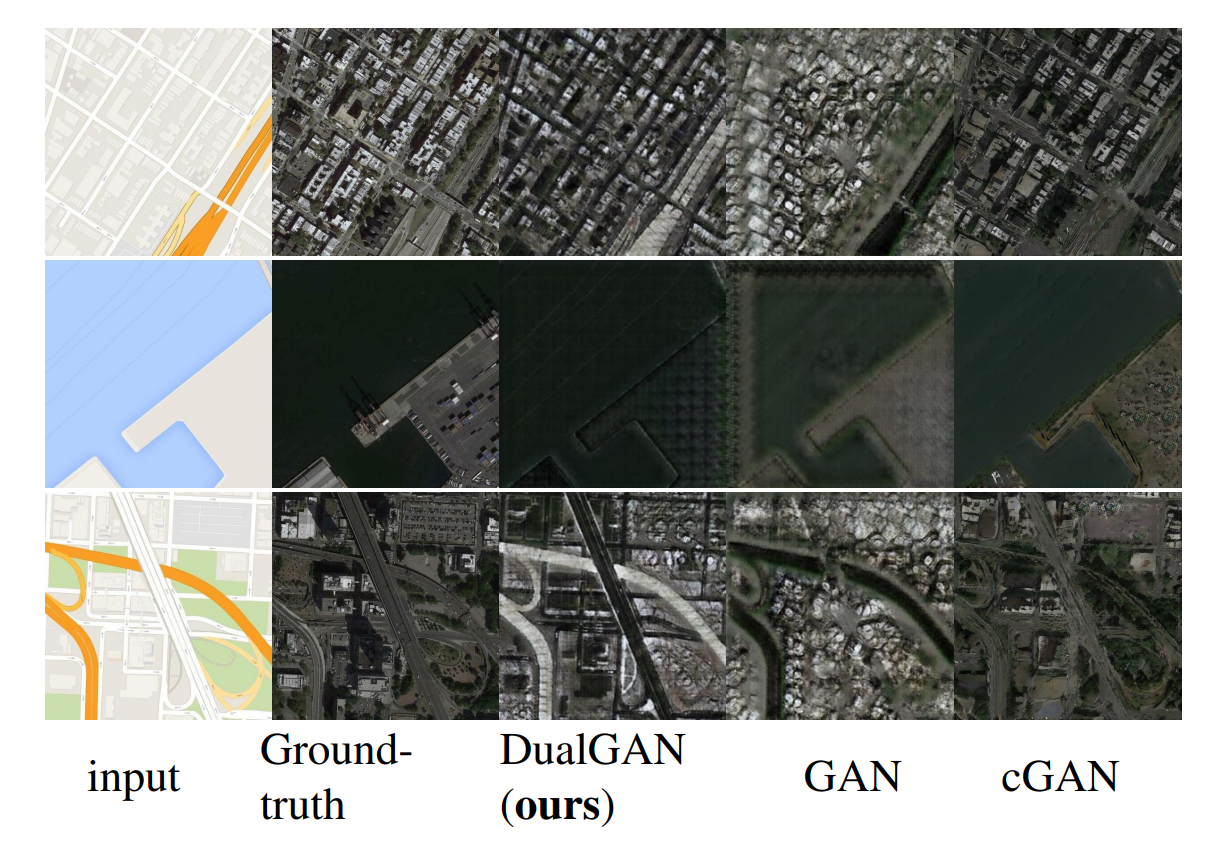
图8:地图→航拍照片转换的结果。我们的方法在没有对应信息的情况下,将橙色的州际高速公路映射为建筑物屋顶的亮色区域。尽管如此,我们的结果比GAN和cGAN更清晰。
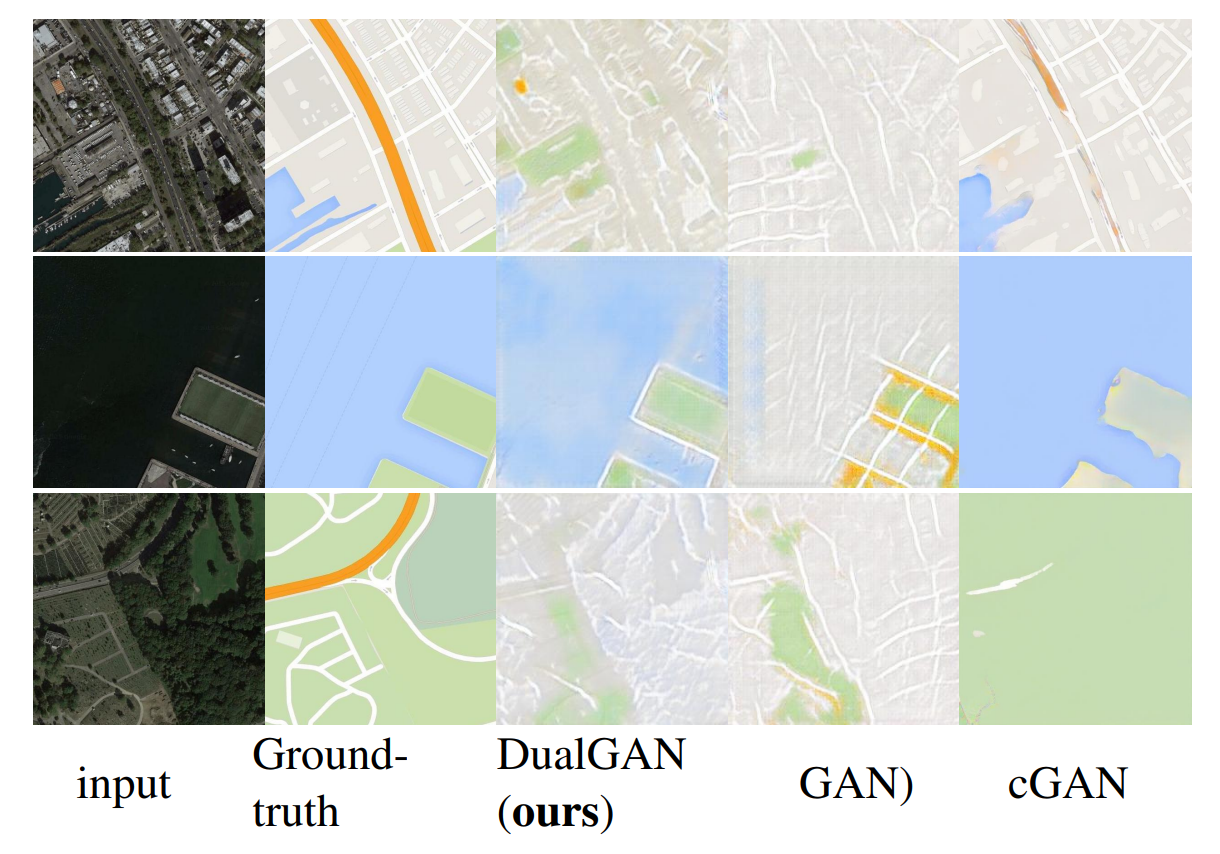
图9:航拍照片→地图转换的结果。DualGAN的表现优于GAN,但不及cGAN。在具备额外的像素对应信息的情况下,cGAN在标记局部道路方面表现非常好,但仍然无法检测州际高速公路。

图10:建筑立面→建筑标签转换的结果。虽然 cGAN 能正确标注窗户、门和阳台等各种建筑组件,但整体标签图像的细节和结构不如我们的输出结果。
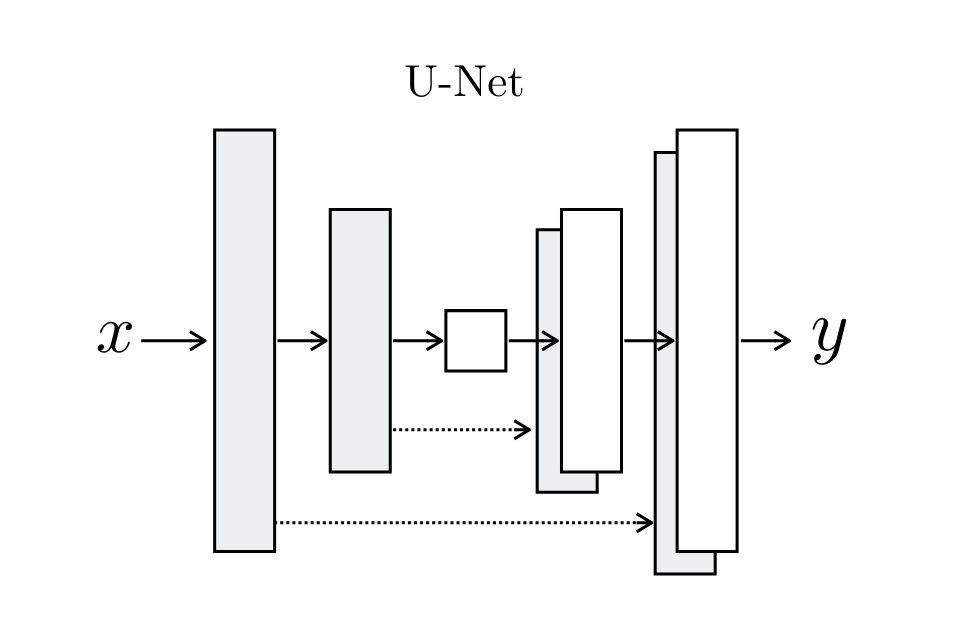
图11:U-Net结构
定量评估
为了定量评估我们的方法,我们通过Amazon Mechanical Turk(AMT,提供随需式、可扩展的人力 web 服务的平台)设置了两个用户研究任务。其中的 "材料感知 "测试用于评估材料转换结果,我们将所有材料转换任务的输出结果混合在一起,让参与者根据他们认为图像中的物体由哪种材料制成来选择最佳匹配。我们共有176张输出图像,每张图像由三位参与者评估。如果至少有一位参与者选择了目标材料类型,则该输出图像被评为成功。使用不同方法的各种材料转换结果的成功率总结在表1中。结果显示,DualGAN在很大程度上优于GAN。
| 任务 | DualGAN | GAN |
|---|---|---|
| 塑料→木材 | 1/11 | 0/11 |
| 木材→塑料 | 1/11 | 0/11 |
| 金属→石头 | 2/11 | 1/11 |
| 石材→金属 | 2/11 | 0/11 |
| 皮革→布料 | 4/11 | 2/11 |
| 织物→皮革 | 2/11 | 1/11 |
| 塑料→金属 | 6/11 | 3/11 |
| 金属→塑料 | 1/11 | 1/11 |
表 1:基于 AMT "材料感知 "测试的各种材料转移任务的成功率。每组转移结果中有 11 幅图像。如表所示,与 GAN 相比,所提出的双重学习机制明显提高了材料转移任务的成功率。
此外,我们还对素描(草图)→照片、标签图→建筑立面、地图→航拍照片和白天→夜晚的转换结果进行了AMT“真实性评分”评估。为了消除潜在的偏差,每次评估前,我们随机打乱真实照片和所有三种方法的输出,然后展示给参与者(MTurk 工人)。每张图片展示给3名参与者(MTurk 工人),他们根据合成照片的真实程度为图片打分。“真实性”评分范围从0(完全没有)、1(差)、2(可以接受)、3(好)到4(非常好)。然后计算各种任务中不同方法的平均分数,并显示在表2中。结果显示,DualGAN在所有任务中都击败了GAN,并且在两项任务中表现优于cGAN。这表明,cGAN对图像对之间的不对齐和不一致性容忍度较低,但额外的对应信息确实有助于它正确映射标签到颜色和纹理。
最后,我们计算了建筑立面→标签和航拍图→地图任务的分割精度:见表3和表4。对比结果显示,DualGAN的表现不如cGAN。这是预料之中的,因为在没有对应信息的情况下,很难推断出正确的标签。
| task | 平均真实性评分 DualGAN cGAN GAN 真实值 |
|---|---|
| 素描→照片 | 1.78 1.64 1.07 3.61 |
| 白天→夜晚 | 2.37 1.93 0.14 3.02 |
| 标签→建筑立面 | 1.90 2.65 1.40 3.34 |
| 地图→航拍图 | 2.55 2.91 1.89 3.17 |
表2:各种任务输出的平均AMT“真实性”评分。结果显示,DualGAN在所有任务中都优于GAN。在sketch→photo和day→night任务中,它也优于cGAN,但在label→facades和maps→aerial任务中仍然落后于cGAN。在后两项任务中,额外的图像对应信息能帮助cGAN将标签映射到正确的颜色/纹理。
| 每像素准确率 | 每类准确率 | 类别IOU | |
|---|---|---|---|
| DualGAN | 0.27 | 0.13 | 0.06 |
| cGAN | 0.54 | 0.33 | 0.19 |
| GAN | 0.22 | 0.10 | 0.05 |
表3:建筑立面→建筑标签任务的分割准确率。DualGAN优于GAN,但不如cGAN准确。这是因为没有对应信息,即使DualGAN正确地分割了一个区域,也可能无法为该区域分配正确的标签。
| 每像素准确率 | 每类准确率 | 类别IOU | |
|---|---|---|---|
| DualGAN | 0.42 | 0.22 | 0.09 |
| cGAN | 0.70 | 0.46 | 0.26 |
| GAN | 0.41 | 0.23 | 0.09 |
表4:航拍图→地图任务的分割准确率。DualGAN再次表现不佳。
结论
我们为通用图像转换提出了一种新颖的无监督双向学习框架。无监督特性使得它能够应用于更多现实世界的场景。实验结果表明,我们的DualGAN机制可以显著改进GAN在各种图像转换任务中的输出。在仅使用未标记数据的情况下,DualGAN就可以生成与只能用标记数据进行训练的cGAN【3】 相当甚至更好的输出结果。
另一方面,在涉及基于语义标签的某些应用中,我们的方法被cGAN【3】超越。这是由于缺乏像素和标签的对应信息,而这些信息无法仅从目标分布中推断出来。在未来,我们打算研究是否可以通过使用少量标记数据进行初始化来解决这一限制。
参考文献
[1] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017. 文章引用:目标 训练过程
[2] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. 文章引用:引言 生成式对抗网络 目标 定性评估
[3] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004, 2016.文章引用:摘要 引言 生成式对抗网络 网络配置 实验结果与评估 定性评估 结论
[4] P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Transactions on Graphics (TOG), 33(4):149, 2014.文章引用:实验结果与评估
[5] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.文章引用:目标
[6] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016.文章引用:摘要 引言 生成式对抗网络
[7] C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. In European Conference on Computer Vision, pages 702–716. Springer, 2016.文章引用:摘要 引言 生成式对抗网络 网络配置
[8] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431 3440, 2015.文章引用:引言
[9] M. Mathieu, C. Couprie, and Y. LeCun. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.文章引用:摘要 引言 生成式对抗网络
[10] M. Mirza and S. Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.文章引用:生成式对抗网络 网络配置
[11] G. Perarnau, J. van de Weijer, B. Raducanu, and J. M. Álvarez. Invertible conditional gans for image editing. arXiv preprint arXiv:1611.06355, 2016.文章引用:生成式对抗网络
[12] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. InProceedings of The 33rd International Conference on Machine Learning, volume 3, 2016. 文章引用:生成式对抗网络
[13] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 234–241. Springer, 2015.文章引用:
[14] L. Sharan, R. Rosenholtz, and E. Adelson. Material perception: What can you see in a brief glance? Journal of Vision, 9(8):784–784, 2009.文章引用:实验结果与评估
[15] Y. Taigman, A. Polyak, and L. Wolf. Unsupervised crossdomain image generation. arXiv preprint arXiv:1611.02200, 2016.文章引用:摘要 引言 生成式对抗网络
[16] T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 2012.文章引用:训练过程
[17] R. Tylecek and R. Šára. Spatial pattern templates for recogni- ˇ tion of objects with regular structure. In German Conference on Pattern Recognition, pages 364–374. Springer, 2013.文章引用:实验结果与评估
[18] X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. In European Conference on Computer Vision, pages 318–335. Springer, 2016.文章引用:摘要 引言 生成式对抗网络
[19] X. Wang and X. Tang. Face photo-sketch synthesis and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(11):1955–1967, 2009.文章引用:实验结果与评估
[20] Y. Xia, D. He, T. Qin, L. Wang, N. Yu, T.-Y. Liu, and W.-Y. Ma. Dual learning for machine translation. arXiv preprint arXiv:1611.00179, 2016.文章引用:摘要 引言 双向学习 目标 网络配置
[21] X. Yan, J. Yang, K. Sohn, and H. Lee. Attribute2image: Conditional image generation from visual attributes. In European Conference on Computer Vision, pages 776–791. Springer, 2016.文章引用:生成式对抗网络
[22] W. Zhang, X. Wang, and X. Tang. Coupled informationtheoretic encoding for face photo-sketch recognition. In Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, pages 513–520. IEEE, 2011. 文章引用:实验结果与评估



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)