Golang 指针
指针是一个代表着某个内存地址的值, 这个内存地址往往是在内存中存储的另一个变量的值的起始位置.
Go语言对指针的支持介于Java语言和 C/C++ 语言之间, 它既没有像Java那样取消了代码对指针的直接操作的能力, 也避免了 C/C++ 中由于对指针的滥用而造成的安全和可靠性问题.
指针地址和变量空间
Go语言保留了指针, 但是与C语言指针有所不同. 主要体现在:
- 默认值: nil.
- 操作符
&取变量地址,*通过指针访问目标对象. - 不支持指针运算, 不支持
->运算符, 直接用.访问目标成员.
先来看一段代码:
package main
import "fmt"
func main(){
var x int = 99
var p *int = &x
fmt.Println(p)
}
当我们运行到 var x int = 99 时, 在内存中就会生成一个空间, 这个空间我们给它起了个名字叫 x, 同时, 它也有一个地址, 例如: 0xc00000a0c8. 当我们想要使用这个空间时, 我们可以用地址去访问,也可以用我们给它起的名字 x 去访问.
继续运行到 var p *int = &x 时, 我们定义了一个指针变量 p , 这个 p 就存储了变量 x 的地址.
所以, 指针就是地址, 指针变量就是存储地址的变量.
接着, 我们更改 x 的内容:
package main
import "fmt"
func main() {
var x int = 99
var p *int = &x
fmt.Println(p)
x = 100
fmt.Println("x: ", x)
fmt.Println("*p: ", *p)
*p = 999
fmt.Println("x: ", x)
fmt.Println("*p: ", *p)
}
可以发现, x 与 *p 的结果一样的.
其中, *p 称为 解引用 或者 间接引用.
*p = 999 是通过借助 x 变量的地址, 来操作 x 对应的空间.
不管是 x 还是 *p , 我们操作的都是同一个空间.
栈帧的内存布局
首先, 先来看一下内存布局图, 以 32位 为例.
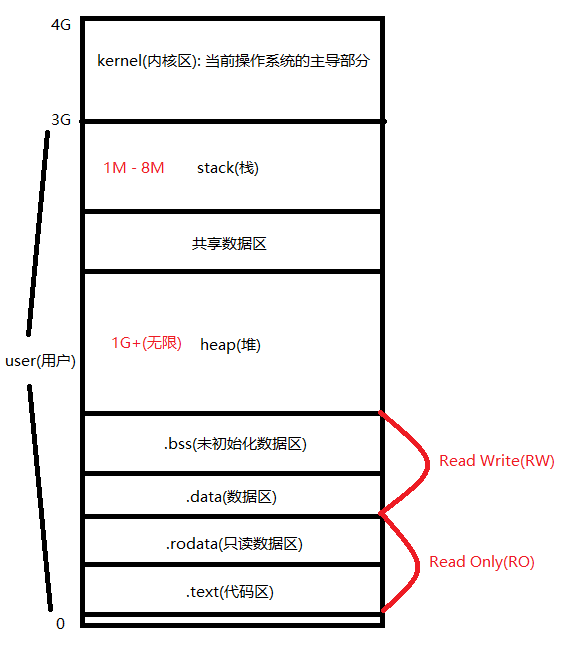
其中, 数据区保存的是初始化后的数据.
上面的代码都存储在栈区. 一般 make() 或者 new() 出来的都存储在堆区
接下来, 我们来了解一个新的概念: 栈帧.
栈帧: 用来给函数运行提供内存空间, 取内存于 stack 上.
当函数调用时, 产生栈帧; 函数调用结束, 释放栈帧.
那么栈帧用来存放什么?
- 局部变量
- 形参
- 内存字段描述值
其中, 形参与局部变量存储地位等同
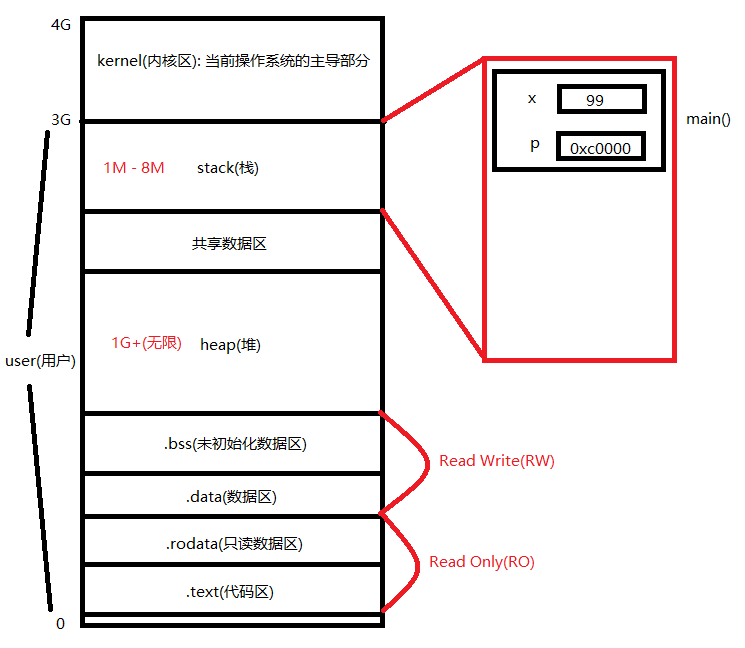
当我们的程序运行时, 首先运行 main(), 这时就产生了一个栈帧.
当运行到 var x int = 99 时, 就会在栈帧里面产生一个空间.
同理, 运行到 var p *int = &x 时也会在栈帧里产生一个空间.
如下图所示:
我们增加一个函数, 再来研究一下.
package main
import "fmt"
func test(m int){
var y int = 66
y += m
}
func main() {
var x int = 99
var p *int = &x
fmt.Println(p)
x = 100
fmt.Println("x: ", x)
fmt.Println("*p: ", *p)
test(11)
*p = 999
fmt.Println("x: ", x)
fmt.Println("*p: ", *p)
}
如下图所示, 当运行到 test(11) 时, 会继续产生一个栈帧, 这时 main() 产生的栈帧还没有结束.
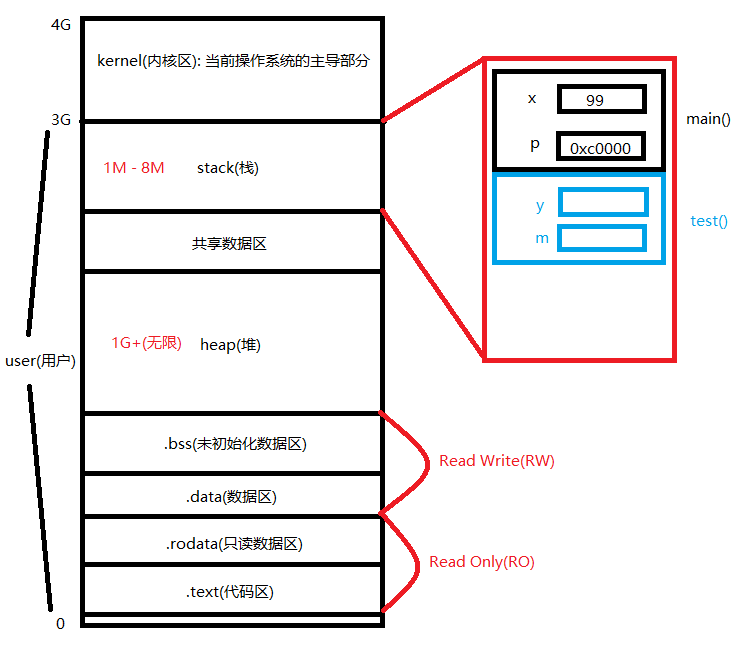
当 test() 运行完毕时, 就会释放掉这个栈帧.
空指针与野指针
空指针: 未被初始化的指针.
var p *int
这时如果我们想要对其取值操作 *p, 会报错.
野指针: 被一片无效的地址空间初始化.
var p *int = 0xc00000a0c8
指针变量的内存存储
表达式 new(T) 将创建一个 T 类型的匿名变量, 所做的是为 T 类型的新值分配并清零一块内存空间, 然后将这块内存空间的地址作为结果返回, 而这个结果就是指向这个新的 T 类型值的指针值, 返回的指针类型为 *T.
new() 创建的内存空间位于heap上, 空间的默认值为数据类型的默认值. 如: p := new(int) 则 *p 为 0.
package main
import "fmt"
func main(){
p := new(int)
fmt.Println(p)
fmt.Println(*p)
}
这时 p 就不再是空指针或者野指针.
我们只需使用 new() 函数, 无需担心其内存的生命周期或者怎样将其删除, 因为Go语言的内存管理系统会帮我们打理一切.
接着我们改一下*p的值:
package main
import "fmt"
func main(){
p := new(int)
*p = 1000
fmt.Println(p)
fmt.Println(*p)
}
这个时候注意了, *p = 1000 中的 *p 与 fmt.Println(*p) 中的 *p 是一样的吗?
大家先思考一下, 然后先来看一个简单的例子:
var x int = 10
var y int = 20
x = y
好, 大家思考一下上面代码中, var y int = 20 中的 y 与 x = y 中的 y 一样不一样?
结论: 不一样
var y int = 20 中的 y 代表的是内存空间, 我们一般把这样的称之为左值; 而 x = y 中的 y 代表的是内存空间中的内容, 我们一般称之为右值.
x = y 表示的是把 y 对应的内存空间的内容写到x内存空间中.
等号左边的变量代表变量所指向的内存空间, 相当于写操作.
等号右边的变量代表变量内存空间存储的数据值, 相当于读操作.
在了解了这个之后, 我们再来看一下之前的代码.
p := new(int)
*p = 1000
fmt.Println(*p)
所以, *p = 1000 的意思是把1000写到 *p 的内存中去;
fmt.Println(*p) 是把 *p的内存空间中存储的数据值打印出来.
所以这两者是不一样的.
如果我们不在main()创建会怎样?
func foo() {
p := new(int)
*p = 1000
}
我们上面已经说过了, 当运行 foo() 时会产生一个栈帧, 运行结束, 释放栈帧.
那么这个时候, p 还在不在?
p 在哪? 栈帧是在栈上, 而 p 因为是 new() 生成的, 所以在 堆 上. 所以, p 没有消失, p 对应的内存值也没有消失, 所以利用这个我们可以实现传地址.
对于堆区, 我们通常认为它是无限的. 但是无限的前提是必须申请完使用, 使用完后立即释放.
函数的传参
明白了上面的内容, 我们再去了解指针作为函数参数就会容易很多.
传地址(引用): 将地址值作为函数参数传递.
传值(数据): 将实参的值拷贝一份给形参.
无论是传地址还是传值, 都是实参将自己的值拷贝一份给形参.只不过这个值有可能是地址, 有可能是数据.
所以, 函数传参永远都是值传递.
了解了概念之后, 我们来看一个经典的例子:
package main
import "fmt"
func swap(x, y int){
x, y = y, x
fmt.Println("swap x: ", x, "y: ", y)
}
func main(){
x, y := 10, 20
swap(x, y)
fmt.Println("main x: ", x, "y: ", y)
}
结果:
swap x: 20 y: 10
main x: 10 y: 20
我们先来简单分析一下为什么不一样.
首先当运行 main() 时, 系统在栈区产生一个栈帧, 该栈帧里有 x 和 y 两个变量.
当运行 swap() 时, 系统在栈区产生一个栈帧, 该栈帧里面有 x 和 y 两个变量.
运行 x, y = y, x 后, 交换 swap() 产生的栈帧里的 xy 值. 这时 main() 里的 xy 没有变.
swap() 运行完毕后, 对应的栈帧释放, 栈帧里的x y 值也随之消失.
所以, 当运行 fmt.Println("main x: ", x, "y: ", y) 这句话时, 其值依然没有变.
接下来我们看一下参数为地址值时的情况.
传地址的核心思想是: 在自己的栈帧空间中修改其它栈帧空间中的值.
而传值的思想是: 在自己的栈帧空间中修改自己栈帧空间中的值.
注意理解其中的差别.
继续看以下这段代码:
package main
import "fmt"
func swap2(a, b *int){
*a, *b = *b, *a
}
func main(){
x, y := 10, 20
swap2(x, y)
fmt.Println("main x: ", x, "y: ", y)
}
结果:
main x: 20 y: 10
这里并没有违反 函数传参永远都是值传递 这句话, 只不过这个时候这个值为地址值.
这个时候, x 与 y 的值就完成了交换.
我们来分析一下这个过程.
首先运行 main() 后创建一个栈帧, 里面有 x y 两个变量.
运行 swap2() 时, 同样创建一个栈帧, 里面有 a b 两个变量.
注意这个时候, a 和 b 中存储的值是 x 和 y 的地址.
当运行到 *a, *b = *b, *a 时, 左边的 *a 代表的是 x 的内存地址, 右边的 *b 代表的是 y 的内存地址中的内容. 所以这个时候, main() 中的 x 就被替换掉了.
所以, 这是在 swap2() 中操作 main() 里的变量值.
现在 swap2() 再释放也没有关系了, 因为 main() 里的值已经被改了.
李培冠博客
欢迎访问我的个人网站:
李培冠博客:lpgit.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号