 6
6 大数据技术栈—如何成为一个优秀的大数据开发者
大数据技术栈全貌
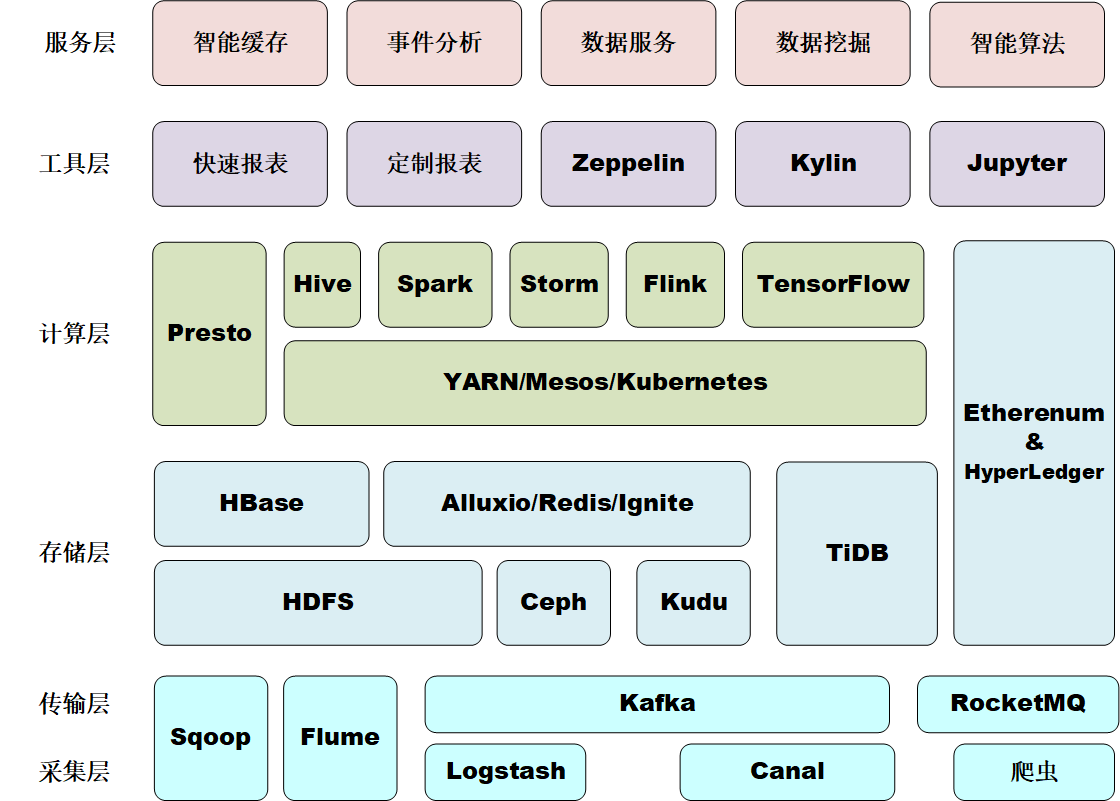
下面自底向上介绍各个层的主要项目。
1 采集层和传输层

-
Sqoop
在hadoop和关系型数据库之间转换数据。 -
Flume
Flume是一个分布式的高可用的数据收集、聚集和移动的工具。通常用于从其他系统搜集数据,如web服务器产生的日志,通过Flume将日志写入到Hadoop的HDFS中。

-
Canal
数据抽取是 ETL 流程的第一步。我们会将数据从 RDBMS 或日志服务器等外部系统抽取至数据仓库,进行清洗、转换、聚合等操作。在现代网站技术栈中,MySQL 是最常见的数据库管理系统,我们会从多个不同的 MySQL 实例中抽取数据,存入一个中心节点,或直接进入 Hive。市面上已有多种成熟的、基于 SQL 查询的抽取软件,如著名的开源项目 Apache Sqoop,然而这些工具并不支持实时的数据抽取。MySQL Binlog 则是一种实时的数据流,用于主从节点之间的数据复制,我们可以利用它来进行数据抽取。借助阿里巴巴开源的 Canal 项目,我们能够非常便捷地将 MySQL 中的数据抽取到任意目标存储中。
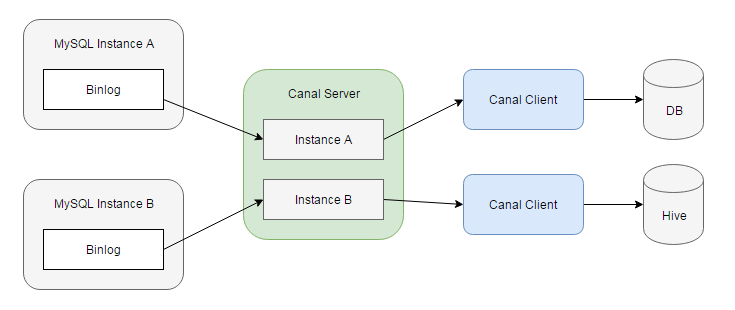
-
Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。 -
Kafka
消息队列,一个分布式流平台。 -
RocketMQ
阿里巴巴开源的消息队列。
2 存储层

-
HBase
HBase is the Hadoop database, a distributed, scalable, big data store. -
Alluxio/Redis/Ignite
Alluxio以内存为中心分布式存储系统,从下图可以看出, Alluxio主要有两大功能,第一提供一个文件系统层的抽象,统一文件系统接口,桥接储存系统和计算框架;第二通过内存实现对远程数据的加速访问。详情参考Alluxio document。
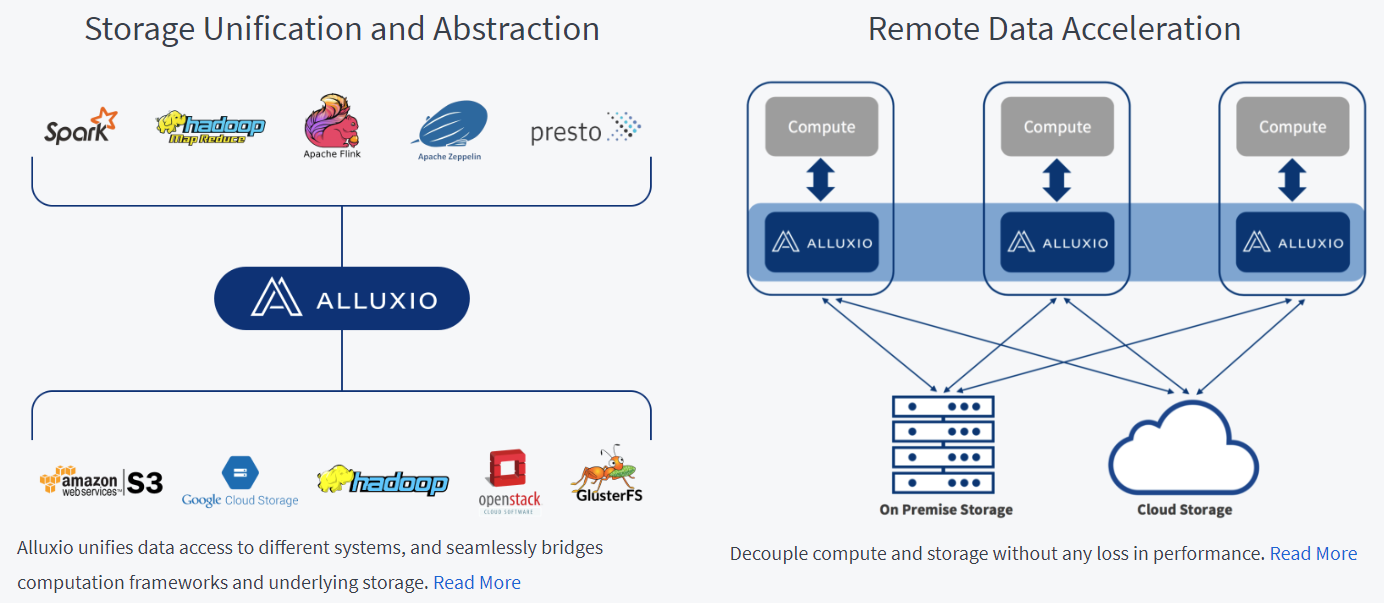
Redis是一个开源的内存键值数据库,相比于Memcache,支持丰富的数据结构。
Ignite是一个以内存为中心的分布式数据库,缓存和处理平台,用于事务,分析和流式工作负载,在PB级别的数据上提供接近内存速度访问数据。
从上述分析可知,Alluxio/Redis/Ignite主要都是通过内存来实现加速。
-
TiDB
TiDB私有PingCap开源的分布式NewSQL关系型数据库。NewSQL数据库有两个流派,分别是以Google为代表的Spanner/F1和以Amazon 为代表的Aurora(极光),目前国内做NewSQL数据库主要是参考Google的Spanner架构,Google Spanner也是未来NewSQL的发展趋势。具体请查阅相关资料,或者访问Youtube,观看黄旭东的分享。 -
HDFS
Hadoop的分布式文件系统。 -
Ceph
Linux中备受关注的开源分布式存储系统,除了GlusterFS,当属Ceph。目前Ceph已经成为RedHat旗下重要的分布式存储产品,并继续开源。Ceph提供了块储存RDB、分布式文件储存Ceph FS、以及分布式对象存储Radosgw三大储存功能,是目前为数不多的集各种存储能力于一身的开源存储中间件。 -
Kudu
Kudu是cloudera开源的运行在hadoop平台上的列式存储系统,拥有Hadoop生态系统应用的常见技术特性,运行在一般的商用硬件上,支持水平扩展,高可用,目前是Apache Hadoop生态圈的新成员之一(incubating)。
Kudu的设计与众不同,它定位于应对快速变化数据的快速分析型数据仓库,希望靠系统自身能力,支撑起同时需要高吞吐率的顺序和随机读写的应用场景,提供一个介于HDFS和HBase的性能特点之间的一个系统,在随机读写和批量扫描之间找到一个平衡点,并保障稳定可预测的响应延迟。可与MapReduce, Spark和其它hadoop生态系统集成。
3 计算层
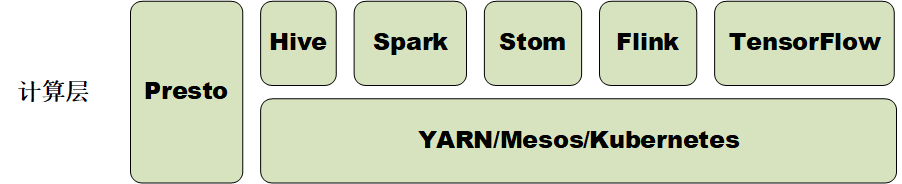
- Hive
Facebook 开源。Hive是一个构建在Hadoop上的数据仓库框架。Hive的设计目标是让精通SQL技能但Java编程技能相对较弱的分析师能对存放在Hadoop上的大规数据执行查询。
Hive的查询语言HiveQL是基于SQL的。任何熟悉SQL的人都可以轻松使用HiveSQL写查询。和RDBMS相同,Hive要求所有数据必须存储在表中,而表必须有模式(Schema),且模式由Hive进行管理。
类似Hive的同类产品:kylin druid SparkSQL Impala。
KylinApache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Druid 为监控而生的数据库连接池。
SparkSQL,Spark SQL is Apache Spark’s module for working with structured data.
Impala,Impala是Apache Hadoop的开源,本地分析数据库。 它由Cloudera,MapR,Oracle和Amazon等供应商提供。
-
Spark
Spark是一个分布式计算框架。 -
Storm
Storm是一个分布式的、高容错的实时计算系统。Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:①、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。②、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
-
TensorFlow
TensorFlow™ is an open source software library for high performance numerical computation. Its flexible architecture allows easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices. Originally developed by researchers and engineers from the Google Brain team within Google’s AI organization, it comes with strong support for machine learning and deep learning and the flexible numerical computation core is used across many other scientific domains. -
分布式资源调度
-
YARN, Apache YARN(Yet Another Resource Negotiator)是hadoop的集群资源管理系统。YARN在Hadoop2时被引入,最初是为了改善MapReduce的实现,但它具有足够的通用性,也支持其他的分布式计算模式。
-
Mesos
Mesos 最初由 UC Berkeley 的 AMP 实验室于 2009 年发起,遵循 Apache 协议,目前已经成立了 Mesosphere 公司进行运营。Mesos 可以将整个数据中心的资源(包括 CPU、内存、存储、网络等)进行抽象和调度,使得多个应用同时运行在集群中分享资源,并无需关心资源的物理分布情况。
如果把数据中心中的集群资源看做一台服务器,那么 Mesos 要做的事情,其实就是今天操作系统内核的职责:抽象资源 + 调度任务。Mesos 项目是 Mesosphere 公司 Datacenter Operating System (DCOS) 产品的核心部件。 -
Kubernetes
Kubernetes是Google 2014年推出的开源容器集群管理系统,基于Docker构建一个容器调度服务,为容器化的应用提供资源调度、部署运行、均衡容灾、服务注册、扩容缩容等功能。 -
Presto
Presto是FaceBook开源的一个开源项目。Presto被设计为数据仓库和数据分析产品:数据分析、大规模数据聚集和生成报表。这些工作经常通常被认为是线上分析处理操作。
Presto通过使用分布式查询,可以快速高效的完成海量数据的查询。如果你需要处理TB或者PB级别的数据,那么你可能更希望借助于Hadoop和HDFS来完成这些数据的处理。作为Hive和Pig(Hive和Pig都是通过MapReduce的管道流来完成HDFS数据的查询)的替代者,Presto不仅可以访问HDFS,也可以操作不同的数据源,包括:RDBMS和其他的数据源(例如:Cassandra)。 -
其他(区块链框架)
- Etherenum, 以太坊
- HyperLedger,超级账本
4 工具层和服务层

-
Zeppelin
Web-based notebook that enables data-driven,
interactive data analytics and collaborative documents with SQL, Scala and more. -
Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
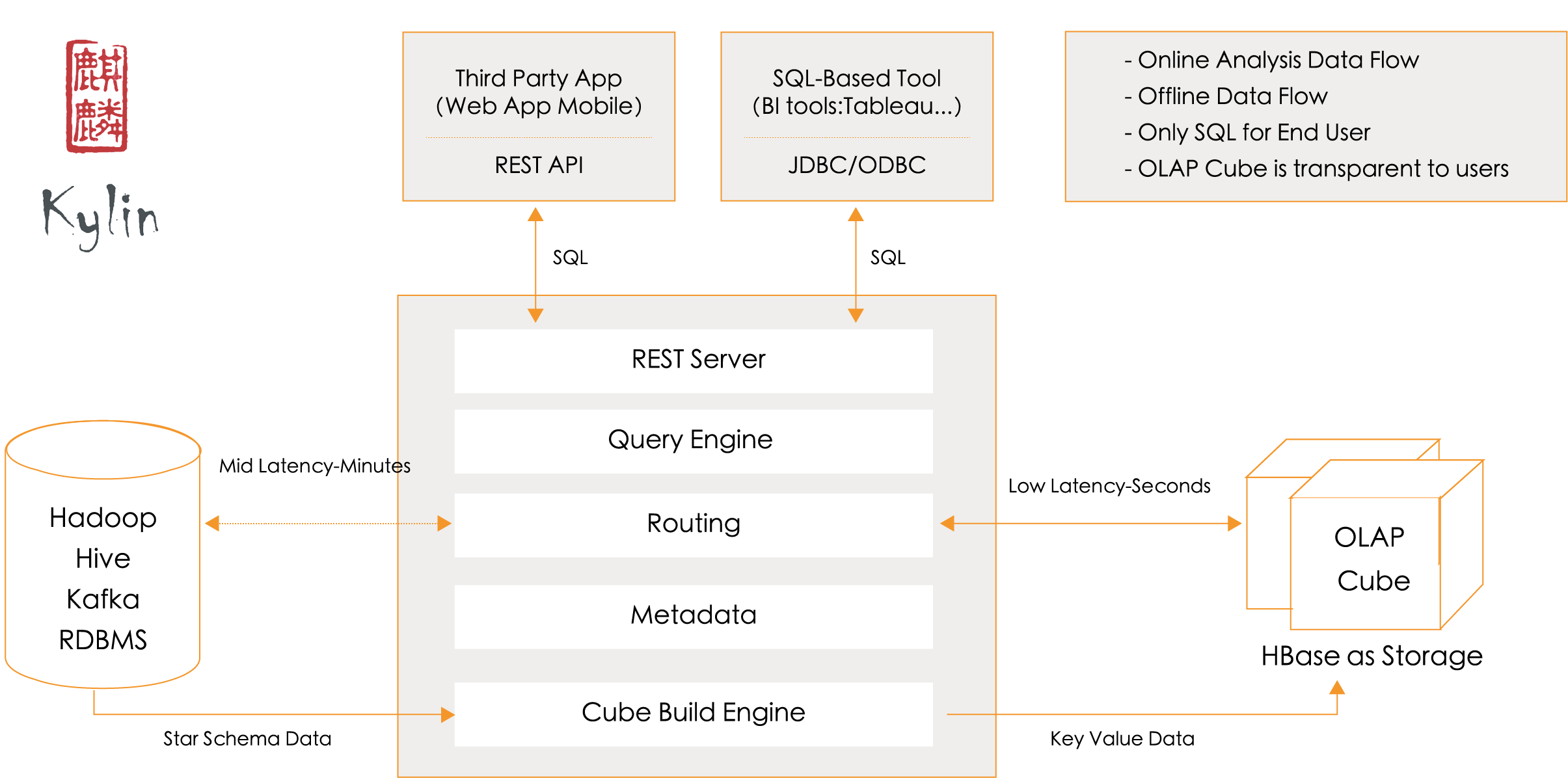
-
Jupyter
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
参考
https://blog.csdn.net/guoxiaojie_415/article/details/82317315

 浙公网安备 33010602011771号
浙公网安备 33010602011771号