爬虫遭遇521状态码
起因:工作中爬取页面遭遇521状态码
scrapy中遭遇521状态码,会被无视,而不会被爬虫处理。

通过F12开发者工具 可知

通过在下载器中间件的查看,可以得知是可以在process_response中获取response.text

实际上是js代码,一段不规则加密代码和一段可读代码。
通过将这段代码中的eval替换为console.log放到html文件中
可以在控制台得到
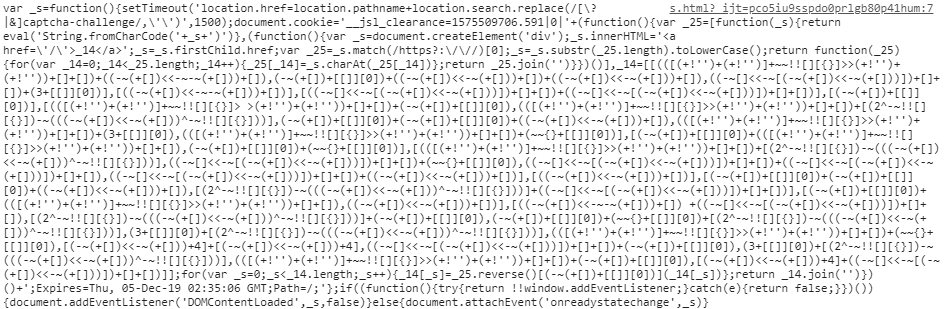
又是一段类似的代码,但是已经可以清晰的看到cookie相关的东西。
解决方法就是将‘document.cookie=’替换为'return ',其他的根据报错替换
就我这一个页面的解决方案:
将上一步js代码替换成下图 url为访问界面url

即可获得cookie
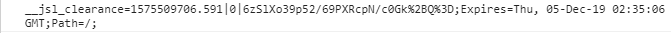
利用这一个cookie和访问此页面时响应头中的set-cookie组合 获得最终cookie
headers要模仿浏览器中的请求头。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号