
scrapy从入门到放弃 学习项目3
以宝马5系列为例CrawlSpider爬取汽车之家汽车各方面高清图片
扩展ImagesPipeline,实现文件格式的自定义保存


from baomax5.items import Baomax5Item from scrapy.spiders import CrawlSpider, Rule from scrapy.linkextractors import LinkExtractor class BaomaxSpider(CrawlSpider): name = 'baomax' allowed_domains = ['car.autohome.com.cn'] start_urls = ['https://car.autohome.com.cn/pic/series/65.html'] rules = ( Rule(LinkExtractor(allow=r'https://car.autohome.com.cn/pic/series/65-.+'), callback='parse_item', follow=True), ) def parse_item(self, response): car_kind = response.xpath('//div[@class="cartab-title"]/h2/a/text()').get() title = response.xpath('//div[@class="uibox"]/div/text()').get() image_urls = response.xpath('//div[@class="uibox"]/div/ul/li/a/img/@src').getall() urls = list(map(lambda url: response.urljoin(url.replace('t_', '')), image_urls)) items = Baomax5Item(car_title=car_kind, title=title, image_urls=urls) yield items
class BaomaximagePipeline(ImagesPipeline): def get_media_requests(self, item, info): request_objs = super().get_media_requests(item, info) for request_obj in request_objs: request_obj.item = item return request_objs def file_path(self, request, response=None, info=None): path = super().file_path(request, response, info) item_path = os.path.join(IMAGES_STORE, request.item['car_title']) if not os.path.exists(item_path): os.mkdir(item_path) title_path = os.path.join(item_path, request.item['title']) if not os.path.exists(title_path): os.mkdir(title_path) image_name = path.replace('full/', '') image_path = os.path.join(title_path, image_name) return image_path
ImagePipeline的使用 item中必须有image_urls,images字段,images不需要传参。
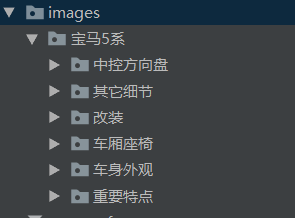
保存格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号