4 pytorch基础
书《深度学习之PyTorch实战计算机视觉》第六章
这次主要记录三部分内容:
自动梯度
- 向后传播自动化
自定义传播函数
- 重写向前传播和向后传播
模型搭建和参数优化
自动梯度
实现对模型中后向传播梯度的自动计算,后向传播自动化(loss.backward)
torch.autograd实现后向传播中的链式求导
Variable类对我们定义的Tensor数据类型进行封装。用X代表我们选中的节点,是一个Variable对象,那么X.data代表Tensor数据类型的变量,X.grad是Variable类型的变量,想要访问梯度值需要使用X.grad.data
loss.backward()是后向传播计算部分,自动计算每个节点的梯度并根据需求进行保留
import torch from torch.autograd import Variable batch_n = 100 hidden_layer = 100 input_data = 1000 output_data = 10 x = Variable(torch.randn(batch_n, input_data), requires_grad = False) y = Variable(torch.randn(batch_n, output_data), requires_grad = False) w1 = Variable(torch.randn(input_data, hidden_layer), requires_grad = True) #权重1是1000*100 w2 = Variable(torch.randn(hidden_layer, output_data), requires_grad = True)#权重2是100*10 epoch_n = 20 learning_rate = le-6 for epoch in range(epoch_n): y_pred = x.mm(w1).clamp(min=0).mm(w2) loss = (y_pred-y).pow(2).sum() print("Epoch:{}, Loss:{:.4f}".format(epoch, loss.data[0])) loss.backward() w1.data -=learning_rate*w1.grad.data w2.data -=learning_rate*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_()
自定义传播函数
torch.nn.Module重写前向传播forward和后向传播backward
import torch from torch.autograd import Variable batch_n = 100 hidden_layer = 100 input_data = 1000 output_data = 10 '''相比于前面代码添加部分''' class Model(torch.nn.module): def __init__(self): super(Module, self).__init__() def forward(self, input, w1, w2): #实现向前传播矩阵运算 x = torch.mm(x, w1) x = torch.clamp(x, min=0) x = torch.mm(x, w2) return x def backward(self): #实现向后传播自动梯度计算 pass model = Model() ''' 上面模型搭建好了,下面对模型进行训练和参数优化 ''' x = Variable(torch.randn(batch_n, input_data), requires_grad = False) y = Variable(torch.randn(batch_n, output_data), requires_grad = False) w1 = Variable(torch.randn(input_data, hidden_layer), requires_grad = True) w2 = Variable(torch.randn(hidden_layer, output_data), requires_grad = True) epoch_n = 20 learning_rate = le-6 for epoch in range(epoch_n): y_pred = model(x, w1, w2) #有改动,原来是x.mm(w1).clamp(min=0).mm(w2) loss = (y_pred-y).pow(2).sum() print("Epoch:{}, Loss:{:.4f}".format(epoch, loss.data[0])) loss.backward() w1.data -=learning_rate*w1.grad.data w2.data -=learning_rate*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_()
模型搭建和参数优化
torch.nn包
- torch.nn.Sequential
序列容器,通过嵌套各种类,实现对网络模型的搭建,参数会按照我们定义好的序列自动传递下去
- torch.nn.Linear
线性层。参数有三个,分别是输入特征数,输出特征数和是否使用偏置,偏置参数是一个布尔值,默认为True,即使用偏置。
- torch.nn.ReLU
非线性激活函数,在定义时默认不需要传入参数。除此之外,还包括PReLU,LeakyReLU,Tanh,Sigmod,Softmax等。
- 损失函数
包括:
(1)torch.nn.MSELoss:使用均方误差函数计算损失值

(2)torch.nn.L1Loss:使用平均绝对误差计算损失值
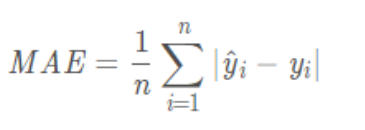
(3)torch.nn.CrossEntropyLoss:计算交叉熵
信息量:它是用来衡量一个事件的不确定性的;一个事件发生的概率越大,不确定性越小,则它所携带的信息量就越小。熵:它是用来衡量一个系统的混乱程度的,代表一个系统中信息量的总和;信息量总和越大,表明这个系统不确定性就越大交叉熵:它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出,概率分布q为实际输出, 为交叉熵,则
但是Pytorch中计算的交叉熵并不是采用上式,而是下面这个
torch.optim包
实现神经网络权重参数优化更新自动化。该包提供了许多方法,SGD,AdaGrad,RMSProp,Adam等。
接下来使用自动化的优化函数对前面的代码进行替换
import torch from torch.autograd import Variable #设置参数 batch_n = 100 hidden_layer = 100 input_data = 1000 output_data = 10 x = Variable(torch.randn(batch_n, input_data), requires_grad = False) y = Variable(torch.randn(batch_n, output_data), requires_grad = False) #构建模型 models = torch.nn.Sequential( torch.nn.Linear(input_data, hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer, output_data) ) #设置超参数 epoch_n = 20 learning_rate = le-6 #定义损失函数和权重优化参数 loss_fn = torch.nn.MSELoss() optimzer = torch.optim.Adam(models.parameters(), lr = learning_rate) for epoch in range(epoch_n): y_pred = models(x) loss = loss_fn(y_pred, y) #有改动 loss = (y_pred-y).pow(2).sum() print("Epoch:{}, Loss:{:.4f}".format(epoch, loss.data[0])) optimer.zero_grad() #实现模型参数梯度归零,代替前面w1.grad.data.zero_()和w2 loss.backward() optimer.step() #实现梯度更新,代替前面w1.data -=learning_rate*w1.grad.data和w2
这一部分就记录到这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号