
Analyzing I/O performance in Linux
Monitoring and analyzing performance is an important task for any sysadmin. Disk I/O bottlenecks can bring applications to a crawl. What are IOPS? Should I use SATA, SAS, or FC? How many spindles do I need? What RAID level should I use? Is my system read or write heavy? These are common questions for anyone embarking on an disk I/O analysis quest. Obligatory disclaimer: I do not consider myself an expert in storage or anything for that mater. This is just how I have done I/O analysis in the past. I welcome additions and corrections. I believe it’s also important to note that this analysis is geared toward random operations than sequential read/write workloads.
Let’s start at the very beginning … a very good place to start. Hey it worked for Julie Andrews … So what are IOPS? They are input output (I/O) operations measured in seconds. It’s good to note that IOPS are also referred to as transfers per second (tps). IOPs are important for applications that require frequent access to disk. Databases, version control systems, and mail stores all come to mind.
Great so now that I know what IOPS are how do I calculate them? IOPS are a function of rotational speed (aka spindle speed), latency and seek time. The equation is pretty simple, 1/(seek + latency) = IOPS. Scott Lowe has a good example on his techreplublic.com blog.
Sample drive:
- Model: Western Digital VelociRaptor 2.5″ SATA hard drive
- Rotational speed: 10,000 RPM
- Average latency: 3 ms (0.003 seconds)
- Average seek time: 4.2 (r)/4.7 (w) = 4.45 ms (0.0045 seconds)
Calculated IOPS for this disk: 1/(0.003 + 0.0045) = about 133 IOPS
It’s great to know how to calculate a disks IOPS but for the most part you can get by with commonly accepted averages. Of course sources vary but from what I have seen.
Rotational Speed (rpm) IOPS 5400 50-80 7200 75-100 10k 125-150 15k 175-210
Should I use SATA, SAS or FC? That’s a loaded question. As with most things the answer is “depends”. I don’t want to get into the SATA vs SAS debate you can do your own research and make your own decisions based on your needs, but I will point out a few things.
- SATA only gets up to 10k (at the time of this writing)
- SATA is only 1/2 duplex (From Tomak in comments)
- Differences in reliability (MTBF, BER) interesting article on Real Life Raid Reliability
- See differences in Native Command Queuing (NCQ) and Command Tag Queuing (CTQ)
These factors are key considerations when choosing what kind of drives to use.
What RAID level should I use? You know what IOPS are, how to calculate them and determined what kind of drives to use, the next logical question is commonly RAID 5 vs RAID 10. There is difference in reliability, especially as the number of drives in your raid-set increases but that is outside the scope of this post.
| Raid Level | Write Operations | Read Operations | Notes |
| 0 | 1 | 1 | Write/Read: high throughput, low CPU utilization, no redundancy |
| 1 | 2 | 1 | Write: only as fast as single driveRead: Two read schemes available. Read data from both drives, or data from the drive that returns it first. One is higher throughput the other is faster seek times. |
| 5 | 4 | 1 | Write: Read-Modify-Write requires two reads and two writes per write request. Lower throughput higher CPU if the HBA doesn’t have a dedicated IO processor.Read-Modify-Write requires two reads and two writes per write request. Lower throughput higher CPU if the HBA doesn’t have a dedicated IO processor.Read: High throughput low CPU utilization normally, in a failed state performance falls dramatically due to parity calculation and any rebuild operations that are going on. |
| 6 | 5 | 1 | Write: Read-Modify-Write requires three reads and three writes per write request. Do not use a software implementation if it is availableRead: High throughput low CPU utilization normally, in a failed state performance falls dramatically due to parity calculation and any rebuild operations that are going on. |
As you can see in the table above, writes are where you take your performance hit. Now that the penalty or RAID factor is known for different raid levels we can get a good estimate of the theoretical maximum IOPS for a RAID set (excluding caching of course). To do this you take the product of the number of disks and IOPS per disk divided by the sum of the %read workload and the product of the raid factor (see write operations column) and %write workload.
Here is the equation:
d = number of disks
dIOPS = IOPS per disk
%r = % of read workload
%w = % of write workload
F = raid factor (write operations column)
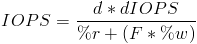
Wait a second, where am I supposed to get %read and %write from?
You need to examine your workload. I usually turn to my favorite statistics collector, sysstat. sar -d -p will report activity for each block device and pretty print the device name. I am assuming you already know what block device you are looking to analyze but if your looking for the busiest device just look in the tps column. the rd_sec/s and wr_sec/s columns display number of sectors read/written from/to the device. To get the percentage of read or writes divide rd_sec/s by the sum of rd_sec/s and wr_sec/s.
The equations:

An example from my workstation:
Average for sdb rd_sec/s = 1150.80
Average for sdb wr_sec/s = 1166.53
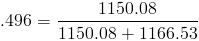
As you can see my workstation read/write workload is pretty balanced at 49.6% read, and 50.3% write. Compare that to a cvs server (don’t get me started on how bad cvs is, its just something I have to deal with).
Average for sdb rd_sec/s = 27.78k
Average for sdb wr_sec/s = 2.07k
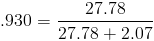
This server workload is extremely high on reads. Ok time to analyze the performance.
In and of itself being a heavy read workload is not a problem. My problem is user complaints of slowness. I note (again from sysstat collected metrics) that the tps or average IOPS on this device is about 574. Again thats not an issue in and of itself, we need to know what we can expect from its subsystem. This device happens to be SAN based storage. The raid set its on is comprised of 4 10kRPM FC drives in a raid 10. Remember from the table above that IOPS for a 10kRPM drive are in the 125-150ish range. We need to calculate the expected IOPS from that raid set using the IOPS equation above, our measured workloads for read/write, the number of disks, and the raid level (10 and 1 are treated the same).
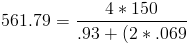
Using the high end of the scale for 10kRPM IOPS per drive results in a maximum theoretical IOPS of 561.79, thats pretty close to what I am observing (remember cache is not taken into account). So based on these numbers it looks like my storage subsystem is saturated. I guess I better add some spindles. Unfortunately there is no historical data for this system so I have no way of knowing how many tps I need to aim for.
Don’t get stuck where I am and have to guess how many spindles need to be added to reduce the pain, start recording your trends now! Even better, once you start collecting your statistical information go ahead and set an alert for 65% or 70% utilization of theoretical max IOPS for an extended period as well as increasingly bothersome alerts going up from there. It’s never good to have to react to performance issues, always better to be proactive. There was absolutely nothing wrong with the sizing of this example raid set 2-4 years ago. Had it been under monitoring the entire time with proper thresholds set a proper plan could have been made, and spindles could have been added before causing users any pain.
If you want to use sysstat like I did, you might find this Nagios plug-in that I wrote helpful check_sar_perf. I use it with Zenoss, but it could be tied into any NMS that records the performance data from a Nagios plug-in.
Go forth, collect, analyze and plan so your users aren’t calling you with issues.
- http://wiki.horde.org/HardwareRequirements
- http://don.blogs.smugmug.com/2007/10/08/hdd-iops-limiting-factor-seek-or-rpm/
- http://blogs.techrepublic.com.com/datacenter/?p=2182
- http://www.sqlservercentral.com/blogs/sqlmanofmystery/archive/2009/12/07/fundamentals-of-storage-systems-raid-an-introduction.aspx
- http://blog.aarondelp.com/2009/10/its-now-all-about-iops.html
- http://adamstechblog.com/2009/02/10/how-to-calculate-iops-ios-per-second/
- http://www.performancewiki.com/diskio-tuning.html
- http://vmtoday.com/2009/12/storage-basics-part-i-intro/
- http://vmtoday.com/2009/12/storage-basics-part-ii-iops/
- http://vmtoday.com/2010/01/storage-basics-part-iii-raid/
- http://vmtoday.com/2010/01/storage-basics-part-iv-interface/
- http://vmtoday.com/2010/03/storage-basics-part-v-controllers-cache-and-coalescing/
- http://vmtoday.com/2010/04/storage-basics-part-vi-storage-workload-characterization/
- http://www.codecogs.com/components/equationeditor/equationeditor.php


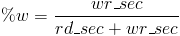{kind=link}
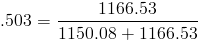{kind=link}
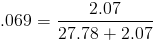{kind=link}