


python笔记
print(" ") #输出字符串
print(520) print(3+1)
输出到文件里
fp = open('D:/text.txt', 'a+') # 'a+'的意思是如果文件不存在就创建一个并输出,存在的话就在文件里输出一次 print("hello world", file = fp) fp.close()
print('hello', 'world') // hello world
转义字符
\n 换行
\r 回车
\t 一个制表位
\b 退格
要想输出特殊字符时,在前面加上\
print('\'') # ' print('\\') # \
不希望转义字符在print中起作用,用r或R在’‘前
print(r'hello\nworld') # hello\nworld 注:最后一个字符不能是\, 会报错
变量的定义和使用
name = '媛' print(id(name)) #name的地址 print(type(name)) # name的类型 print(name) #name的内容
字符串
print('hello world') printf("hello world") #单引号和双引号一样,都表示字符串,只能在一行输出 print("""hello world""")
print('''hello
world''')#三引号可以分隔两行来输出
input()返回值是str()类型
str() 将其他类型转换成字符串类型 ' ' 也有同样的效果
int()将其他类型(字符串必须为纯数字且数字为整数)转换成整数类型
float()将其他类型(字符串必须为纯数字)转换成浮点类型
注释
# 是注释一行的
''' '''是注释多行的
算术运算符
print(11/2) #5.5
print(11//2) # 整除 5
print(2**3) # 2的3次方(幂运算)
print(-9//4) # -3 向下取整
print(-9%4) # 3 余数 = 被除数 - 除数 * 商 -9-4*(-3)=3
print(9%-4) #-3 9-(-4)*(-3)
赋值运算符
a,b=10,20 # a= 10, b = 20 a, b = b, a #交换a,b的值,不需要中间变量
布尔运算符
and (与)
or (或)
not (非)
s = "hello world" print('w' in s) #in是查询在没在s里面 print('w' not in s)
分支结构_多分支结构
#if -- elif -- else的使用方法
else
while--else 时用break才能不执行else 语句里的内容。否则当while里的条件不满足时,就会执行else里的语句
for--in--else同理
列表
lst = list(["hello", "world", "99"]) print(lst[0], lst[-2]) # list特点:可以多类型混合
# 可以储存重复数据
# 从前往后索引是0,1,2... # 从后往前索引是-1,-2,-3...
index()
当有搜索的元素在list中有多个时,只返回第一个的位置
index(" ",1, 3) #在1到2位置中查找元素
切片操作
list[start:stop:step]
lst = ["hello", "world", "99", "hello"] print(lst[1:3:1]) # ['world', '99']
lis[1:3]省略step默认为1
step可以为负数
省略start时,默认从list头部开始
省略stop时,默认到list尾部
添加操作
append() 向list末尾增加一个数
lst = list(["hello", "world", "99", "hello"]) lst.append(10) print(lst) # ['hello', 'world', '99', 'hello', 10]
lst = list(["hello", "world", "99", "hello"]) lst1 = [10, 20, 30] lst.append(lst1) print(lst) # ['hello', 'world', '99', 'hello', [10, 20, 30]]
#当数为列表时,用append()当作一个数添加进去了
extend() 向list末尾添加至少一个元素
lst = list(["hello", "world", "99", "hello"]) lst1 = [10, 20, 30] lst.extend(lst1) print(lst) # ['hello', 'world', '99', 'hello', 10, 20, 30]
# 当数为列表时,用extend()把list1的每个元素加到lst中
insert() 向list中任意位置插入一个元素
lst = [10, 20, 30] lst.insert(1, 100) #向位置1插入100这个元素 print(lst)
# [10, 100, 20, 30]
切片操作 向任意位置加入元素
lst = [10, 20, 30] lst1 = ["hello", "world"] lst[1:] = lst1 print(lst) # [10, 'hello', 'world']
删除操作
remove() 移除某一个元素,当有多个重复元素时,只移走元素出现的第一个
lst = [10, 20, 30, 40, 50, 10] lst.remove(10) print(lst) # [20, 30, 40, 50, 10]
pop() 根据索引移除元素
lst = [10, 20, 30, 40, 50, 10] lst.pop(2) print(lst) # [10, 20, 40, 50, 10]
lst = [10, 20, 30, 40, 50, 10] lst.pop() #默认移除最后一个元素 print(lst) # [10, 20, 30, 40, 50]
切片操作
clear() 清楚list中的元素
del 将列表对象删除
修改操作
修改单个元素
list[2] = 100
修改多个元素
lst = [10, 20, 30, 40, 50, 10] lst[1:3] = [100, 200, 300, 400] #将位置1,2元素修改 print(lst) # [10, 100, 200, 300, 400, 40, 50, 10]
列表排序
lst = [20, 10, 11, 2, 55, 33] lst.sort() print(lst) # 默认升序排序 lst.sort(reverse = True) #倒序排序 print(lst)
列表生成式
lst = [i for i in range(1, 10)] print(lst) # [1, 2, 3, 4, 5, 6, 7, 8, 9] lst = [i*i for i in range(1, 10)] print(lst) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
字典
特点
1.key不允许重复
2.元素是无序的
创建
score = {"张三":100, "李四": 200, "王五":300}
print(score)
s = dict(name = "张三", age = 200) print(s) # {'name': '张三', 'age': 200}
获取
score = {"张三":100, "李四": 200, "王五":300}
print(score["张三"]) #100
print(score["张"]) # Keterror 会报错
#get()使用
print(score.get("张三")) #100
print(score.get("张")) #None 不会报错
判断元素是否在字典里
score = {"张三":100, "李四": 200, "王五":300}
print("张三" in score) # True
添加
score = {"张三":100, "李四": 200, "王五":300}
score["我"]= 50
print(score)
# {'张三': 100, '李四': 200, '王五': 300, '我': 50}
修改
score = {"张三":100, "李四": 200, "王五":300}
score["张三"] = 50
print(score) # {'张三': 50, '李四': 200, '王五': 300}
删除
score = {"张三":100, "李四": 200, "王五":300}
del score["张三"]
print(score) # {'李四': 200, '王五': 300}
清除
score = {"张三":100, "李四": 200, "王五":300}
score.clear()
print(score) # {}
获取字典视图
score = {"张三":100, "李四": 200, "王五":300}
s = score.keys() 获取键
s1 = scor.values() 获取值
s2 = score.items() 获取键值对
print(s) #dict_keys(['张三', '李四', '王五'])
print(type(s)) #<class 'dict_keys'>
# 类型转换
print(list(s)) #['张三', '李四', '王五']
zip()
item = ["张三", "李四", "王五"] value = [100, 200, 300] d = {item: value for item, value in zip(item, value)} # 用zip()函数创建一个字典 print(d)
元组
创建方式
it = ("hello", "world") #第一种 print(type(it)) print(it) it1 = tuple(("helle", "world")) #第二种 print(it1)
it3 = "hello", "world" print(type(it3)) print(it3) # <class 'tuple'> # ('hello', 'world')
注:创建一个元素时,需要在元素后面加上,
it = ("hello") print(type(it)) # <class 'str'> it = ("hello", ) print(type(it)) # <class 'tuple'>
集合
特点:
1.无序
2.无重复元素
创建
it = {"hello", "world"}
print(type(it))
it1 = set(range(6))
it2 = set([1, 2, 3]) # 类型转换
定义一个空集合
it = set() print(type(it)) print(it)
增加
add() 增加一个元素
update() 增加至少一个元素
删除
remove() 删除某一个元素,元素不存在则出现keyerror
discard() 删除一个元素,元素不存在不报错
pop() 任意删除一个元素
clear() 清除集合内的元素
集合间的关系
issubset 一个集合是否是另一个集合的子集
issuperset 一个集合是否是另一个集合的超集
isdisjoint 判断两个集合有没有交集
==和!= 判断两个集合是否相等
数据操作
s1.intersection(s2) 交集
s1.union(s2) 并集
s1.difference(s2) 差集
s1.symmtric_difference(s3) 对称差集
集合生成式
it = {i for i in range(10)}
print(it)
字符串
驻留机制
用is判断时通过id判断
用==判断时通过对象的值来判断
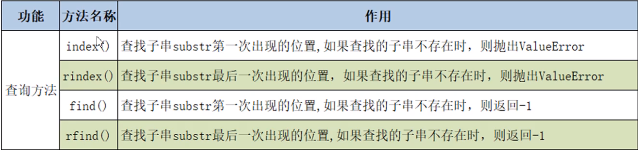
查询
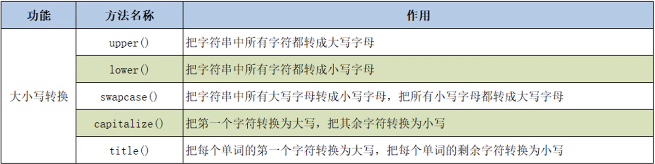
大小写转换
内容对齐操作

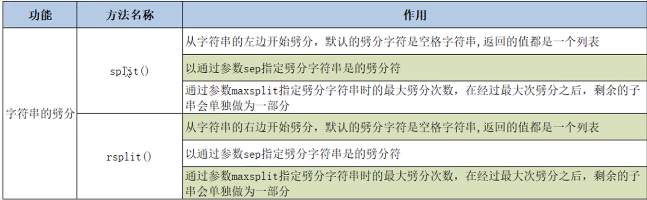
劈分
判断字符串的类型

替换与合并

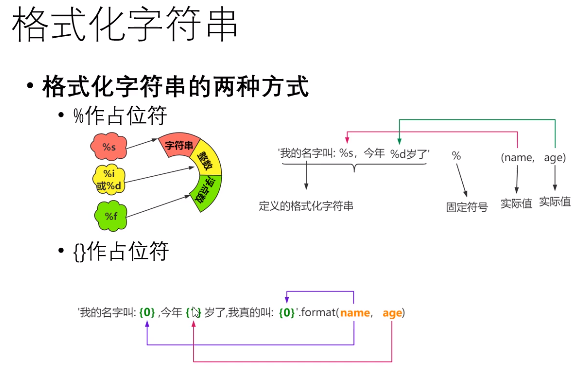
格式化字符串
encode() 将str转换成字节型

