
Golang 是否有必要内存对齐?
struct 中的字段顺序不同,内存占用也有可能会相差很大。比如:
type T1 struct {
a int8
b int64
c int16
}
type T2 struct {
a int8
c int16
b int64
}
在 64 bit 平台上,T1 占用 24 bytes,T2 占用 16 bytes 大小;而在 32 bit 平台上,T1 占用 16 bytes,T2 占用 12 bytes 大小。可见不同的字段顺序,最终决定 struct 的内存大小,所以有时候合理的字段顺序可以减少内存的开销。
这是为什么呢?因为有内存对齐的存在,编译器使用了内存对齐,那么最后的大小结果就会不一样。至于为什么要做对齐,主要考虑下面两个原因:
-
平台(移植性)
不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
-
性能
若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作,这显然高效很多,是标准的空间换时间做法
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放。但实际上 CPU 并不会以一个一个字节去读取和写入内存,相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小,块大小我们称其为内存访问粒度。假设访问粒度为 4,那么 CPU 就会以每 4 个字节大小的访问粒度去读取和写入内存。
在不同平台上的编译器都有自己默认的 “对齐系数”。一般来讲,我们常用的 x86 平台的系数为 4;x86_64 平台系数为 8。需要注意的是,除了这个默认的对齐系数外,还有不同数据类型的对齐系数。数据类型的对齐系数在不同平台上可能会不一致。例如,在 x86_64 平台上,int64 的对齐系数为 8,而在 x86 平台上其对齐系数就是 4。
还是拿上面的 T1、T2 来说,在 x86_64 平台上,T1 的内存布局为:
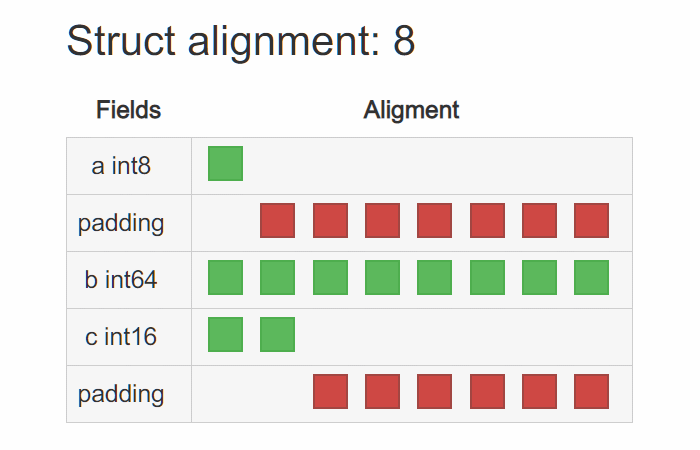
T2 的内存布局为(int16 的对齐系数为 2):

仔细看,T1 存在许多 padding,显然它占据了不少空间。那么也就不难理解,为什么调整结构体内成员变量的字段顺序就能达到缩小结构体占用大小的疑问了,是因为巧妙地减少了 padding 的存在。让它们更 “紧凑” 了。
其实内存对齐除了可以降低内存占用之外,还有一种情况是必须要手动对齐的:在 x86 平台上原子操作 64bit 指针。之所以要强制对齐,是因为在 32bit 平台下进行 64bit 原子操作要求必须 8 字节对齐,否则程序会 panic。详情可以参考 atomic 官方文档(这么重要的信息竟然放在页面的最底部!!!😱):
Bugs
On x86-32, the 64-bit functions use instructions unavailable before the Pentium MMX. On non-Linux ARM, the 64-bit functions use instructions unavailable before the ARMv6k core. On ARM, x86-32, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
比如,下面这段代码:
package main
import (
"sync/atomic"
)
type T3 struct {
b int64
c int32
d int64
}
func main() {
a := T3{}
atomic.AddInt64(&a.d, 1)
}
编译为 64bit 可执行文件,运行没有任何问题;但是当编译为 32bit 可执行文件,运行就会 panic:
$ GOARCH=386 go build aligned.go
$
$ ./aligned
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x8049f2c]
goroutine 1 [running]:
runtime/internal/atomic.Xadd64(0x941218c, 0x1, 0x0, 0x809a4c0, 0x944e070)
/usr/local/go/src/runtime/internal/atomic/asm_386.s:105 +0xc
main.main()
/root/gofourge/src/lab/archive/aligned.go:18 +0x42
原因就是 T3 在 32bit 平台上是 4 字节对齐,而在 64bit 平台上是 8 字节对齐。在 64bit 平台上其内存布局为:
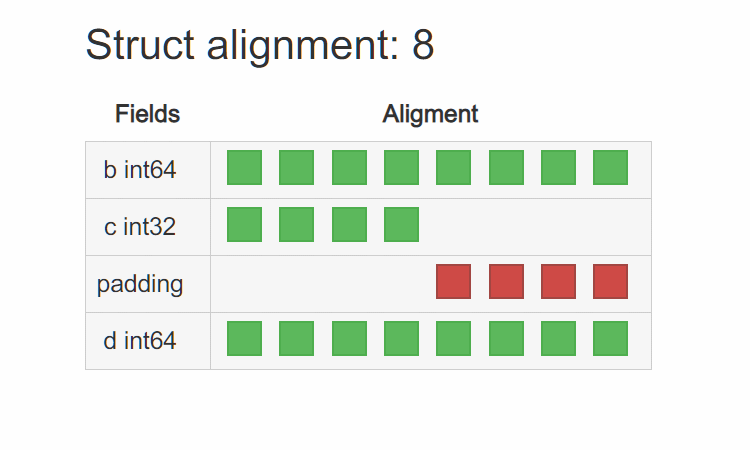
可以看到编译器为了让 d 8 字节对齐,在 c 后面 padding 了 4 个字节。而在 32bit 平台上其内存布局为:
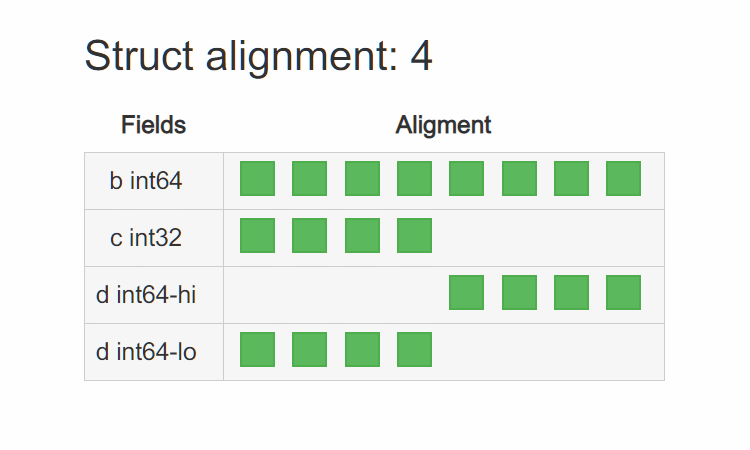
编译器用的是 4 字节对齐,所以 c 后面 4 个字节并没有 padding,而是直接排列 d 的高低位字节。
为了解决这种情况,我们必须手动 padding T3,让其 “看起来” 像是 8 字节对齐的:
type T3 struct {
b int64
c int32
_ int32
d int64
}
这样 T3 的内存布局就变成了:
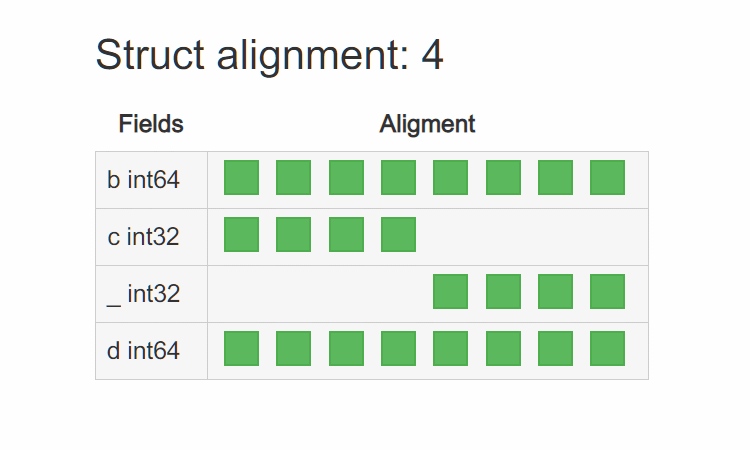
看起来就像 8 字节对齐了一样,这样就能完美兼容 32bit 平台了。其实很多知名的项目,都是这么处理的,比如 groupcache:
type Group struct {
_ int32 // force Stats to be 8-byte aligned on 32-bit platforms
// Stats are statistics on the group.
Stats Stats
}
说了这么多,但是在我们实际编码的时候,多数情况都不会考虑到最优的内存对齐。那有没有什么办法能自动检测当前的内存布局是最优呢?答案是:有的。
golang-sizeof.tips 这个网站就可以可视化 struct 的内存布局,但是只支持 8 字节对齐,是个缺点。还有一种方法,就是用 golangci-lint 做静态检测,比如在我的一个项目中检测结果是这样的:
$ golangci-lint run --disable-all -E maligned
config/config.go:79:11: struct of size 48 bytes could be of size 40 bytes (maligned)
type SASL struct {
^
提示有一处 struct 可以优化,来看一下这个 struct 的定义:
type SASL struct {
Enable bool
Username string
Password string
Handshake bool
}
通过 golang-sizeof.tips 对比,显然字段按照下面这样排序更为合理:
type SASL struct {
Username string
Password string
Handshake bool
Enable bool
}
参考文献
- On the memory alignment of Go slice values
- Memory Layouts
- cmd/vet: detect non-64-bit-aligned arguments to sync/atomic funcs
- Padding is hard
- 在 Go 中恰到好处的内存对齐
- Go unsafe 包之内存布局
转载: https://ms2008.github.io/2019/08/01/golang-memory-alignment/

