


一、Redis到底是单线程还是多线程
Redis 6.0版本之前的单线程指的是其网络I/O和键值对读写是由一个线程完成。
也就是只有网络请求模块和数据操作模块是单线程的,而其他的持久化、集群数据同步等,其实是由额外的线程执行的。
Redis6.0引入的多线程指的是网络请求过程采用了多线程,但键值对读写命令仍然是单线程处理的,所以Redis依然是并发安全的。
二、Redis单线程为什么还能这么快
- 命令执行是基于内存操作的,一天命令在内存里操作的时间是几十纳秒
- 命令执行是单线程操作,没有线程切换开销。
- 基于IO多路复用机制提升Redis的IO利用率。
- 高效的数据存储结构:全局hash表以及多种高效的数据结构,比如:跳表、压缩列表、链表等。
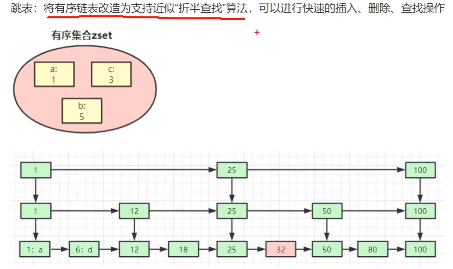
三、Redis底层数据是如何用跳表来存储的
四、Redis key 过期了为什么内存没释放
- 如果原本这个key是有过期时间的,再给这个key使用SET命令并且不设置过期时间,那么Redis会自动擦除这个key的过期时间。
Redis对于过期的key的处理一般有惰性删除和定时删除两种策略 - 惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,判断key是否过期,如果过期了直接删除这个key。这也是key过期了为什么没有立即释放内存。
- 定时删除:由于惰性删除无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已过期的key,这里的一批只是部分过期的key,所以可能会出现key已经过期了但是还没有被清理掉的情况,导致内存没有释放。
五、Redis key没有设置过期时间为什么被Redis主动删除了
当Redis已用内存超过maxmemory限定时,厨房主动清理策略
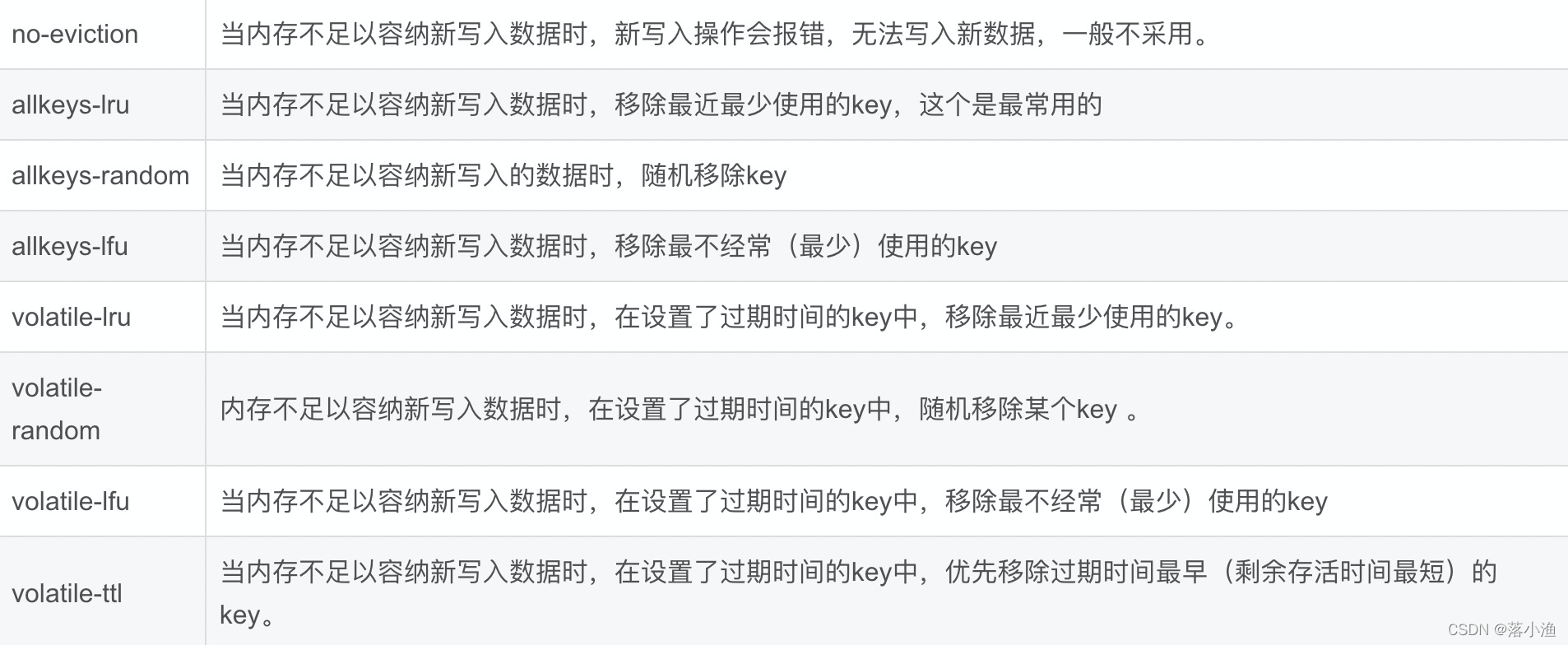
主动清理策略在Redis4.0之前,实现了6种内存淘汰策略,在4.0之后,又增加了两种,总共8种:
六、Redis 淘汰key的算法LRU与LFU的区别
LRU算法(Least Recently Used,最近最少使用):淘汰很久没被访问的数据,以最近一次访问时间作为参考。
LFU算法(Least Frequently Used,最不经常使用):淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
绝大多数情况我们可以用LRU策略,当存在大量的热点缓存数据时,LFU可能更好一点。
七、删除Key命令会阻塞Redis嘛
会阻塞的。DEL key[key...] 命令会根据key类型来删除,时间复杂度也是不一样的,O(N),N为被删除的key数量
删除单个字符串类型的key,时间复杂度为O(1)
删除单个列表、集合、有序集合或哈希类型的key,时间复杂度为O(M),M为以上数据结构内的元素数量。
八、Redis主从、哨兵、集群架构的优缺点比较
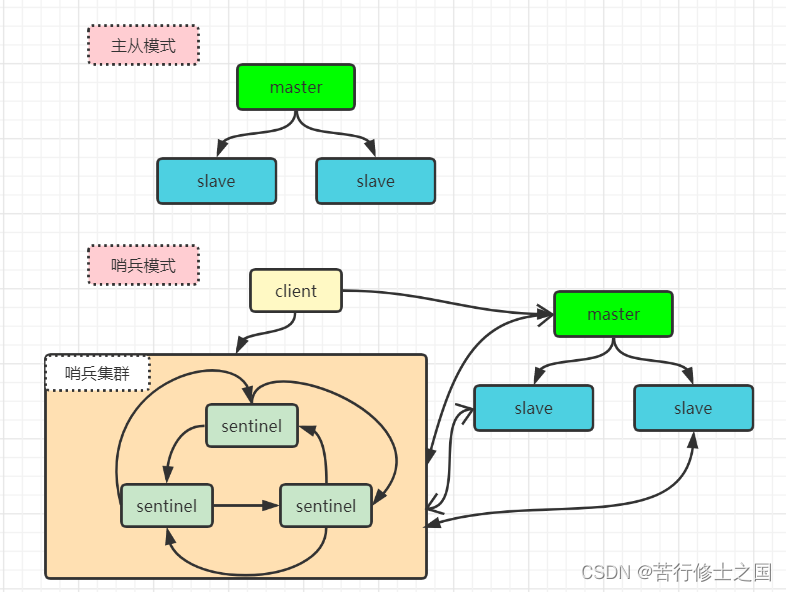
在Redis3.0以前的版本主要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点有异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用方面表现一般,特别在主从切换的瞬间存在访问瞬断的问题,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发量,且单个主节点的内存也不宜设置过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率。
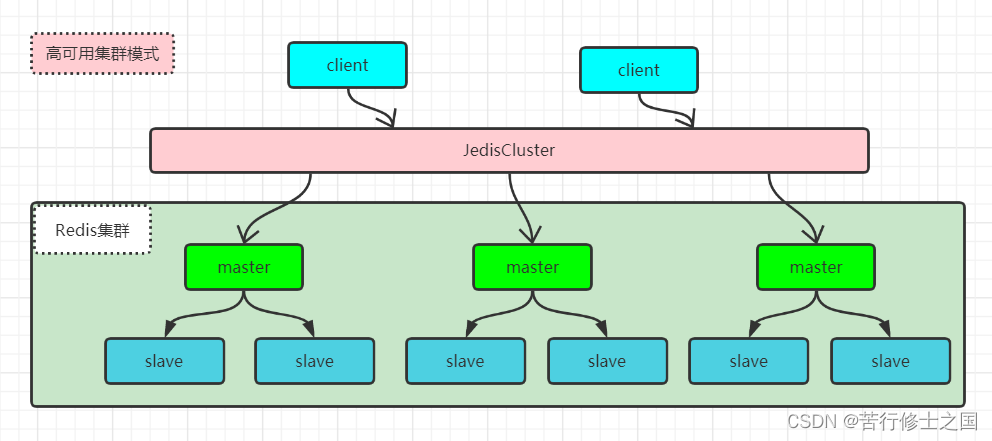
Redis集群是一个由多个主从节点群组组成的分布式服务集群,他具有复制、高可用、分片特性,Redis集群不需要sentinel哨兵,也能完成节点移除和故障转移的功能,需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展;Redis集群的性能和高可用均优于之前版本的哨兵模式,且集群配置非常简单。
九、谈谈Redis集群数据hash分片算法
Redis 集群将所有数据划分16384个slots,每个节点负责其中一部分槽位。当Redis 集群的客户端来连接集群时,它也会得到一份集群的槽位信息并将其缓存到客户端本地,这样当客户端要查找某个key时,可以根据槽位定位算法定位到目标节点。
槽位定位算法
集群默认会对key值使用crc16算法进行hash,得到一个整数值,然后这个整数值对16384进行取模运算来得到具体的槽位。
Hash_slot = CRC16(key)mod13684
再根据槽位和节点的对应关系就可以定位到key具体是在那个Redis节点上。
十、Redis执行命令竟然有死循环阻塞Bug
Redis有个RANDOMKEY命令可以从Redis中随机取出一个key,这个命令可能导致Redis死循环阻塞。
RANDOMKEY在随机拿出一个key之后,首先会检验这个key是否过期,如果该key过期,那么Redis会删除它,这个过程就是惰性删除,但是清理完了之后还不能结束,Redis会再找出一个没过期的key返回给客户端。
此时,Redis则会继续随机拿出一个key,然后再判断它是否过期,直到找到一个没过期的key返回给客户端。
这里就有一个问题,如果此时Redis中有大量的key过期,但还未来得及被清理掉,这个循环就会持续很久才能结束,这样就会导致RANDOMKEY命令执行耗时变长,影响Redis性能。
以上流程,其实是master上执行的。如果在slave上执行RANDOMKEY,那么问题更严重。
slave是不会自己清理过期的key,当一个key要过期时,master会先清理删除它,之后master向slave发送一个DEL命令,告知slave也删除这个key,以此达到主从一致。
假设Redis中存在大量已过期还未来得及清理的key,那么在slave上执行RANDOMKEY时,就会发生一下问题:
1、slave随机取出一个key,判断是否已经过期。
2、key已经过期,但是slave不会删除它,而是继续随机寻找不过期的key
3、由于大量key都已过期,那slave就会找不到符合条件的key,就会进入死循环。
这个Bug直到5.0才被修复,修复方法就是在slave中设置一个最大查找次数,无论找到与否,到了这个最大次数就退出循环。
十一、一次线上事故,Redis主从切换导致了缓存雪崩
我们假设,slave的机器时钟比master走的快很多。
此时,Redis master 里设置了过期时间的key,从slave角度来看,可能会有很多在master里没过期,在slave里面已经过期了的数据。
如果此时操作主从切换,把slave提升为新的master,新的master就会开始大量清理过期的key,此时就会导致以下结果:
1、master大量清理过期key,主线程可能会发生阻塞,无法及时处理客户端请求。
2、Redis中数据大量过期,引发缓存雪崩。
所以,我们一定要保证主从库的机器时钟一致,避免发生这些问题。
十二、Redis持久化RDB、AOF、混合持久化
Redis持久化分为:RDB、AOF、混合持久化(redis4.0引入)
RDB的实现原理、优缺点
描述:类似于快照。在某个时间点,将 Redis 在内存中的数据库状态(数据库的键值对等信息)保存到磁盘里面。RDB 持久化功能生成的 RDB 文件是经过压缩的二进制文件。
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE。
开启:使用 save point 配置
save 900 1 #900秒内有1个key发生了变化,则触发保存RDB文件
save 300 10 #300秒内有10个key发生了变化,则触发保存RDB文件
save 60 10000 #60秒内有10000个key发生了变化,则触发保存RDB文件
关闭:1)注释掉所有save point 配置可以关闭 RDB 持久化。2)在所有 save point 配置后增加:save "",该配置可以删除所有之前配置的 save point。
SAVE:生成 RDB 快照文件,但是会阻塞主进程,服务器将无法处理客户端发来的命令请求,所以通常不会直接使用该命令。
BGSAVE:fork 子进程来生成 RDB 快照文件,阻塞只会发生在 fork 子进程的时候,之后主进程可以正常处理请求.
- RDB 的优点:1)RDB 文件是是经过压缩的二进制文件,占用空间很小,它保存了 Redis 某个时间点的数据集,很适合用于做备份。 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
2)RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心。
3)RDB 可以最大化 redis 的性能。父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
4)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。 - RDB 的缺点:1)RDB 在服务器故障时容易造成数据的丢失
2)RDB 保存时使用 fork 子进程进行数据的持久化,如果数据比较大的话,fork 可能会非常耗时,造成 Redis 停止处理服务N毫秒。如果数据集很大且 CPU 比较繁忙的时候,停止服务的时间甚至会到一秒。
3)Linux fork 子进程采用的是 copy-on-write 的方式。在 Redis 执行 RDB 持久化期间,如果 client 写入数据很频繁,那么将增加 Redis 占用的内存,最坏情况下,内存的占用将达到原先的2倍。刚 fork 时,主进程和子进程共享内存,但是随着主进程需要处理写操作,主进程需要将修改的页面拷贝一份出来,然后进行修改。极端情况下,如果所有的页面都被修改,则此时的内存占用是原先的2倍。
AOF的实现原理、优缺点
描述:保存 Redis 服务器所执行的所有写操作命令来记录数据库状态,并在服务器启动时,通过重新执行这些命令来还原数据集。
可以通过配置:appendonly yes 开启,使用配置 appendonly no 可以关闭 AOF 持久化
AOF 持久化功能的实现可以分为三个步骤:命令追加、文件写入、文件同步。
appendfsync 参数有三个选项:
1)always:每处理一个命令都将 aof_buf 缓冲区中的所有内容写入并同步到AOF 文件,即每个命令都刷盘。
2)everysec:将 aof_buf 缓冲区中的所有内容写入到 AOF 文件,如果上次同步 AOF 文件的时间距离现在超过一秒钟, 那么再次对 AOF 文件进行同步, 并且这个同步操作是异步的,由一个后台线程专门负责执行,即每秒刷盘1次。
3)no:将 aof_buf 缓冲区中的所有内容写入到 AOF 文件, 但并不对 AOF 文件进行同步, 何时同步由操作系统来决定。即不执行刷盘,让操作系统自己执行刷盘。 - AOF 的优点:1)AOF 比 RDB可靠。你可以设置不同的 fsync 策略:no、everysec 和 always。默认是 everysec,在这种配置下,redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据。
2)AOF文件是一个纯追加的日志文件。即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机等等), 我们也可以使用 redis-check-aof 工具也可以轻易地修复这种问题。
3)当 AOF文件太大时,Redis 会自动在后台进行重写:重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。整个重写是绝对安全,因为重写是在一个新的文件上进行,同时 Redis 会继续往旧的文件追加数据。当新文件重写完毕,Redis 会把新旧文件进行切换,然后开始把数据写到新文件上
4)AOF 文件有序地保存了对数据库执行的所有写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。如果你不小心执行了 FLUSHALL 命令把所有数据刷掉了,但只要 AOF 文件没有被重写,那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。 - AOF 的缺点
1)对于相同的数据集,AOF 文件的大小一般会比 RDB 文件大。
2)根据所使用的 fsync 策略,AOF 的速度可能会比 RDB 慢。通常 fsync 设置为每秒一次就能获得比较高的性能,而关闭 fsync 可以让 AOF 的速度和 RDB 一样快。
生产环境都可以启用,redis启动时如果既有rdb文件,又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更安全一点。
混合持久化
通过如下配置开启混合持久化(必须先开启aof)
aof-use-rdb-preamble yes
混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的子进程先将当前全量数据以 RDB 方式写入新的 AOF 文件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks)的增量命令以 AOF 方式写入到文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
优点:结合 RDB 和 AOF 的优点, 更快的重写和恢复。
缺点:AOF 文件里面的 RDB 部分不再是 AOF 格式,可读性差。

