

机器学习实战系列---决策树(ID3)
在介绍ID3算法前,让我们先用一张图引入什么是决策树。
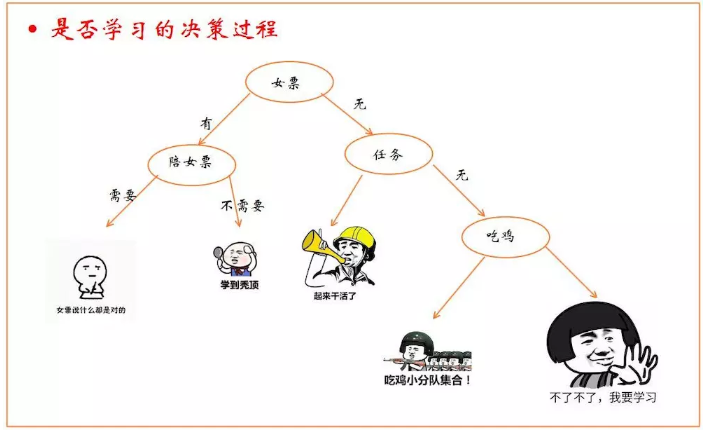
决策树是模仿树结构来进行决策的,通过判断有无女票、是否需要陪女票、有无任务等子决策来对是否学习作出最终的决策。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
决策树的构造
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据集分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每一个特征。选取最好的特征作为决策树的一个分支节点,以该特征的值作为分支重新划分数据集,如果划分后的数据集分类相同或者无特征可选取时(采用多数表决法决定类别),直接返回类别作为叶子节点,否则继续寻找最优特征。决策树的构造过程就是递归的寻找最优特征的过程。
创建决策树的伪代码如下所示:
检测数据集中的每一个子项是否属于同一类:
def createTree (dataSet):
if so return 类标签
else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
createTree(subdataSet)
return 分支节点
信息熵
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事物可能划分在多个分类之中,则符号xi的信息定义为L(xi)=-log2p(xi),其中p(xi)为选择该分类的概率。
为了计算信息熵,我们需要计算所有类别可能值包含的信息期望值,通过以下公式得到:
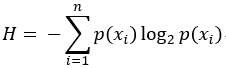
条件熵
信息熵是代表随机变量的复杂度(不确定度),条件熵代表在某一个条件下,随机变量的复杂度(不确定度)
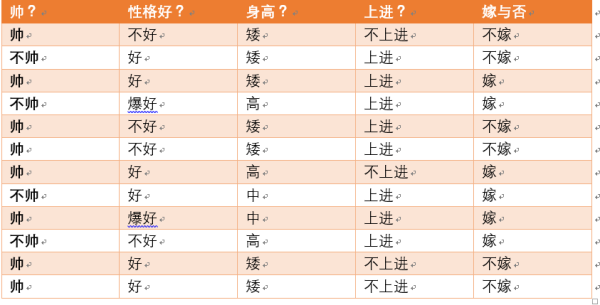
由上表可知,分类嫁有6个,分类不嫁有6个,故随机变量Y(嫁与否)的信息熵为
H(Y)=-1/2log2(1/2)-1/2log2(1/2)
假设我们已知条件X代表男生长相信息,取值为(帅,不帅),求随机变量Y在该条件下的条件熵。
当X=帅时,共有8条数据,其中嫁的个数为3,不嫁的个数为5,故 H(Y|X=帅)=-3/8log2(3/8)-5/8log2(5/8)
当X=不帅时,共有4条数据,其中嫁的个数为3,不嫁的个数为1,故 H(Y|X=不帅)=-3/4log2(3/4)-1/4log2(1/4)
可知p(X=帅)=2/3,p(X=不帅)=1/3。
条件熵公式如下所示:
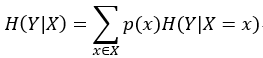
故H(Y|X=长相) = p(X=帅) H(Y|X=帅)+p(X=不帅)H(Y|X=不帅)
信息增益
信息增益=信息熵-条件熵
信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。
代码实现
from math import log
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
# 计算熵,类别越多,熵越大,纯度越低
def calcShannonEnt(dataSet):
# 求dataSet的长度,表示计算参与训练的数据量
numEntries = len(dataSet)
# 计算分类类别出现的次数
classCounts = {}
for featVec in dataSet:
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
currentLabel = featVec[-1]
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
if currentLabel not in classCounts.keys():
classCounts[currentLabel] = 0
classCounts[currentLabel] += 1
# 对于 label 标签的占比,求出 label 标签的香农熵
shannonEnt = 0.0
#print(classCounts)
for key in classCounts:
# 使用所有类标签的发生频率计算类别出现的概率。
prob = float(classCounts[key])/numEntries
shannonEnt -= prob*log(prob, 2)
return shannonEnt
def splitDataSet(dataSet, axis, value):
'''
根据特征所在列axis和特征值value划分原数据集
:param dataSet:待划分数据集
:param axis:划分数据集依据的特征
:param value:表示axis对应的特征值
:return:axis列为value的数据集[划分出的新数据集不包含axis列]
'''
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 选取最好的特征划分数据集
def chooseBestFeatureToSplit(dataSet):
'''
选取最好的特征[根据信息增益选择]
:param dataSet:数据集
:return:最优的特征列(返回的为index值)
'''
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
# 获取对应特征的各种值
featList = [example[i] for example in dataSet]
# 特征值去重
uniqueVals = set(featList)
newEntropy = 0.0
# 遍历某一列(列代表特征)的value集合,计算该列的信息熵
# 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = float(len(subDataSet))/len(dataSet)
newEntropy += prob*calcShannonEnt(subDataSet)
# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值
# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain :
bestInfoGain = infoGain
bestFeature = i
return bestFeature
#递归建树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
# count() 函数是统计括号中的值在list中出现的次数
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
if len(dataSet[0]) == 1:
return majorityCnt(classList)
# 选择最优的特征列,得到最优特征列对应的index值
bestFeat = chooseBestFeatureToSplit(dataSet)
# 得到最优特征的名称
bestFeatLabel = labels[bestFeat]
# 初始化决策树
myTree = {bestFeatLabel: {}}
# 取出最优列,然后它的branch做分类
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:bestFeat]
subLabels.extend(labels[bestFeat+1:])
# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()
#print(splitDataSet(dataSet, bestFeat, value))
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def majorityCnt(classList):
'''
使用完所有特征仍不能将数据集划分为只含有一个类别的分组,此时返回类别分组里类别值出现次数最多的那个
:param classList: 仅含有类别且含有多种类别值的分组
:return: 返回出现次数最多的一个类别值
'''
classCounts = {}
for vote in classList:
if vote not in classCounts.keys():
classCounts[vote] = 0
classCounts[vote] += 1
sortedClassCount = sorted(classCounts)
return sortedClassCount[0]
def classify(inputTree, featLabels, testVec):
#python3之后dict.keys返回值为dict_keys对象,不支持索引,故需将其转换为list对象
First_featLabel = list(inputTree.keys())[0]
secondDict = inputTree[First_featLabel]
featIndex = featLabels.index(First_featLabel)
for key in secondDict:
if key == testVec[featIndex]:
if isinstance(secondDict[key], str) == True:
return secondDict[key]
else:
return classify(secondDict[key], featLabels, testVec)
return -1
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)
if __name__ == '__main__':
dataSet, labels = createDataSet()
myTree = createTree(dataSet, labels)
result = classify(myTree, labels, [1, 1])
storeTree(myTree, 'myTree.txt')
print(grabTree('myTree.txt'))
Done!
