获取jdk编码字符
最近一个项目在idea上编译正常运行,部署到正式环境中出现中文乱码,通过运行下面的代码发现jdk编码是GBK而我的编译是UTF-8
import java.io.ByteArrayOutputStream; import java.io.OutputStreamWriter; import java.nio.charset.Charset; class Test { public static void main(String[] args) { System.out.println("Default Charset=" + Charset.defaultCharset()); System.out.println("file.encoding=" + System.getProperty("file.encoding")); System.out.println("Default Charset=" + Charset.defaultCharset()); System.out.println("Default Charset in Use=" + getDefaultCharSet()); } private static String getDefaultCharSet() { OutputStreamWriter writer = new OutputStreamWriter(new ByteArrayOutputStream()); String enc = writer.getEncoding(); return enc; } }

方案一:在编译的时候加个 -Dfile.encoding=UTF-8
我写了个.bat脚本
@echo off start java -Dfile.encoding=utf-8 -jar demo-0.0.1-SNAPSHOT.jar exit
方案二:配置环境变量
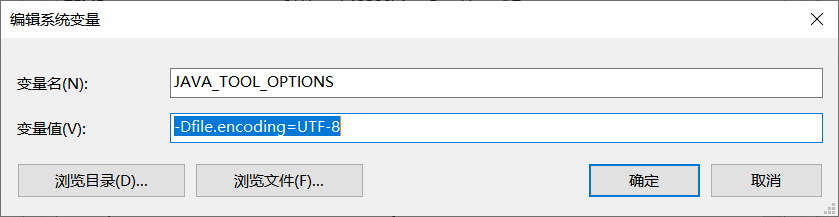
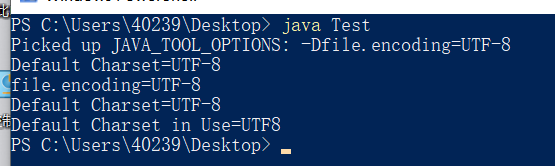
然后运行刚才的代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号