hadoop本地运行官方Grep案例 wordCount案例
Grep案例
第一步: 在Hadoop文件夹下
mkdir input
cp etc/hadoop/*.xml input/
hadoop jar share/hadoop/mapreduce//hadoop-mapreduce-examples-2.7.2.jar grep input/ output 'dfs[a-z.]+'
执行完上一句会创建一个output文件夹(里边有两个文件)这个文件夹不能自己创建

输入 cat part-r-00000
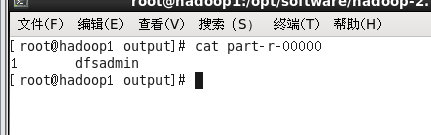
输出结果为符合'dfs[a-z.]+'条件的数据
wordCount案例
mkdir wcinput
cd wcinput
touch wc.input(名字随便起)
vim wc.input
输入一些数据
tianyi huichao lihua
zhangcheng xiaoheng
xinbo xinbo
gaoyang gaoyang gaoyang yanjing yanjing
保存退出
cd .. 退回上一层
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput
cd wcoutput
cat part-r-00000
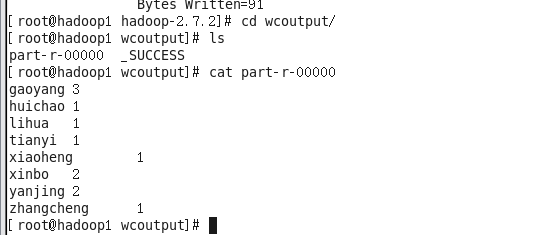
统计出每个单词出现的次数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号