Redis 要知道的一点东西(二)
实践篇
一些基础可以看上一篇 Redis 一点基础
数据的适量存储
1、String 类型的短板?
String 消耗内存大
2、为什么 String 类型内存开销大?
String 类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了。
3、SDS(简单动态字符串)的结构
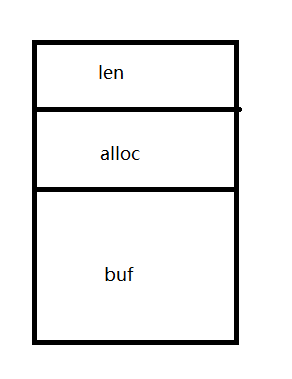
- buf:字节数组,保存实际数据,会在最后面加一个
\0,多占用一个字节 - len:占用四个字节,表示buf的已用长度
- alloc:占用四个字节,表示buf的实际长度,一般大于 len
4、什么是Redis Object?
因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
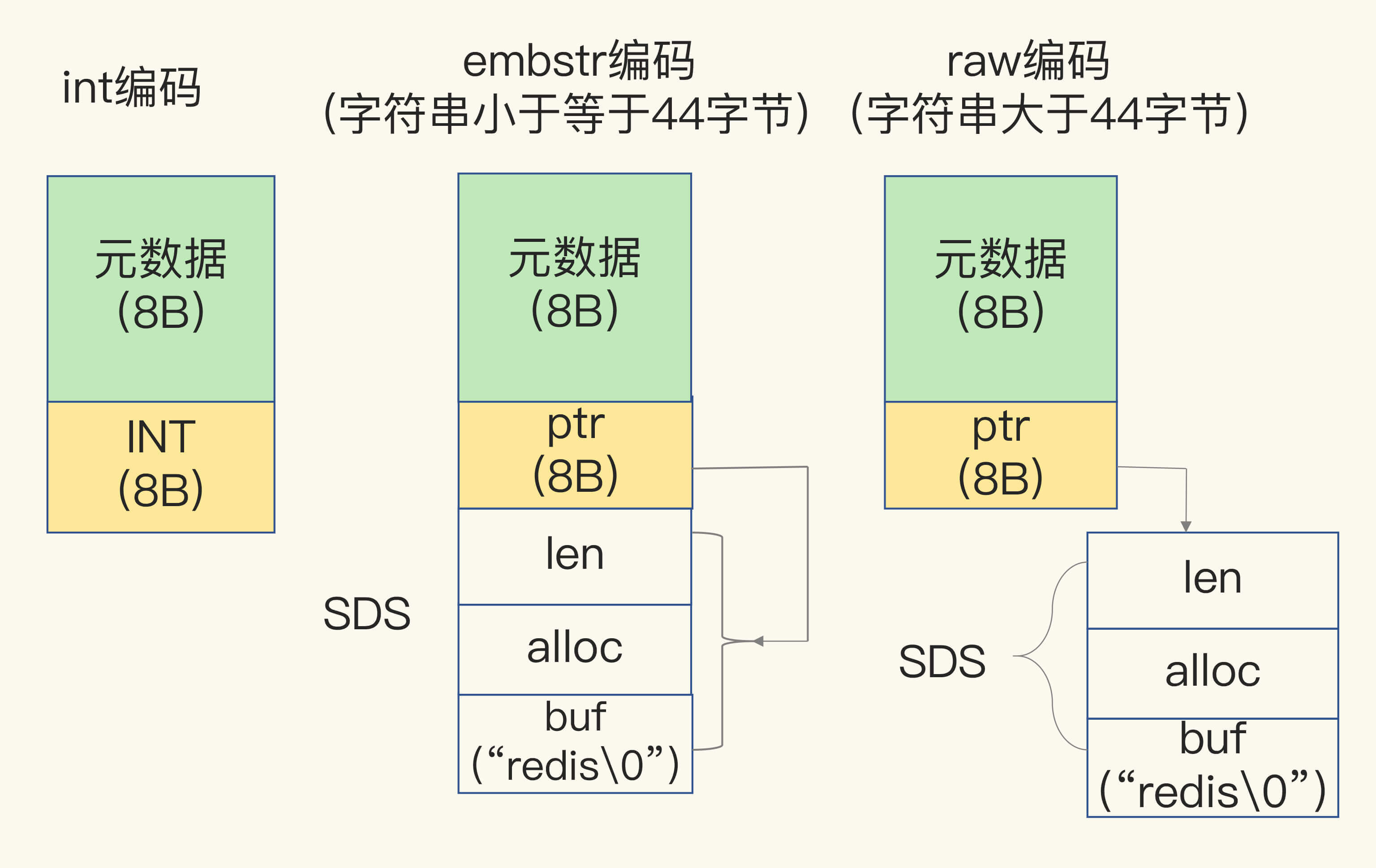
5、Redis Object 的结构是什么样的?
8 byte 的元数据以及 8 byte的指针(ptr),指针指向具体数据类型的实际数据所在地址,redis object 对 sds 做了单独的优化,如果存入的是:
- long 整型数组的时候,ptr 为具体的值
- 如果是字符串类型,且小于 44 byte,元数据、指针和sds是一块连续的内存,并用指针指向sds,raw 编码模式
- 其他则为指针查找模式
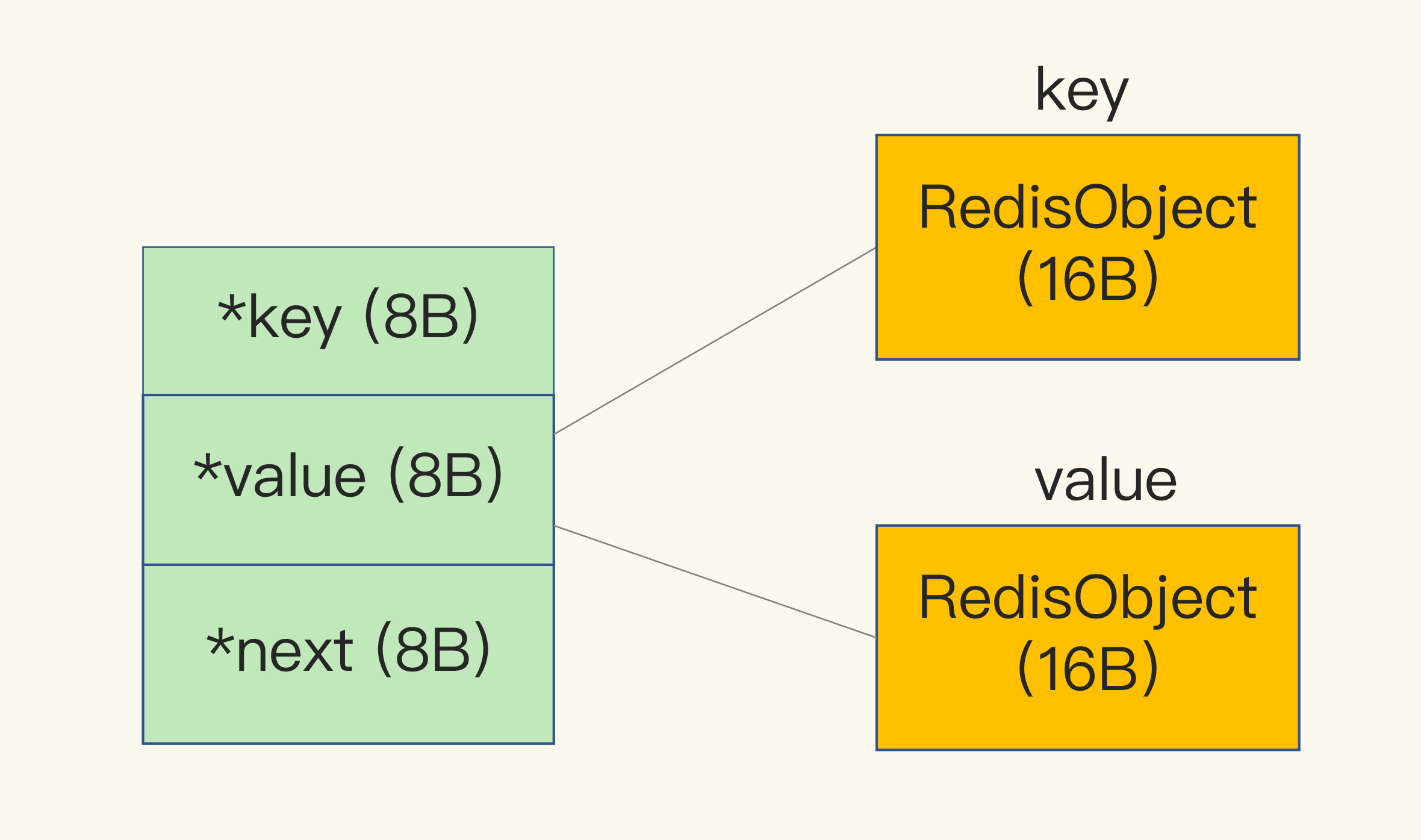
6、dictEntry 啥样子?
dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节:
7、Redis 内存申请方式
使用内存分配库 jemallloc,jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。
8、保存小数据的时候可以用什么数据结构保存,在Redis中?
压缩列表
9、压缩列表保存数据的结构是什么样的?
压缩列表由一些元数据与真正存储数据的 entry 构成,entry包含以下结构:
- prev_len:如果上一个 entry 长度小于 254(255被zlend当成默认值使用了,表示压缩列表的结束) 字节,则此值为 1字节,大于254 则采用 5 字节
- len:表示自身的长度,4字节
- encoding:表示编码方式 1字节
- content:保存实际数据
10、Hash 结构压缩列表与 hash 结构的转换
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
超过这俩阈值其中的一个就会由压缩列表转化为 hash 存储了
11、常见的集合统计模式有哪些?
- 聚合统计
- 排序统计
- 二值统计 bitmap
- 基数统计 hyperloglog pfadd pfcount 有误算率 0.81%
12、GEO 是怎么实现的?
GEO 类型的底层数据结构就是用 Sorted Set 来实现的,采用的是 GeoHash 编码,基本原理就是 二分区间,区间编码
当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
13、GeoHash 编码是怎么计算的?
- 先从单独对经度与维度编码来看
- 对于一个地理位置信息来说,它的经度范围是[-180,180]。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N 可以自定义。
- 在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](可称之为左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。
- 重复之前的操作,每次都能获得一位编码,等做完 N 次之后就可以用一个 N bit 的数来表示了
- 对维度也是一样,只不过维度的范围是[-90,90]
- 等经纬度都编码完之后,再组合到一起,组合的规则是,偶位数上依次是经度的编码值,奇位数上是维度的编码值,由此得到 sort set 的权重
为了避免查询不准确问题,可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格
14、分布式组件消息队列的需求?
- 消息保序
- 重复消费处理
- 消息可靠性保证
影响 Redis 性能的潜在方面
15、与 Redis 交互发生的操作
- 客户端:网络 IO,键值对增删改查操作,数据库操作;
- 磁盘:生成 RDB 快照,记录 AOF 日志,AOF 日志重写;
- 主从节点:主库生成、传输 RDB 文件,从库接收 RDB 文件、清空数据库、加载 RDB 文件;
- 切片集群实例:向其他实例传输哈希槽信息,数据迁移。
16、Redis 的阻塞点有哪些?
- 客户端交互阻塞点
- 客户端的复杂操作,集合全量查询和聚合操作。
- bigkey 的删除操作
- **清空数据库 ** FLUSHDB\FLUSHALL
- 和磁盘交互时的阻塞点
- AOF 日志同步写
- 主从节点交互时的阻塞点
- 从节点加载RDB 文件
17、redis的删除操作?
删除操作的本质是要释放键值对占用的内存空间。在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序,所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞。
18、redis 解决部分阻塞点的方式?
异步的子线程机制,利用操作系统 pthread_create 函数创建 3 个子线程,分别负责 aof 的写操作、键值对删除以及文件关闭的异步执行。
主线程通过一个链表形式的任务队列和子线程进行交互。
- aof 被封装成一个任务放入队列,异步执行
- 异步删除,惰性删除,即使开启了lazy-free,如果直接使用DEL命令还是会同步删除key,只有使用UNLINK命令才会可能异步删除key。
- 清空数据库用 flushdb async
19 、lazy_free 是个什么东西?
lazy-free是4.0新增的功能,但是默认是关闭的,需要手动开启。
- lazyfree-lazy-expire:key在过期删除时尝试异步释放内存
- lazyfree-lazy-eviction:内存达到maxmemory并设置了淘汰策略时尝试异步释放内存
- lazyfree-lazy-server-del:执行RENAME/MOVE等命令或需要覆盖一个key时,删除旧key尝试异步释放内存
- replica-lazy-flush:主从全量同步,从库清空数据库时异步释放内存
lazy_free 也不是一直生效的,除了 replica-lazy-flush 以外都只是可能释放;
开启lazy-free后,Redis在释放一个key的内存时,首先会评估代价,如果释放内存的代价很小,那么就直接在主线程中操作了,没必要放到异步线程中执行(不同线程传递数据也会有性能消耗)。
20、什么情况 lazy_free 才会真正异步释放内存?
- 当Hash/Set底层采用哈希表存储(非ziplist/int编码存储)时,并且元素数量超过64个
- 当ZSet底层采用跳表存储(非ziplist编码存储)时,并且元素数量超过64个
- 当List链表节点数量超过64个(注意,不是元素数量,而是链表节点的数量,List的实现是在每个节点包含了若干个元素的数据,这些元素采用ziplist存储)
只有以上这些情况,在删除key释放内存时,才会真正放到异步线程中执行,其他情况一律还是在主线程操作。
也就是说String(不管内存占用多大)、List(少量元素)、Set(int编码存储)、Hash/ZSet(ziplist编码存储)这些情况下的key在释放内存时,依旧在主线程中操作。
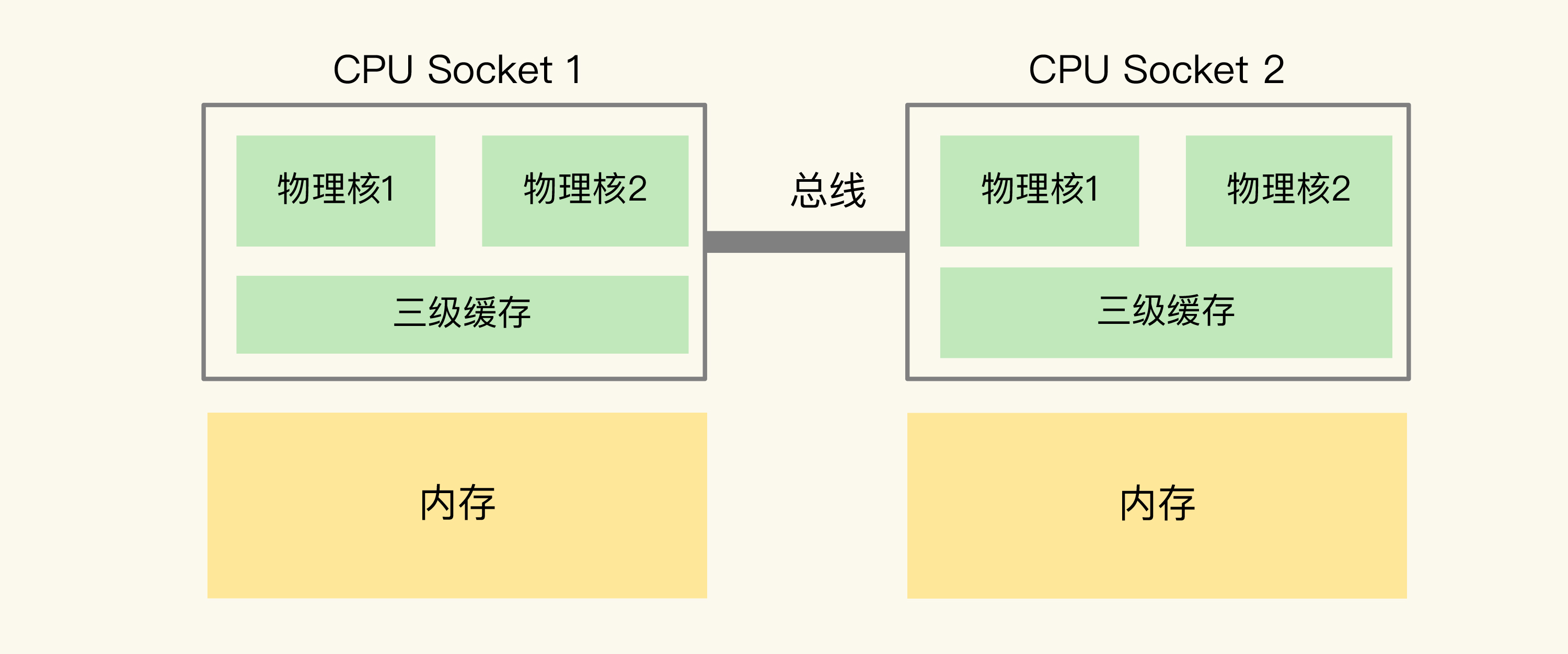
21、主流的 CPU 架构
主流 CPU 有物理核,逻辑核,一个 cpu 组成一个 socket,多个cpu通过总线通信,这种架构叫 NUMA 架构(非统一内存访问架构);
在多 CPU 架构上,应用程序可以在不同的处理器上运行
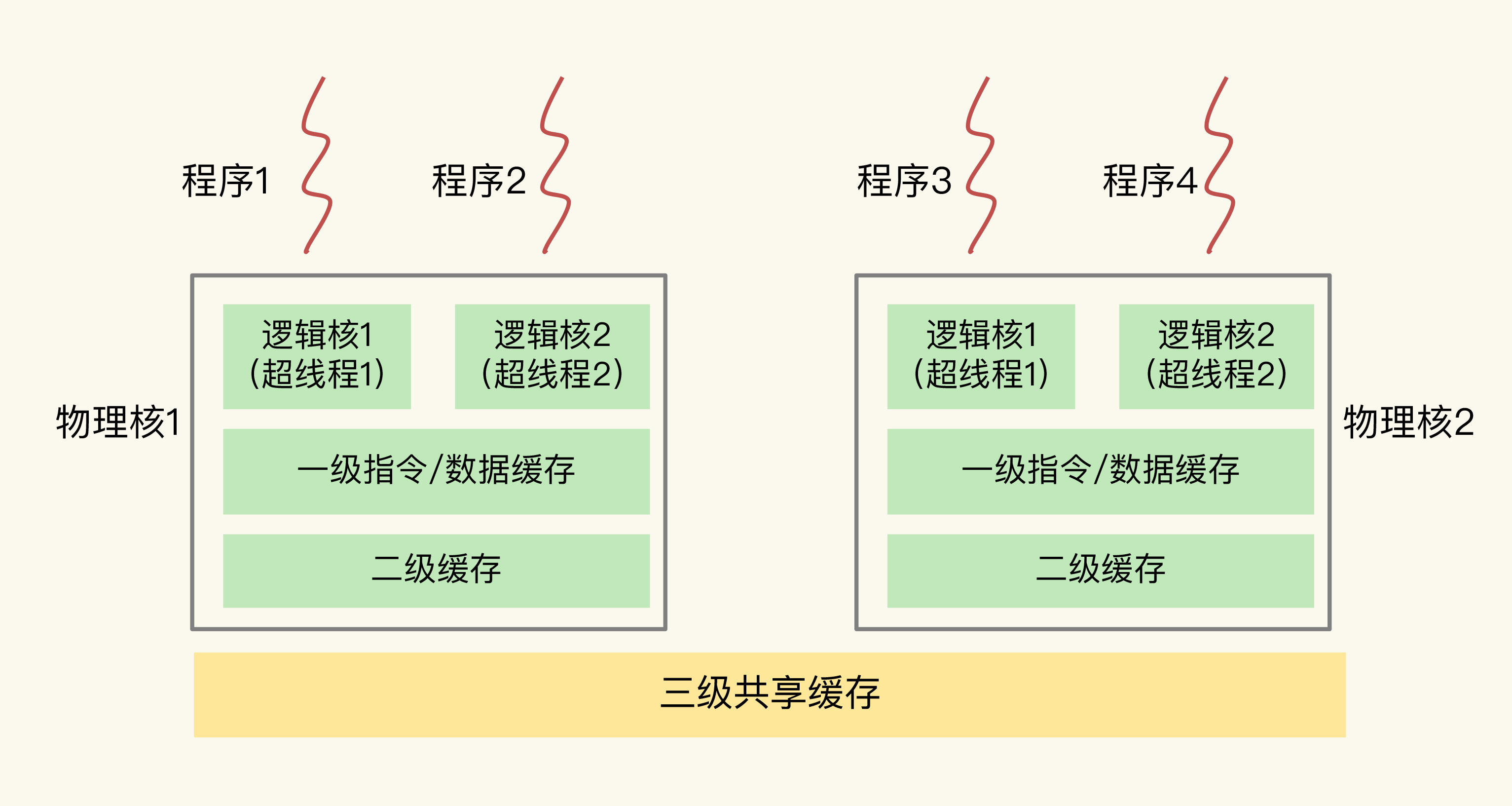
在主流的服务器上,一个 CPU 处理器会有 10 到 20 多个物理核。同时,为了提升服务器的处理能力,服务器上通常还会有多个 CPU 处理器(也称为多 CPU Socket),每个处理器有自己的物理核(包括 L1、L2 缓存),L3 缓存,以及连接的内存,同时,不同处理器间通过总线连接。
22、什么是尾延迟?
们把所有请求的处理延迟从小到大排个序,99% 的请求延迟小于的值就是 99% 尾延迟。
23、context switch
context switch 是指线程的上下文切换,这里的上下文就是线程的运行时信息。
24、redis 绑核
# -c 表示要绑定的核号
taskset -c 0 ./redis-server
25、绑核的好处?
- 降低尾延迟
- 降低平均延迟
- 提升吞吐率
26、绑核的风险
当把 Redis 实例绑定到一个逻辑核的时候,会导致后台线程、进程与 Redis 主进程争抢CPU,主线程就会被阻塞,导致 Redis 延迟增加
27、怎么解决绑核的问题?
- Redis 实例对应绑一个物理核
- 优化 Redis 源码。
# 绑定0、12 逻辑核,其实是一个物理核
taskset -c 0,12 ./redis-server
28、怎么检测 Redis 的响应延迟?
./redis-cli --intrinsic-latency 120
29、过期 key 操作
默认情况下,Redis 每 100 毫秒会删除一些过期 key
- 采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP (默认20)个数的 key,并将其中过期的 key 全部删除;
- 如果超过 25% 的 key 过期了,则重复删除(阻塞)的过程,直到过期 key 的比例降至 25% 以下。
为了防止同一时间大量的key过期,给同一批次的数据加上随机过期时间是个不错的选择
30、替代 keys 的 sacn 命令有什么好处跟问题?
- 不会漏key:Redis在SCAN遍历全局哈希表时,采用高位进位法的方式遍历哈希桶,当哈希表扩容后,通过这种算法遍历,旧哈希表中的数据映射到新哈希表,依旧会保留原来的先后顺序,这样就可以保证遍历时不会遗漏也不会重复。
- 可能会得到重复的key:在 hash 桶缩容的时候,会将扫描过的key映射到hash表还没遍历的地方,所以会重复
scan 是针对所有key的,redis 针对 hash/set/sorted set 也提供了对应的 scan 命令,用于遍历一个key 所有的 value,但是 hscan、sscan、zscan 如果数据比较少的话,底层采用 intset\ziplist ,命令会无视 count 参数,将所有的数据都返回出来
31、什么是 hash tag?
在键值对的key中使用花括号{},例如{user:}1, {user:}2这样。Redis cluster会针对花括号中的部分进行哈希,这样可以把具有相同前缀的key分配到同一个哈希槽里面。
可能会导致数据分布不均衡
32、AOF 数据的流动方向?
aof 依赖 write 与 fsync 两个系统调用
- write 只需要把日志写到内核缓冲区就可以返回了
- fsync 需要把日志记录写到磁盘才能返回,时间较长
33、不同 AOF 策略对应系统调用
- no 对应 write,由操作系统来保证刷盘
- everysec 对应 redis 子线程来调用 fsync ,不阻塞主线程
- always 对应着 fsync,由主线程调用
34、Redis 使用 fsync 的阻塞点?
- fsync需要等到数据写入磁盘才能返回,aof 重写对磁盘 io 压力过大时,就会导致 fsync 阻塞,虽然 fsync 是子线程去做,但是主线程要监控执行的进度。
- 当主线程使用 子线程 执行了一次 fsync,需要再次把数据写回磁盘的时候,发现上次的fsync还没进行完,则阻塞主线程
35、怎么让 aof 重写与 fsync 分离?
如果业务应用对延迟非常敏感,但同时允许一定量的数据丢失,那么可以关闭在 aof 时调用 fsync
no-appendfsync-on-rewrite yes
这个配置项设置为 yes 时,表示在 AOF 重写时,不进行 fsync 操作。如果设置为 no 的话,redis 实例仍然会调用后台线程进行 fsync,会给实例带来阻塞。
36、什么是 swap?
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写,所以,一旦触发 swap,无论是被换入数据的进程,还是被换出数据的进程,其性能都会受到慢速磁盘读写的影响。
37、什么时候会触发 swap?
物理机器内存不足
- Redis 实例自身使用了大量的内存,导致物理机器的可用内存不足;
- 和 Redis 实例在同一台机器上运行的其他进程,在进行大量的文件读写操作。文件读写本身会占用系统内存,这会导致分配给 Redis 实例的内存量变少,进而触发 Redis 发生 swap。
可以增加机器内存或者使用redis cluster
38、系统大页会给 Redis 带来什么问题?
因为 redis 大量采用 COW(写时复制)的操作,如果使用系统大页,会将原本只拷贝 4KB 的数据变成拷贝 2MB,影响 Redis 正常的存取操作。
# always 为启动,never 为关闭
cat /sys/kernel/mm/transparent_hugepage/enabled
# 部署时关闭系统大页
echo never /sys/kernel/mm/transparent_hugepage/enabled
39、如何分析、排查、解决Redis变慢问题?
1、使用复杂度过高的命令
(例如SORT/SUION/ZUNIONSTORE/KEYS),或一次查询全量数据(例如LRANGE key 0 N,但N很大)
分析:
- 查看slowlog是否存在这些命令
- Redis进程CPU使用率是否飙升(聚合运算命令导致)
解决:
- 不使用复杂度过高的命令,或用其他方式代替实现(放在客户端做)
- 数据尽量分批查询(LRANGE key 0 N,建议N<=100,查询全量数据建议使用HSCAN/SSCAN/ZSCAN)
2、操作bigkey
分析:
- slowlog出现很多SET/DELETE变慢命令(bigkey分配内存和释放内存变慢)
- 使用redis-cli -h $host -p $port --bigkeys扫描出很多bigkey
解决:
- 优化业务,避免存储bigkey
- Redis 4.0+可开启lazy-free机制
3、大量key集中过期
分析:
- 业务使用EXPIREAT/PEXPIREAT命令
- Redis info中的expired_keys指标短期突增
解决:
- 优化业务,过期增加随机时间,把时间打散,减轻删除过期key的压力
- 运维层面,监控expired_keys指标,有短期突增及时报警排查
4、Redis内存达到maxmemory
分析:
- 实例内存达到maxmemory,且写入量大,淘汰key压力变大
- Redis info中的evicted_keys指标短期突增
解决:
- 业务层面,根据情况调整淘汰策略(随机比LRU快)
- 运维层面,监控evicted_keys指标,有短期突增及时报警
- 集群扩容,多个实例减轻淘汰key的压力
5、大量短连接请求
分析:
- Redis处理大量短连接请求,TCP三次握手和四次挥手也会增加耗时
解决:
- 使用长连接操作Redis
6、生成RDB和AOF重写fork耗时严重
分析:
- Redis变慢只发生在生成RDB和AOF重写期间
- 实例占用内存越大,fork拷贝内存页表越久 c) Redis info中latest_fork_usec耗时变长
解决:
- 实例尽量小
- Redis尽量部署在物理机上
- 优化备份策略(例如低峰期备份)
- 合理配置repl-backlog和slave client-output-buffer-limit,避免主从全量同步
- 视情况考虑关闭AOF
- 监控latest_fork_usec耗时是否变长
7、AOF使用awalys机制
分析:
- 磁盘IO负载变高
解决:
- 使用everysec机制
- 丢失数据不敏感的业务不开启AOF
8、使用Swap
分析:
- 所有请求全部开始变慢
- slowlog大量慢日志
- 查看Redis进程是否使用到了Swap
解决:
- 增加机器内存
- 集群扩容
- Swap使用时监控报警
9、进程绑定CPU不合理
分析:
- Redis进程只绑定一个CPU逻辑核
- NUMA架构下,网络中断处理程序和Redis进程没有绑定在同一个Socket下
解决:
- Redis进程绑定多个CPU逻辑核
- 网络中断处理程序和Redis进程绑定在同一个Socket下
10、开启透明大页机制
分析:
- 生成RDB和AOF重写期间,主线程处理写请求耗时变长(拷贝内存副本耗时变长)
解决:
- 关闭透明大页机制
11、网卡负载过高
分析:
- TCP/IP层延迟变大,丢包重传变多
- 是否存在流量过大的实例占满带宽
解决:
- 机器网络资源监控,负载过高及时报警
- 提前规划部署策略,访问量大的实例隔离部署
内存整理
40、如何判断是否有内存碎片?
info memory 命令里面的 mem_fragmentation_ratio指标就是 Redis 当前的内存碎片率
used_memory_rss 表示操作系统分配给 Redis 物理内存空间,里面包含了碎片,used_memory 表示 Redis 申请了多少空间 mem_fragmentation_ratio = used_memory_rss/ used_memory
41、怎么判断是否超过了阈值?
- mem_fragmentation_ratio 大于 1 但小于 1.5。这种情况是合理的。
- mem_fragmentation_ratio 大于 1.5 。这表明内存碎片率已经超过了 50%。一般情况下,这个时候,我们就需要采取一些措施来降低内存碎片率了。
42、如何清理内存碎片?
- 重启
- 4.0-RC3 版本以后,有自动清理的功能,压缩内存
43、Redis 怎么开启自动清理?
# 开启自动清理配置
config set activedefrag yes
44、redis 什么时候自动清理?
- active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到 100MB 时,开始清理;
- active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给 Redis 的总空间比例达到 10% 时,开始清理。
为了减轻自动清理对主线程的影响,redis 设置了两个参数用来保证:
- active-defrag-cycle-min 25:表示自动清理过程所用 CPU 时间的比例不低于 25%,保证清理能正常开展;
- active-defrag-cycle-max 75:表示自动清理过程所用 CPU 时间的比例不高于 75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞 Redis,导致响应延迟升高。
45、客户端为什么需要用到缓冲区?
- 一方面,可以在客户端控制发送速率,避免把过多的请求一下子全部发到 Redis 实例,导致实例因压力过大而性能下降。不过,客户端缓冲区不会太大,所以,对 Redis 实例的内存使用没有什么影响。
- 另一方面,在应用 Redis 主从集群时,主从节点进行故障切换是需要一定时间的,此时,主节点无法服务外来请求。如果客户端有缓冲区暂存请求,那么,客户端仍然可以正常接收业务应用的请求,这就可以避免直接给应用返回无法服务的错误。
库上的从库输出缓冲区(slave client-output-buffer)是不计算在Redis使用的总内存中的,也就是说主从同步延迟,数据积压在主库上的从库输出缓冲区中,这个缓冲区内存占用变大,不会超过maxmemory导致淘汰数据。只有普通客户端和订阅客户端的输出缓冲区内存增长,超过maxmemory时,才会淘汰数据。
46、怎么使用 redis 的慢日志?
设置阈值:
slowlog-log-slower-than:慢查询日志对执行时间大于多少微秒的命令进行记录。slowlog-max-len:记录多少条数,默认128,建议改成1k,底层是队列实现,超过阈值则被删除
slowlog get 1
47、如何排查 Redis 的 bigkey?
# 对整个数据库中的键值对大小情况进行统计分析
./redis-cli --bigkeys
48、Redis 做缓存的时候,缓存的类型有哪些?
- 只读缓存 修改数据则删掉缓存中的数据
- 读写缓存
49、怎么解决 Redis 做读写缓存时的缺陷?
- 可靠性保证:同步直写。写请求发给缓存的同时,也会发给后端数据库进行处理,等到缓存和数据库都写完数据,才给客户端返回。速度慢。
- 快速响应:异步写回。所有写请求都先在缓存中处理,等到这些增改的数据要被从缓存中淘汰出来时,缓存将它们写回后端数据库。如果掉电则丢失数据。
50、怎么设置 Redis 缓存的大小?
conifg set maxmemory 4gb
一般建议设置成总数据量的15% - 30%
51、缓存淘汰策略?
noeviction、volatile-ttl、volatile-random、volatile-lru、volatile-lfu、allkeys-lru、allkeys-lfu、allkeys-random
52、Redis 中的 Lru 算法有啥区别?
LRU 算法被做了简化,Redis会将最近访问时的时间戳记录在 Redis Object 中 lru 字段中,redis 执行定期淘汰策略,第一次选出 N 个数据,把其当成一个候选集合,然后比较这 N 个数据的 lru 的值,把 lru 最小的值淘汰出去。
# 设置 N 的大小,默认是5,建议改为10
CONFIG SET maxmemory-samples 10
# 容量大小
evictionPoolEntry 的容容量是 EVPOOL_SIZE = 16;
- 当再次进行定期淘汰的时候,再挑选一批新的数据,但是能进入集合的只有 lru 小于现集合最小的 lru 的值才可以,当达到了 maxmemory-samples 的值后,redis 把集合中lru最小的值踢掉。
- 每次淘汰的数量是根据内存量超过 maxmemory 的情况来决定的,所以每次加进集合的数据量也不是只有一个。
- 准备要淘汰的数据与淘汰数据是两个操作
- 当淘汰集合中没有位置的时候,新进来的数据小于最小 lru,集合头部存放的是最大的 lru,所以会把头部的数据依次移出集合,将更古老的数据存放到集合链表的尾部。
53、什么是缓存污染?
仅仅被访问少数次的数据被大量放在缓存里面
54、LFU 缓存策略的优化
LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 lfu 策略的时候,首先根据计数器筛选,把访问次数最低的淘汰出去,如果两个数据访问次数相同,则比较时间戳,淘汰最小的。
55、LFU 是怎么计算出数据的?
Redis 在实现 LFU 策略的时候,只是把原来 24bit 大小的 lru 字段,又进一步拆分成了两部分。
- 前16位为访问的时间戳
- 后8位为数据访问的次数
56、8 位最高才255,LFU 是怎么做的?
使用 非线性递增的计数器方法,
double r = (double)rand()/RAND_MAX;
// baseval是计数器,初始默认值是 5,LFU_INIT_VAL 常量设置,避免数据刚被写入缓存,就因为访问次数少而被立即淘汰
double p = 1.0/(baseval * server.lfu_log_factor + 1);
if (r < p) counter++;
57、LFU 的衰减策略是什么?
Luf 的次数不能只加不减,所以有衰减策略,如果 lfu_decay_time 为 1 的话,N 分钟就要被减 N,如果设置的很大则会衰减的缓慢很多。
58、Redis 针对过期数据的删除策略有哪些?
- 惰性删除
- 定期删除
- 定时删除
60、Redis 主从模式下过期数据有什么问题?
- 惰性删除时,访问从库并不会触发主库的删除策略,3.2 以前读取过期数据,从库会返回过期数据,3.2 以后返回空值
- EXPIRE 和 PEXPIRE:它们给数据设置的是从命令执行时开始计算的存活时间,可能会导致数据延迟
可以使用 EXPRIEAT / PEXPIREAT 时间戳 来控制统一的过期事件
61、主从的一个小问题 protected-mode
如果设置 protected-mode yes 的话,哨兵只能被当前服务器的实例访问,会引发一系列的问题,建议设置为no,并且 bind 参数设置为主从节点的 ip
62、为什么脑裂导致了redis的部分数据丢失?
在脑裂的时候有服务还在连接原来的主库,哨兵集群判断主库下线,从库被选举为主库,而等 redis 原主库回复的时候,服务写在原服务里面的数据因为redis被变成 现主库的从库,要发生一次全量复制,导致期间产生的数据丢失。
63、如何应对脑裂问题?
- min-slaves-to-write:设置了主库能进行数据同步最少的从库数量 N
- min-slaves-max-lag:设置从库给主库发送ack消息的最大延迟 T
如果主库连接从库数量少于N,或主从数据复制时ack消息延迟超过T,则主库不会接收客户端发来的消息了
64、若从库能删数据,有什么风险??
- 原本主库快要过期的 key 用 expire 续命了,但是因为有延迟,从库正好也删掉了,就会导致数据不一致
- 主从库的时钟不同步,导致主从库删除时间不一致
65、如何理解把 Redis 称为旁路缓存?
业务应用在使用 Redis 缓存时,需要在业务代码中显式地增加缓存的操作逻辑。
66、秒杀支持
- 前端静态页面的设计,秒杀页面能静态化的都要静态化,充分利用 CDN 与浏览器缓存
- 请求拦截和流控,拦截恶意请求,为防止 Redis 流量过大,在接入层进行限流,如控制进入秒杀的数量
- 库存信息过期时间处理,不给秒杀商品设置过期事件,防止击穿
- 数据库订单异常处理,如果数据库没能处理成功,增加重试功能,保证订单能被最终处理
- 秒杀数据单独保存,建议秒杀商品的信息用单独的实例去保存
67、数据倾斜是怎么产生的?
- bigkey
- Slot 分配不均衡,CLUSTER SLOTS 可查看 slot 的信息
- Hash Tag
68、数据倾斜的解决方案
数据倾斜基本原因还是热点数据的问题,同长缓存还是读多一些,可以采用热点数据多副本的方式,把热点数据复制多份,在每个数据副本前增加一个前缀,这样热点数据的压力被分散到不同的实例上去了
此方法只针对 读热点数据
69、Redis cluster 集群通讯方式 gossip 是什么原理?
- 集群中的会按照一定的频率选出一些实例,把ping命令发送给选出的实例,交换彼此的信息,ping中封装了发送消息的实例自身的状态信息、部分其他实例的状态信息,以及 slot 表
- 一个实例接收到 ping 后,会发送 pong 给消息实例,包含的信息与 ping 一样
Gossip 协议可以保证在一段时间后,集群中的每一个实例都能获得其它所有实例的状态信息。

