
KNN(K近邻算法)分类问题
-
1.分类问题(物以类聚)
学会 kNN 算法,只需要三步:
-
了解 kNN 算法思想
-
掌握它背后的数学原理(别怕,初中就学过,欧式距离)
-
最后用简单的 Python 代码实现
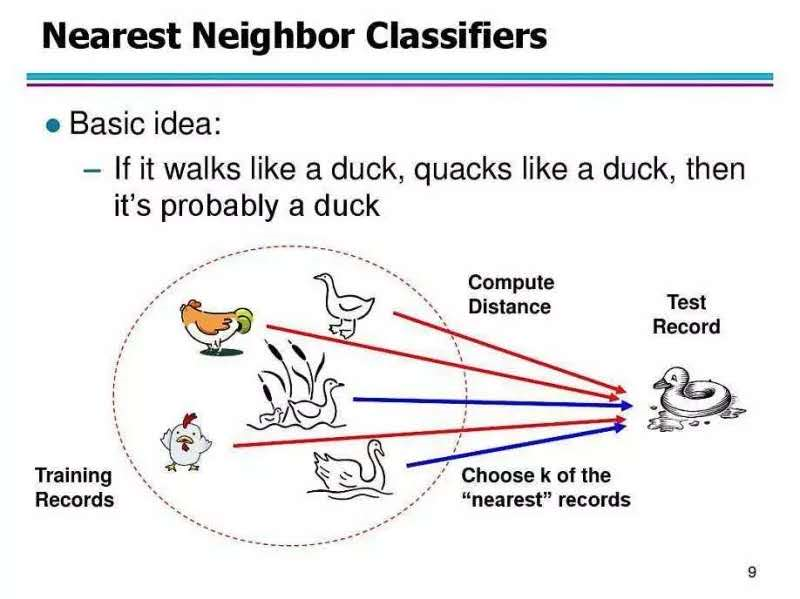
公众号【高级农民工】2019-06-04的文章“Python手写机器学习最简单的KNN算法”,作者举了个特别易懂的场景来解释KNN。
https://blog.csdn.net/weixin_42232219/article/details/91350124
酒吧老板:你眼前的这十杯红酒,每杯略不相同,前五杯属于「赤霞珠」,后五杯属于「黑皮诺」。现在,我重新倒一杯酒,你只需要根据刚才的十杯正确地告诉我它属于哪一类。
你没有急着品酒而是问了老板每杯酒的一些具体信息:酒精浓度、颜色深度等,以及一份纸笔。老板一边倒一杯新酒,你边疯狂打草稿。很快,你告诉老板这杯新酒应该是「赤霞珠」。
老板问怎么做到的,你说:无他,但机器学习熟尔。
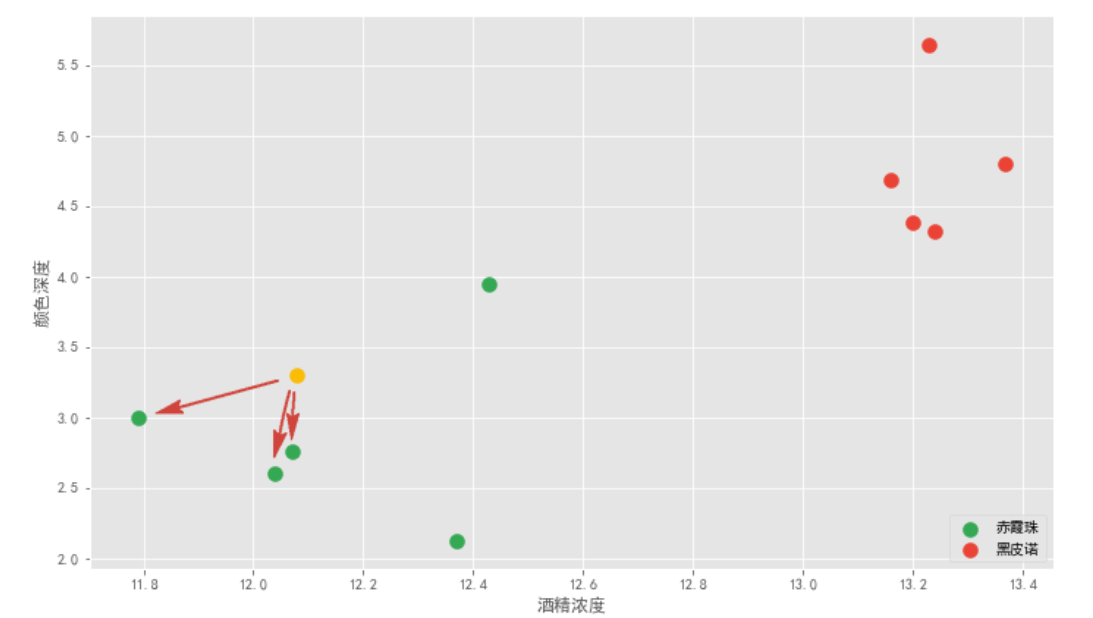
上面的每一杯酒称作一个「样本」,十杯酒组成一个样本集。酒精浓度、颜色深度等信息叫作「特征」。这十杯酒分布在一个多维特征空间中。说到空间,我们最多能感知三维空间,为了理解方便,我们假设区分赤霞珠和黑皮诺,只需利用:酒精浓度和颜色深度两个特征值。这样就能在二维坐标轴来直观展示。
该算法首先需要取一个参数 K,机器学习中给的经验取值是 3,我们假设先取 3 ,具体取多少以后再研究。对于每个新来的点,K 近邻算法做的事情就是在所有样本点中寻找离这个新点最近的三个点,统计三个点所属类别然后投票统计,得票数最多的类别就是新点的类别。
1.原理:它的本质就是通过距离判断两个样本是否相似,如果距离够近就觉得它们相似属于同一个类别。当然只对比一个样本是不够的,误差会很大,要比较最近的 K 个样本,看这 K 个 样本属于哪个类别最多就认为这个新样本属于哪个类别。
2.数学原理
欧拉公式
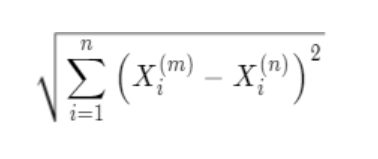
3.Python代码实现
作者提供的代码要用jupyter notebook打开,鼓捣半天还没打开,先睡了。。。
机器学习 -- KNN算法(Ⅲ 肿瘤预测案例 -- 封装成函数)https://blog.csdn.net/m0_38056893/article/details/102987230?ops_request_misc=%7B%22request%5Fid%22%3A%22158181892419724847039085%22%2C%22scm%22%3A%2220140713.130056874..%22%7D&request_id=158181892419724847039085&biz_id=0&utm_source=distribute.pc_search_result.none-task
1 import numpy as np 2 3 from collections import Counter 4 5 6 def kNN_classify(k, X_train, y_train, x): 7 """ 8 9 kNN分类实现 10 11 :param k: 选取的最近k个点 12 13 :param X_train: 训练集的特征值 14 15 :param y_train: 训练集的目标值 16 17 :param x: 待预测数据集 18 19 :return: 预测结果 20 21 """ 22 23 # 用断言保证用户输入数据合法 24 25 assert 1 <= k <= X_train.shape[0], "k必须为有效值" 26 27 assert X_train.shape[0] == y_train.shape[0], "训练集X和y的大小必须相同" 28 29 assert X_train.shape[1] == x.shape[0], "待测数据x的特征数必须和训练集X一致" 30 31 # 获取所有样本点和待测点的距离 32 33 distances = [] 34 35 for x_train in X_train: 36 d = (np.sum((x_train - x) ** 2)) ** 0.5 37 38 distances.append(d) 39 40 sorted_index = np.argsort(distances) 41 42 top_K = [y_train[i] for i in sorted_index[:k]] 43 44 return Counter(top_K).most_common(1)[0][0] # [(1, 5)] 45 46 47 def loadData(): 48 """ 49 50 加载数据集(这里只是通过手动的方式构造数据集,之后会使用文件读取的方式) 51 52 :return: 训练集的特征值X_train的numpy数组, 训练集的目标值y_train的numpy数组 53 54 """ 55 56 raw_data_X = [[3.3935, 2.3312], 57 58 [3.1101, 1.7815], 59 60 [1.3438, 3.3684], 61 62 [3.5823, 4.6792], 63 64 [2.2804, 2.8670], 65 66 [7.4234, 4.6965], 67 68 [5.7451, 3.5340], 69 70 [9.1722, 2.5111], 71 72 [7.7928, 3.4241], 73 74 [7.9398, 0.7916]] 75 76 raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] 77 78 X_train = np.array(raw_data_X) 79 80 y_train = np.array(raw_data_y) 81 82 return X_train, y_train 83 84 85 if __name__ == "__main__": 86 # 获取数据集 87 88 X_train, y_train = loadData() 89 90 # 待预测数据 91 92 x = np.array([8.0936, 3.3657]) 93 94 k = 6 95 96 print(kNN_classify(k, X_train, y_train, x))
输出结果:1
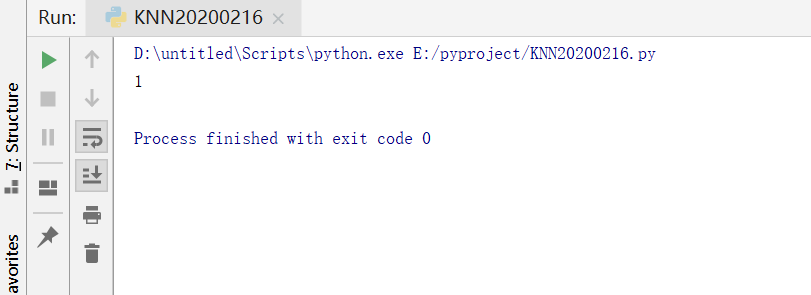
以上代码在Pycharm 运行成功,文件名为“KNN20200216”
-
问题1 :怎样用读取文本的方式加载数据集???
-
问题2:尝试用sklearn写KNN
-
问题3:代码92行 预测数据怎么写多个???
KNN特别适合多分类问题(multi-modal,对象有多个类别标签),优于其他机器学习算法,也最简单。KNN分类很容易理解,就是物以类聚的思想,找到和样本特征最近的几个。
要学会Excel中数据怎么矩阵做参数?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号