
一 爬虫框架(scrapy)
一 .scrapy
https://www.cnblogs.com/wupeiqi/p/6229292.html
1.scrapy简介
Scrapy 是一个用 Python 实现的为了爬取网站数据、提取结构性数据的应用框架。
Scrapy 使用Twisted异步网络库来处理网络通讯。
使用 Scrapy 框架可以高效(爬取效率和开发效率)完成网站数据爬取任务。
pip install pywin32
pip install zope.interface
pip install Twisted
pip install pyOpenSSL
pip install Scrapy
2. 创建项目
创建:
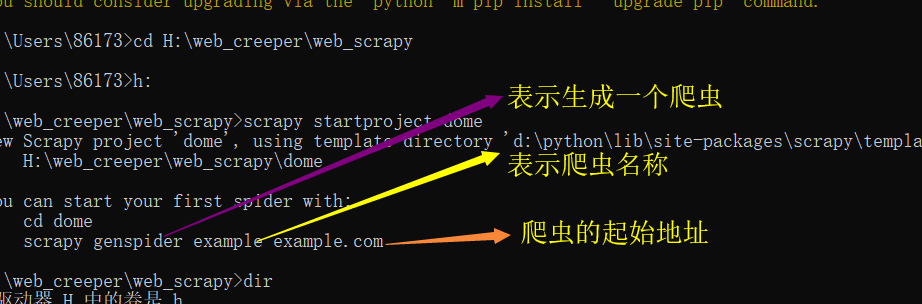
scrapy startproject Demo 第一: 创建启动项目 H:\web_creeper\web_scrapy>scrapy startproject dome New Scrapy project 'dome', using template directory 'd:\python\lib\site-packages\scrapy\templates\project', created in: H:\web_creeper\web_scrapy\dome You can start your first spider with: cd dome scrapy genspider example example.com 表示生成一个爬虫 表示爬虫名称 爬虫的起始地址 H:\web_creeper\web_scrapy\dome> scrapy genspider baidu baidu.com 第二部: 创建爬虫 第三步: 启动爬虫 scrapy crawl chouti 默认要打印日志
scrapy crawl baidu --nolog 不打印日志
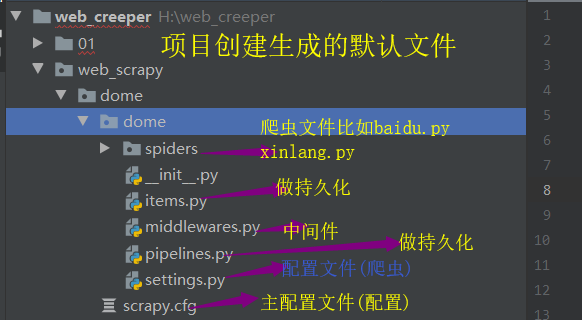
爬虫项目的目录结构:
items.py:用来存放爬虫爬取的数据的模型
middlewares.py:用来存放各种中间件的文件
pipelines.py:用来将items的模型存储到本地磁盘
settings.py:存储本爬虫的一些配置信息,比如:请求头、ip代理池等
spiders目录:存储所有的爬虫代码
scrapy.cfg:项目的配置文件

关于windows编码
# -*- coding: utf-8 -*- import sys,os,io sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') import scrapy class BaiduSpider(scrapy.Spider): name = 'baidu' # 爬虫名称 allowed_domains = ['baidu.com'] # allowed_domains 定向爬虫(就是只爬一个网址) start_urls = ['http://baidu.com/'] # 起始url def parse(self, response): # 回调函数 封装了所有响应数据 print(response,type(response),111111111111111) print(response.text)
scrapy parse函数为什么执行了,打印不了内容 解决: 1.找到settings.py配置文件 把ROBOTSTXT修改为False 2.然后退出重启一下scrapy(pychram) 3.直接启动项目scrapy crawl baidu --nolog(不打印日志)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号