

五. 爬虫 正则表达式
一 正则表达式
https://www.cnblogs.com/Sup-to/p/10854522.html
1. re模模块
1.基本用法
re.findall(正则匹配的格式,匹配的对象)
2.正则匹配常用格式
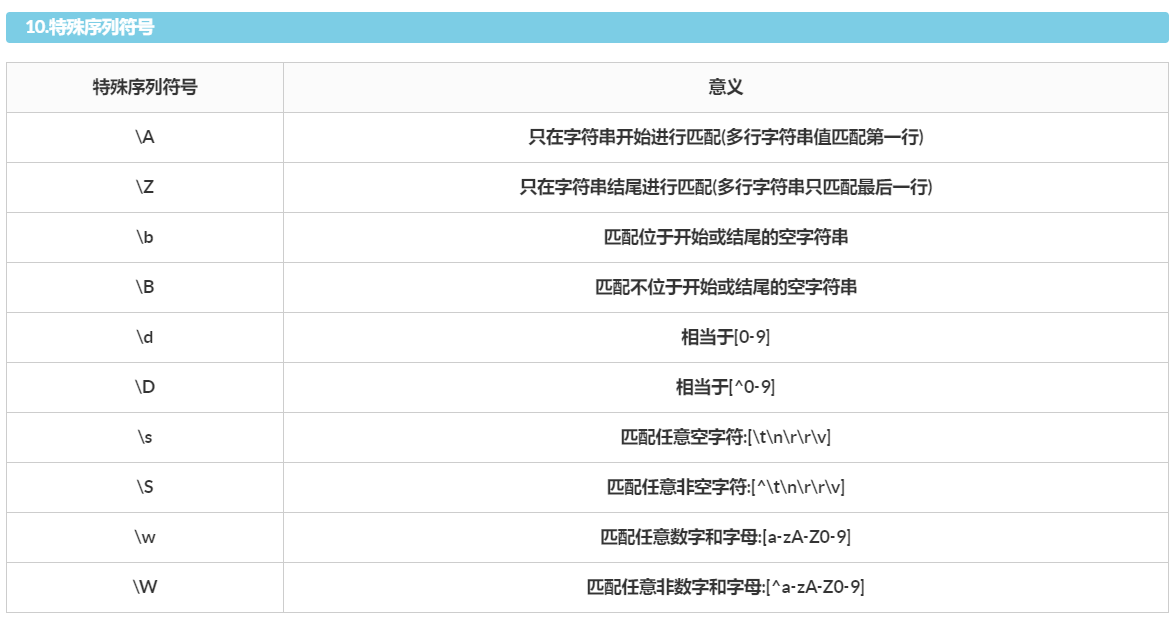
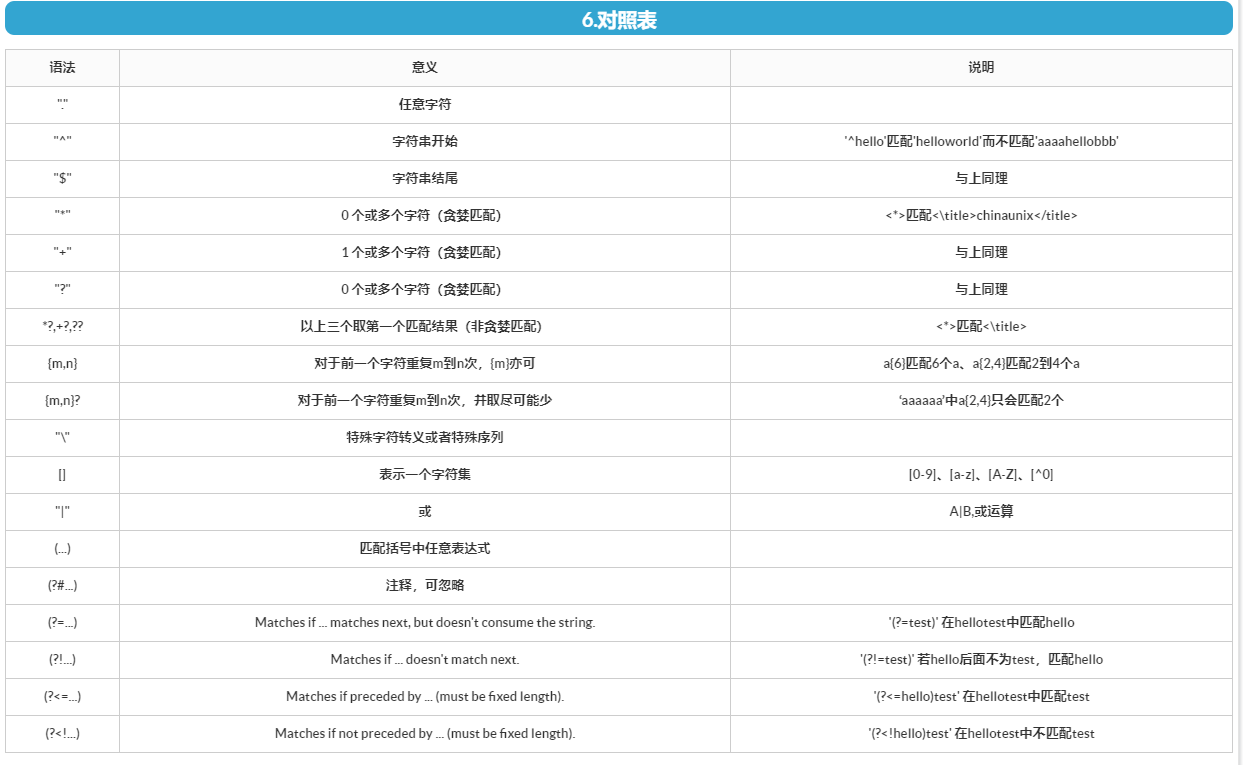
1.^ 只匹配开头在多行模式中匹配每一行的开头 2.a|b 匹配的格式a或者b 3[] [a,b]匹配的格式a或者b如果ab为多个值他会把里面的东西打散 [1-9]数字1-9 [a-z]字母a-z [A-Z]字母A-Z [^x]内容不等于x 4.$ a$ 匹配已a 结尾的 5.. 代表任意字符 6.{} {n}代表大括号前字符n个 {n,m}代表大括号前字符n-m个 {n,}代表大括号前字符n-多个 {+,}代表大括号前字符1-多个 {0,}代表大括号前字符0-多个
7.* 代表前面字符0-无穷大个 8.+ 代表前面字符1-无穷大个 9.? a?代表a字符0-1个 ?a,前面值是+或者*的时候?匹配内容a结束
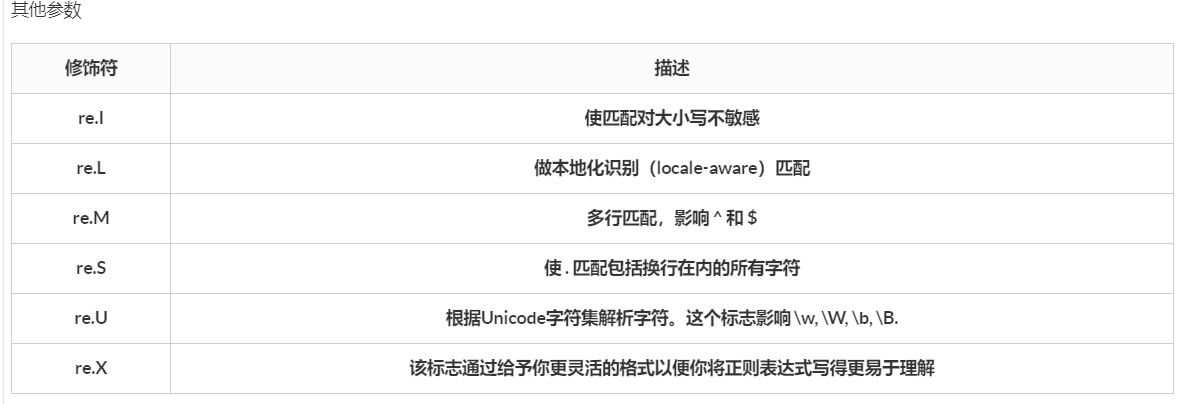
3.re.findall(正则匹配的格式,匹配的对象,re.S)
re.S的作用:
不使用re.S时,则只在每一行内进行匹配,如果存在一行没有,就换下一行重新开始,使用re.S参数以后,正则表达式会将这个字符串看做整体,在整体中进行匹配
import re a = """sdhellolsdlfsdfiooe: yy988989pythonafsf""" b = re.findall('hello(.*?)python',a) c = re.findall('hello(.*?)python',a,re.S) print (b) print(c) 输出结果: b:[] c:['lsdlfsdfiooe:\nyy988989']
4.re.match和re.search
# match 和 search的区别,mathch从开头开始匹配找一个,search搜索所有找第一个
5.re.compile
定义某种搜索格式 res1 = re.compile('\d+') res1.findall(查找对象)等同于re.findall('\d+',查找对象)
6.re.split()
就是字符串的split方法,区别是可以使用正则表达式去替换
7.re.sub和re.subu
就是字符串的replace方法,区别是可以使用正则表达式去替换 import re s = '猪八戒的媳妇是1高翠兰,孙悟空的媳妇是2白骨精,唐僧的媳妇是3女儿国王,沙悟净6没有媳妇(py9的学生们)' print(re.sub('\d','',s)) print(re.subn('\d','',s)) # 除了会修改内容,还会返回修改了多少次 猪八戒的媳妇是高翠兰,孙悟空的媳妇是白骨精,唐僧的媳妇是女儿国王,沙悟净没有媳妇(py的学生们) ('猪八戒的媳妇是高翠兰,孙悟空的媳妇是白骨精,唐僧的媳妇是女儿国王,沙悟净没有媳妇(py的学生们)', 5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号