
python爬虫-提取网页数据的三种武器
常用的提取网页数据的工具有三种xpath、css选择器、正则表达式
1.xpath
1.1在python中使用xpath必须要下载lxml模块:
lxml官方文档 :https://lxml.de/index.html
pip install lxml
然后导入:
from lxml import etree
使用:
selector = etree.HTML(html_str)
selector.xpath("xpath语法")
1.2xpath语法
w3c xpath语法:https://www.w3school.com.cn/xpath/index.asp
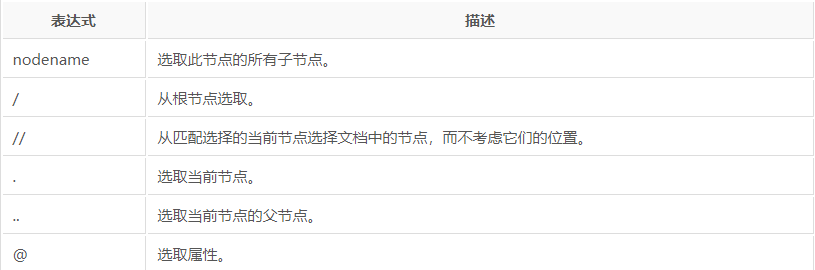

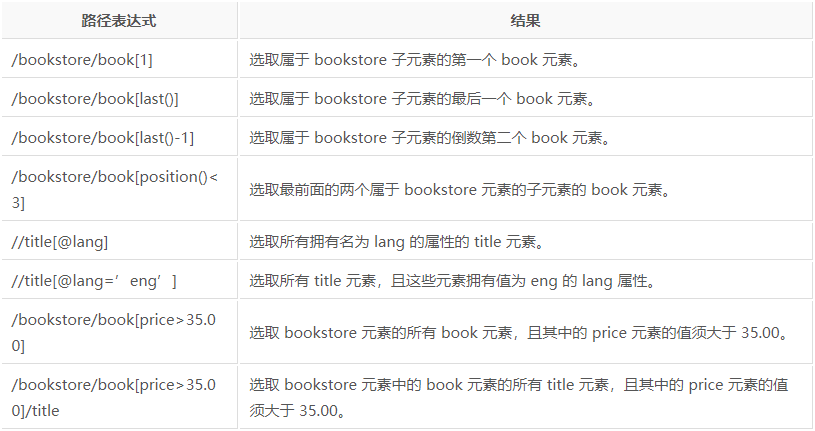

以上是获取元素的语法,但我们最终的目的是获取元素里面的属性信息或文本信息
from lxml import etree html_str = ''' <div class="example1"> <a href="http://www.baidu.com/" data-id="12345678">百度</a> </div> <div class="example2"> <a href="https://cn.bing.com/" data-id="23456789">Bing</a> </div> ''' response = etree.HTML(html_str)
获取属性data-id信息:
data-id = selector.xpath("//div[@class='example1']/@data-id")[0]
获取文本信息:
text = selector.xpath("//div[@class='example2']/a/text()")[0]
2.selector
2.1cssselect
使用css选择器也是使用lxml这个模块
使用:
selector = etree.HTML(html_str)
selector.cssselect("css语法")
异常:
有的人在使用selector.cssselect("css语法")的时候,会报错cssselect没有安装,我们使用dir(selector)的时候,会发现selector的属性方法中有cssselect这个方法,之所以报错,是因为这个
方法是依赖于cssselect这个模块中,所以要安装cssselect这个模块
安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple cssselect
2.2css语法
基本的父代、子代、后代、祖辈我们就不用说了,今天主要想记录的是如何获取属性值和文本
from lxml import etree html_str = ''' <div class="example1"> <a href="http://www.baidu.com/" data-id="12345678">百度</a> </div> <div class="example2"> <a href="https://cn.bing.com/" data-id="23456789">Bing</a> </div> ''' response = etree.HTML(html_str)
获取文本:
# 获取文本用text属性
text = selector.cssselect("div.example1 a")[0].text
获取属性值:
# 获取属性值用get(attr)方法 link = selector.cssselect("div.example2 a")[0].get("href")
3.正则表达式
3.1在Python中使用正则表达式必须导入Python内置的re模块
import re
3,2常用的匹配方法有re.match()、re.search()、re.findall()
re.match(pattern, string, flag)
re.search(pattern, string, flag)
re.findall(pattern, string, flag)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、多行匹配等等(可选参数)
3.2.1pattern
^ 匹配字符串的开头
$ 匹配字符串的结尾
. 匹配任意字符(包括\r),除了换行符
[...] 匹配一组字符中的任意一个字符
[^...] 匹配不在一组字符中的任意字符
* 匹配0个或多个表达式
+ 匹配1个或多个表达式
? 匹配0个或1个表达式,非贪婪方式
{n} 匹配n个前面的表达式
{n,}
{n,m} 匹配n到m次前面的表达式,贪婪模式
a|b 匹配a或b
() 对正则表达式分组并记住匹配的文本
\w 匹配字母数字下划线(Python中包括汉字)
\W 匹配非字母数字下划线
\s 匹配任意空白字符,等价于[\t\r\n\g]
\S 匹配任意非空字符
\d 匹配任意数字,等价于[0-9]
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果存在换行,只匹配到换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\b 匹配一个单词的边界,也就是指单词和空格间的位置。例如:‘er\b’可以匹配never中的er,但是不能匹配到verb中的er
\B 匹配一个非单词的边界
\n、\t等 匹配一个换行符
\1...\9 匹配n个分组的内容
\10 匹配第n个分组的内容,如果他经匹配,否则指的是八进制字符码的表达式
3.2.2string
该参数既可以为字符型字符串,也可以为二进制行字符串
3.2.2.1当string为字符型字符串时
import re string = "token:dsasdfva13421hb4v4b141jjb4bj1jbb汉字是世界上最难的文字" # 匹配token值 re.findall(r"token:([0-9a-zA-Z]+)", string) # 执行结果 ['dsasdfva13421hb4v4b141jjb4bj1jbb']
3.2.2.2当string为二进制型字符串时
import re import socket # 发送图片请求,并返回一个响应报文 s = socket.socket() s.connect(("desk-fd.zol-img.com.cn", 80)) s.send("GET /t_s960x600c5/g5/M00/0E/08/ChMkJl3g7o-Ibp4nAAYg0I-lImUAAvfjgFkfbYABiDo544.jpg HTTP/1.1\r\nHost: desk-fd.zol-img.com.cn\r\n\r\n".encode()) res_content = s.recv(1024) s.settimeout(2) full_content = b'' while res_content: try: full_content += res_content res_content = s.recv(1024) except: break s.close() # 从响应报文中提取出响应体(图片二进制数字),需了解报文的结构 re.findall(b"\r\n\r\n(.+)", full_content)
3.2.3flags(可选参数)
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(|)它们来指定。如
re.I|re.M被设置成I和M标志:
re.I 使匹配对大小写不敏感
re.L 使本地化识别(locale-aware匹配)
re.M 多行匹配,影响^和$
re.S 使.匹配包括换行在内的所有字符
re.U 根据Unicode字符集。这个标志影响\w,\W,\b,\B
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
3.3re.search()、re.match、re.findall()
3.3.1match(pattern,string,flags) 只匹配开头
匹配不到返回:None
匹配到返回:
re.match("(\d)", "123")
<re.Match object; span=(0, 1), match='1'>
匹配到就使用group(num=0)、groups()取值
group(num=0)
# 序号0为正则表达式匹配到的内容 re.match("\d\d\d", "12345566").group(0) # 默认num为0 # '123' # 序号1为正则表达式第一个括号的内容 re.match("(\d)(\d)(\d)", "12345566").group(1) # '1' # 序号2为正则表达式第二个括号的内容 re.match("(\d)(\d)(\d)", "12345566").group(2) # '2' # 序号3为正则表达式第三个括号的内容 re.match("(\d)(\d)(\d)", "12345566").group(3) # '3' # 返回匹配到的内容所有分组元组 re.match("(\d)(\d)(\d)", "12345566").groups() # ('1','2','3')
3.3.2search(pattern,string,flags)全文匹配一次
匹配不到返回:None
匹配到返回:
re.search("(\d)(\d)", "123")
<re.Match object; span=(0, 2), match='12'>
匹配到就使用group(num=0)、groups()取值
# 序号0为正则表达式匹配到的内容 re.search("\d\d\d", "as12345566").group(0) # 默认num为0 # '123' # 序号1为正则表达式第一个括号的内容 re.search("(\d)(\d)(\d)", "as12345566").group(1) # '1' # 序号2为正则表达式第二个括号的内容 re.search("(\d)(\d)(\d)", "as12345566").group(2) # '2' # 序号3为正则表达式第三个括号的内容 re.search("(\d)(\d)(\d)", "as12345566").group(3) # '3' # 返回匹配到的内容所有分组元组 re.search("(\d)(\d)(\d)", "as12345566").groups() # ('1','2','3')
3.3.3findall(pattern,string,flags)全文匹配
匹配不到返回:[]
匹配到返回:一个列表(如果没有分组,就返回匹配正则表达式的所有匹配到的项,如果分组就会返回匹配到的项中的分组组成的一个元组的所有项)
re.findall("\d\d", "123123432345") # 结果 ['12', '31', '23', '43', '23', '45']
re.findall("(\d)(\d)", "123123432345") # 结果 [('1', '2'), ('3', '1'), ('2', '3'), ('4', '3'), ('2', '3'), ('4', '5')]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号