



java的垃圾回收算法
在正式谈论垃圾回收算法之前,我们看一看运行时的数据区域分布:
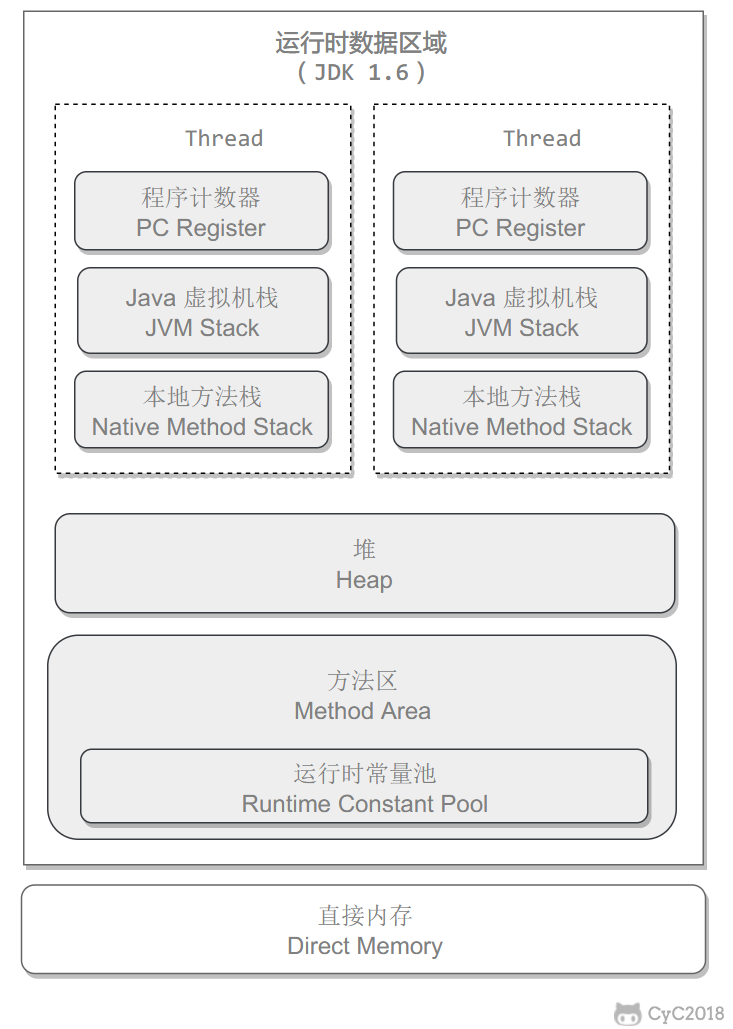
垃圾回收主要是针对堆和方法区进行的。因为程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,因存在于线程的生命周期内,当线程结束之后就会小时,因此不需要对这三个区域进行回收。
垃圾回收算法:
判断一个对象是否可被回收,然后采用相应的垃圾收集算法。
判断对象是否可被回收:引用计数法、可达性分析法
垃圾收集算法:标记-清除、标记-整理、复制、分代收集
以下单独介绍:
1.引用计数算法
原理:为对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收。
缺点:当两个对象出现循环引用,即互相引用的情况下,此时引用计数器永远不为0,导致无法对其回收。故Java虚拟机不使用该回收算法。
2.可达性分析算法
以GC(堆) Roots为起始点进行搜索,可达的对象都是存活的,不可达的对象将被回收,如下图,Object4将被回收。

Java虚拟机使用该算法来判断对象是否可被回收,其中GC Roots一般有以下内容:
- 虚拟机栈中局部变量表中引用的对象
- 本地方法栈中 JNI 中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象
3.方法区的回收
主要是对常量池的回收和对类的卸载(对类进行卸载,一般情况下是为了避免内存溢出)
在卸载类之前,需要满足三个条件(满足也不一定会被卸载)
- 该类的所有实例都已经被回收,也就是堆中不存在该类的任何实例
- 加载该类的ClassLoader已经被回收
- 该类对应的对象没有被引用
4.finalize()
当一个对象可被回收时,如果需要执行该对象的 finalize() 方法,那么就有可能在该方法中让对象重新被引用,从而实现自救。自救只能进行一次,如果回收的对象之前调用了 finalize() 方法自救,后面回收时不会再调用该方法。
垃圾收集算法
1.标记-清除
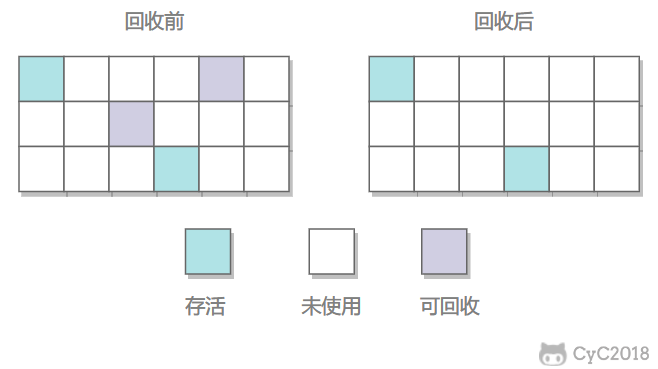
在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
在清除阶段,会进行对象回收并取消标志位,另外,还会判断回收后的分块与前一个空闲分块是否连续,若连续,会合并这两个分块。回收对象就是把对象作为分块,连接到被称为 “空闲链表” 的单向链表,之后进行分配时只需要遍历这个空闲链表,就可以找到分块。
在分配时,程序会搜索空闲链表寻找空间大于等于新对象大小 size 的块 block。如果它找到的块等于 size,会直接返回这个分块;如果找到的块大于 size,会将块分割成大小为 size 与 (block - size) 的两部分,返回大小为 size 的分块,并把大小为 (block - size) 的块返回给空闲链表。
不足:
- 标记和清除过程效率都不高;
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
2.标记-整理
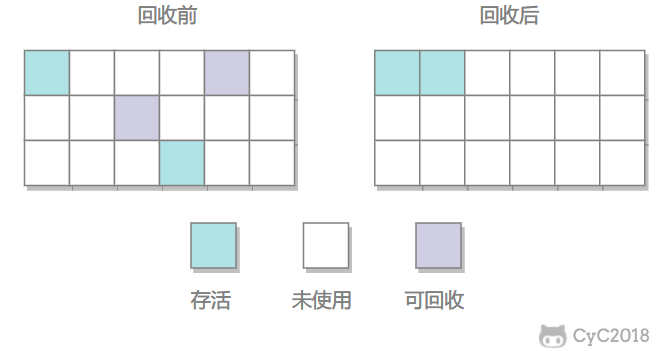
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
优点:不会产生内存碎片
缺点:需要大量移动对象,处理效率比较低
3.复制
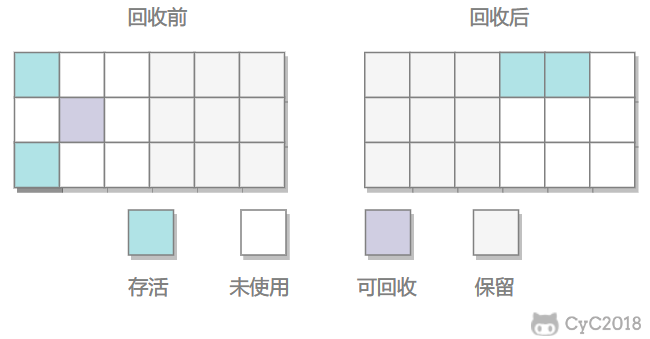
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
不足:只使用内存的一半
4.分代收集
现在的商业虚拟机采用分代收集算法,它根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。
一般将堆分为新生代和老年代
- 新生代使用:复制算法
- 老年代使用:标记 - 清除 或者 标记 - 整理 算法
垃圾收集器
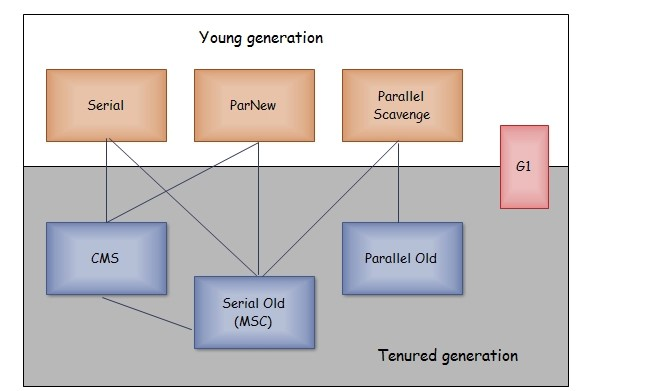
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
CMS收集器:在进行一定次数的标记清除之后进行一次标记整理算法。它的收集过程分为四个步骤:初始标记、并发标记、重新标记、并发清除。在耗费时间更长的并发标记和并发清除两个阶段都可以和用户进程同时工作。
详情请点击链接:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E8%99%9A%E6%8B%9F%E6%9C%BA.md

