
链表中head->next = p;和p=head->next;之间的区别
最近这两天在看递归,然后,看了几个例子,其中有一个单链表反转的例子可以使用递归解决,但是这里却有一个问题让我迷惑了一会,就是链表操作中这两句话的含义:
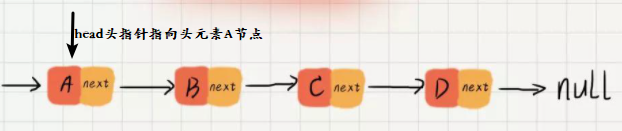
以下图中的单向链表为例:
Node preNode = null;
Node nextNode = null;
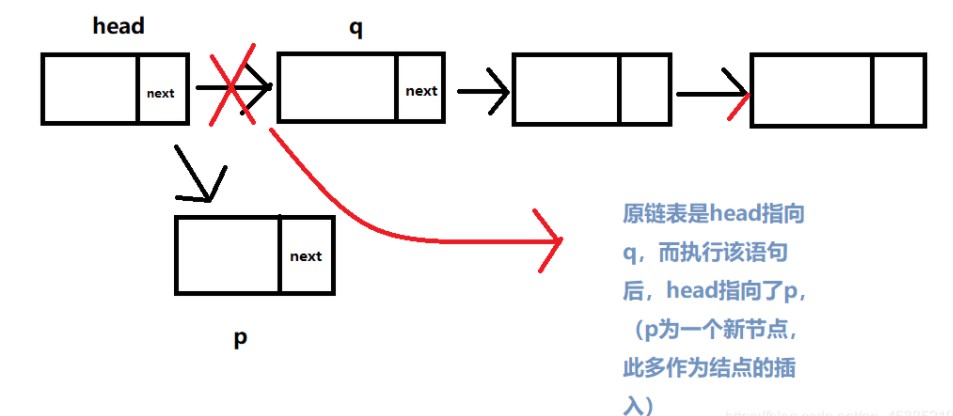
nextNode = head.next;//1
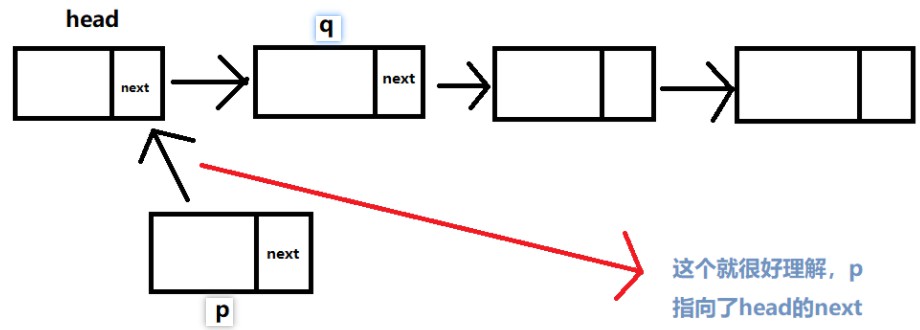
head.next = preNode;//2
第1行语句:head.next为2这个结点,获得这个结点后将其赋值给了nextNode变量值。
第2行语句:正确的含义是将head头指针指向preNode这个null结点。但是我刚开始有个误区就是,可能工作中用到链表的时候很少,也没刷过题,最近才开始看数据结构和算法部分,我想着head.next不就是2结点么此时,将null结点赋值给2结点,但是这样是不对的,不知道大家是否会和我一样会这样想,觉得有误区,一会搞不明白。
我这里把我想的说下,就是加入我们就按照上面我想的思路走,看看会发生什么,就知道为啥这样理解是不对的了。即head.next是2结点此时,将null结点赋值给2结点,那我们通过1结点向后查找后一个结点的时候,结点还为2,那此时2结点到底为null,没有data值,还是有值为B嘞,这样是不是互相矛盾了。
接下来画下图,看的更清楚一些:
nextNode = head.next含义图:
head.next = preNode含义图:
有了上面的理解后,今天晚上准备再写个反转链表的文章,趁热打铁。希望快快进步呀,加油嘻嘻,我也学会文章里加可爱的图了,有时候读着亲切可爱,让略显枯燥的代码生活增添一丝乐趣,可以更好地搬砖哈哈哈

艾欧尼亚,昂扬不灭,为了更美好的明天而战(#^.^#)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构