图中使用的数据结构 : 邻接矩阵 & 邻接表
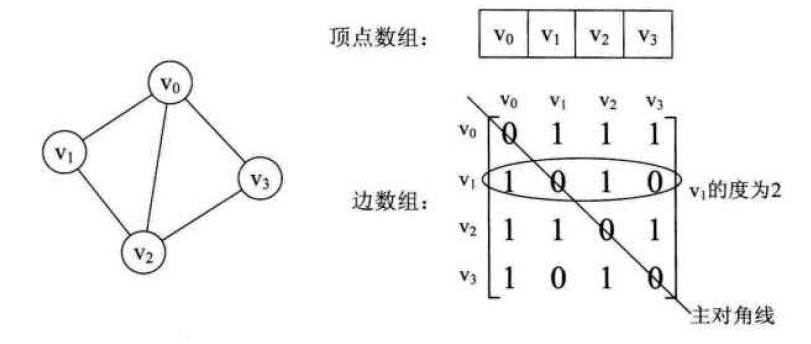
邻接矩阵
图的逻辑结构分为两部分:V(点)和E(边)的集合。因此用一个一维数组存放图中所有顶点数据;用一个二维数组存放顶点的关系(边或弧)的数据,称这个二维数组为邻接矩阵。邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。
无向图示例:
有向图示例:
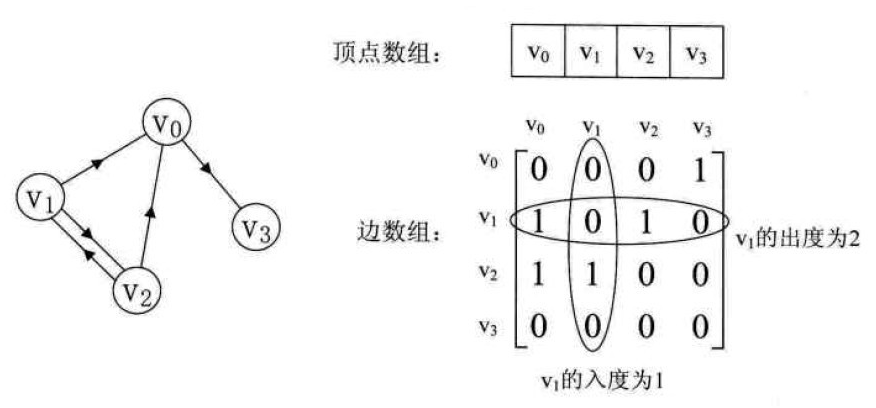
邻接链表(adjacency list)
邻接矩阵是不错的一种图存储结构,但是对于边数相对顶点较少的图,这种结构是存在对存储空间的极大浪费。比如说对于以下这样的稀疏图,邻接矩阵中除了a[1][0]有权值以外,没有其他狐,因此对于矩阵而言,大多数存储空间都浪费了。
图结构如下所示:
图结构对应的矩阵表示(有向图,非对称)
[[0 0 0 0 0]
[1 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]]
对应python代码:
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
G = nx.DiGraph()
G.add_nodes_from(["v0", "v1", "v2", "v3", "v4"])
G.add_edge("v1", "v0")
nx.draw(G, with_labels=True)
plt.show()
A = np.array(nx.adjacency_matrix(G).todense())
print(A)
图结构如下所示:

图结构对应的矩阵表示 (无向图,对称)
[[0 1 0 0 0]
[1 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]]
对应python代码:
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
G = nx.Graph()
G.add_nodes_from(["v0", "v1", "v2", "v3", "v4"])
G.add_edge("v0", "v1")
nx.draw(G, with_labels=True)
plt.show()
A = np.array(nx.adjacency_matrix(G).todense())
print(A)
鉴于以上原因,选择一种新的数据结构来存储稀疏图就有必要了。邻接表就是用于存储原来的连接信息。
邻接表处理如下:
1、图中所有顶点用一个一维数组存储。顶点也可以用单链表来存储,不过数组可以较容易的读取顶点信息。另外对于顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,以便于查找该顶点的边信息。
2、图中每个顶点Vi的所有邻接点构成一个线性表。由于邻接点的个数不确定,所以使用单链表存储。在无向图中称为顶点vi的边表,在有向图中称为顶点vi的作为弧尾的出边表。
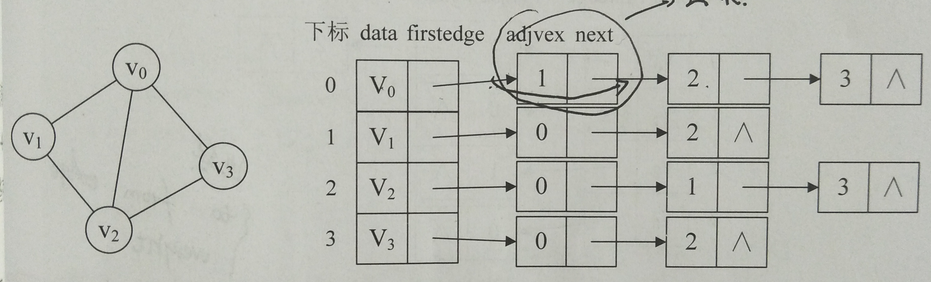
从图中知道,定点表的各个结点由data和firstedge两个域表示。data是数据域,存储顶点信息;firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。
(直白点就是创建一个对象数组,用于存储顶点信息。每个对象包括两部分元素,顶点域和边域。顶点域是顶点信息,边域是单向链表的首地址地址,链表里记录了该该顶点的所有边信息)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号