
nginx的http负载均衡
注意:nginx自带的http服务后端检测有缺陷,无法根据状态码来检测,建议使用tengine的nginx_upstream_check_module来实现后端服务的http健康状态检测
(1)负载均衡简介
作用:提升吞吐率,提升请求性能,提高容灾
负载均衡按层级划分
四层负载均衡:ip+tcp端口,
七层负载均衡:处理http层,例如根据主机地址调度
nginx实现负载均衡用到了proxy_pass代理模块核心配置,将客户端请求代理转发至一组upstream虚拟服务池
ngx_http_proxy_module //proxy代理模块
ngx_http_upstream_module //负载均衡模块,可以实现网站的负载均衡功能及节点的健康检查。nginx自带的健康状态不好用
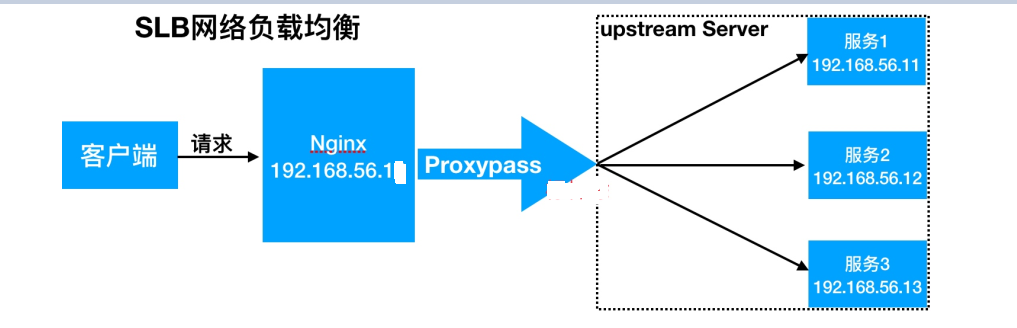
(2)负载均衡基本实现
0.语法和例子
upstrem name { .... }
必须要配置http标签之内和server标签之外

1.web服务器配置
#vim /usr/local/nginx/conf/nginx.conf
server {
listen 8001;
root /webroot/node1;
index index.html;
}
server {
listen 8002;
root /webroot/node2;
index index.html;
}
server {
listen 8003;
root /webroot/node3;
index index.html;
}
#nginx -t
#mkdir -pv /webroot/{node1,node2,node3}
#echo "node1" >>/webroot/node1/index.html
#echo "node2" >>/webroot/node2/index.html
#echo "node3" >>/webroot/node3/index.html
#nginx -s reload
2.代理服务器配置
#vim /usr/local/nginx/conf
http {
include /usr/local/nginx/conf.d
}
#vim /usr/local/nginx/conf.d/www.test.com.conf
upstream node {
server 192.9.191.31:8001;
server 192.9.191.31:8002;
server 192.9.191.31:8003;
}
server {
listen 80;
server_name www.test.com;
location / {
proxy_pass http://node;
}
}
#nginx -t
#nginx -s reload
3.修改hosts文件以及测试
#vim /etc/hosts
192.9.191.30 www.test.com
# curl http://192.9.191.30
node2
# curl http://192.9.191.30
node3
# curl http://192.9.191.30
node1
(3)upstream参数
1.参数详解
server 1.1.1.1:80 \\负载均衡后面的RS配置,可以是IP或域名,端口不写,默认是80端口,高并发场景ip要换成域名,通过dns做负载均衡
weight \\权重,默认为1,权重大接受的请求越多
max_fails=2 \\最大尝试次数监测后端服务是否正常,默认根据端口检查,默认为1,0表示禁止失败尝试,
backup \\预留的备份服务器,当前面激活的real server都失败后会自动启用该服务器
fail_timeout=20s \\失败超时时间,默认是10s。根据业务需求去配置,常规业务2-3秒合理,失败之后,20秒之后在检测服务是否正常
down \\这标志着服务器永远不可用
max_conns=10 \\最大并发连接数,超过10个连接无法访问;保护节点
slow_start=10s \\后端服务器由down转为up,加入到集群的时间
server x.x.x.x:80 max_fails=2 fail_timeout=20s; \\ 每隔20秒钟检测后端服务是否正常2次,如果后端服务down机,自动切换到其它正常机器,如果后端机器由down改成up状态,又自动加入到web集群中
2.配置案例
#vim /usr/local/nginx/conf.d/www.test.com.conf
upstream node {
server 192.9.191.31:8001 down;
server 192.9.191.31:8002 backup;
server 192.9.191.31:8003 max_fail=1 fail_timeout=10s;
}
server {
listen 80;
server_name www.test.com;
location / {
proxy_pass http://node;
}
}
(4)upstream调度算法
1.调度算法详解
rr轮询 \\按时间顺序逐一分配到不同的后端服务器,默认调度算法
weight \\加权轮询,weight值越大,分配到访问几率越大
ip_hash \\同一个ip请求web服务器,第一次扔给一台服务器,下次同一个ip都会扔给同一台服务器,可以解决动态网页session共享问题,但是会破坏负载均衡,请求分配不均,最大的问题是NAT;建议不要使用ip_hash方式,使用redis方式进行会话共享;
fair \\第三方动态算法,按照后端服务器RS的响应时间来分配请求,响应时间短的优先分配
url_hash \\按访问url的hash结果来分配请求,让每个url定向到同一个后端服务器,url_hash和ip_hash类似,url_hash用于web缓存,ip_hash用于会话保持,例如www.baidu.com/1.html和www.baidu.com/index.html这两个url会分配不同的后端服务器,一定要记录url包含请求的资源例如index.html等
一直性hash \\淘宝tengine,
least_conn \\最少连接数
2.weight加权配置案例
upstream node {
server 192.9.191.31:8001;
server 192.9.191.31:8002 weight=5;
}
3.ip_hash配置案例
upstream node {
ip_hash;
server 192.9.191.31:8001;
server 192.9.191.31:8002;
}
4.url_hash配置案例,注意低版本的nginx不支持
upstream node {
hash $request_uri;
server 192.9.191.31:8001;
server 192.9.191.31:8002;
}

