(转载) Kubernetes入门教程
原文地址:kubernetes入门教程
简介
Kubernetes 是一个开源的容器编排引擎和容器集群管理工具,用来对容器化应用进行自动化部署、 扩缩和管理。
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。k8s 这个缩写是因为 k 和 s 之间有8个字符。 Google 在 2014 年开源了 Kubernetes 项目。
优势
Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。它之所以能够迅速流行起来,是因为它的许多功能高度契合互联网大厂的部署和运维需求。
能力
Kubernetes 可以提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来曝露容器。 如果进入容器的流量很大Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。也可以是方便的实现金丝雀部署(canary deployment )。
- 自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。 - 自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
kubernetes架构
一个Kubernetes集群至少包含一个控制平面(control plane),以及一个或多个工作节点(worker node)。
控制平面(Control Plane) : 控制平面负责管理工作节点和维护集群状态。所有任务分配都来自于控制平面。
工作节点(Worker Node) : 工作节点负责执行由控制平面分配的请求任务,运行实际的应用和工作负载。
控制平面
控制平面组件会为集群做出全局决策,比如资源的调度、检测和响应集群事件。
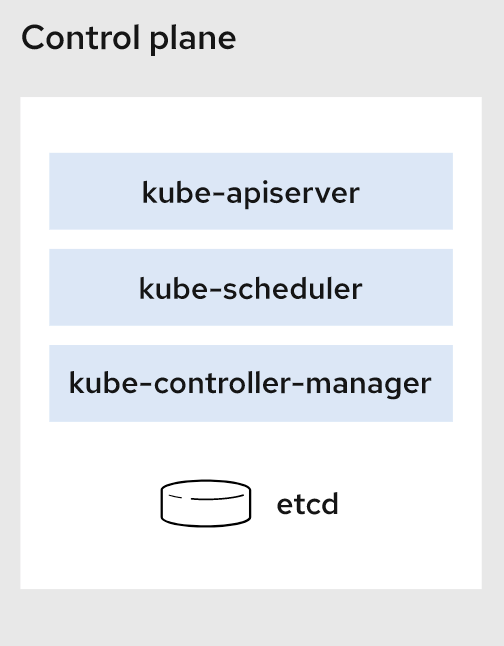
kube-apiserver
如果需要与Kubernetes 集群进行交互,就要通过 API。apiserver是 Kubernetes 控制平面的前端,用于处理内部和外部请求。
kube-scheduler
集群状况是否良好?如果需要创建新的容器,要将它们放在哪里?这些是调度程序需要关注的问题。
scheduler调度程序会考虑容器集的资源需求(例如 CPU 或内存)以及集群的运行状况。随后,它会将容器集安排到适当的计算节点。
etcd
etcd是一个键值对数据库,用于存储配置数据和集群状态信息。
kube-controller-manager
控制器负责实际运行集群,controller-manager控制器管理器则是将多个控制器功能合而为一,降低了程序的复杂性。
controller-manager包含了这些控制器:
- 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
- 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller):填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers):为新的命名空间创建默认帐户和 API 访问令牌
Node 组件
节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
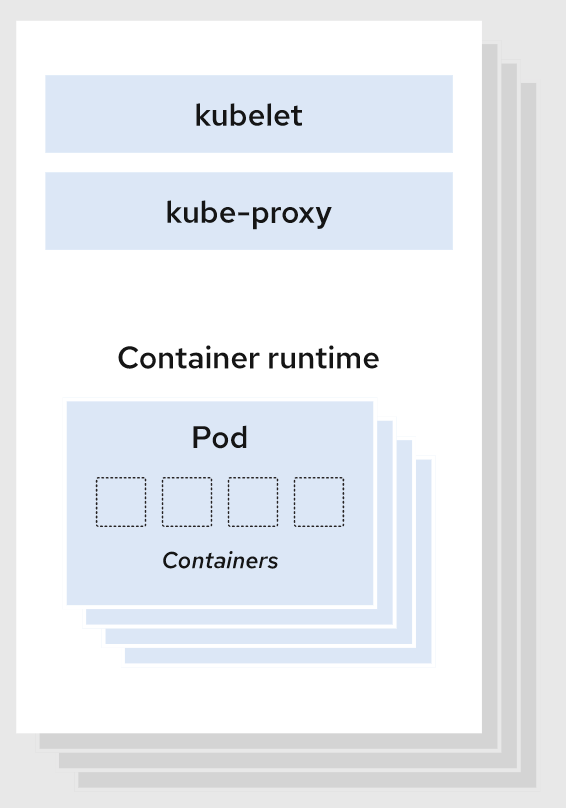
kubelet
kubelet 会在集群中每个节点(node)上运行。 它保证容器(containers)都运行在 Pod 中。
当控制平面需要在节点中执行某个操作时,kubelet 就会执行该操作。
kube-proxy
kube-proxy 是集群中每个节点(node)上运行的网络代理,是实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点网络规则和转发流量,实现从集群内部或外部的网络与 Pod 进行网络通信。
容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。
Kubernetes 支持许多容器运行环境,例如 containerd、docker或者其他实现了 Kubernetes CRI (容器运行环境接口)的容器。
组件关系
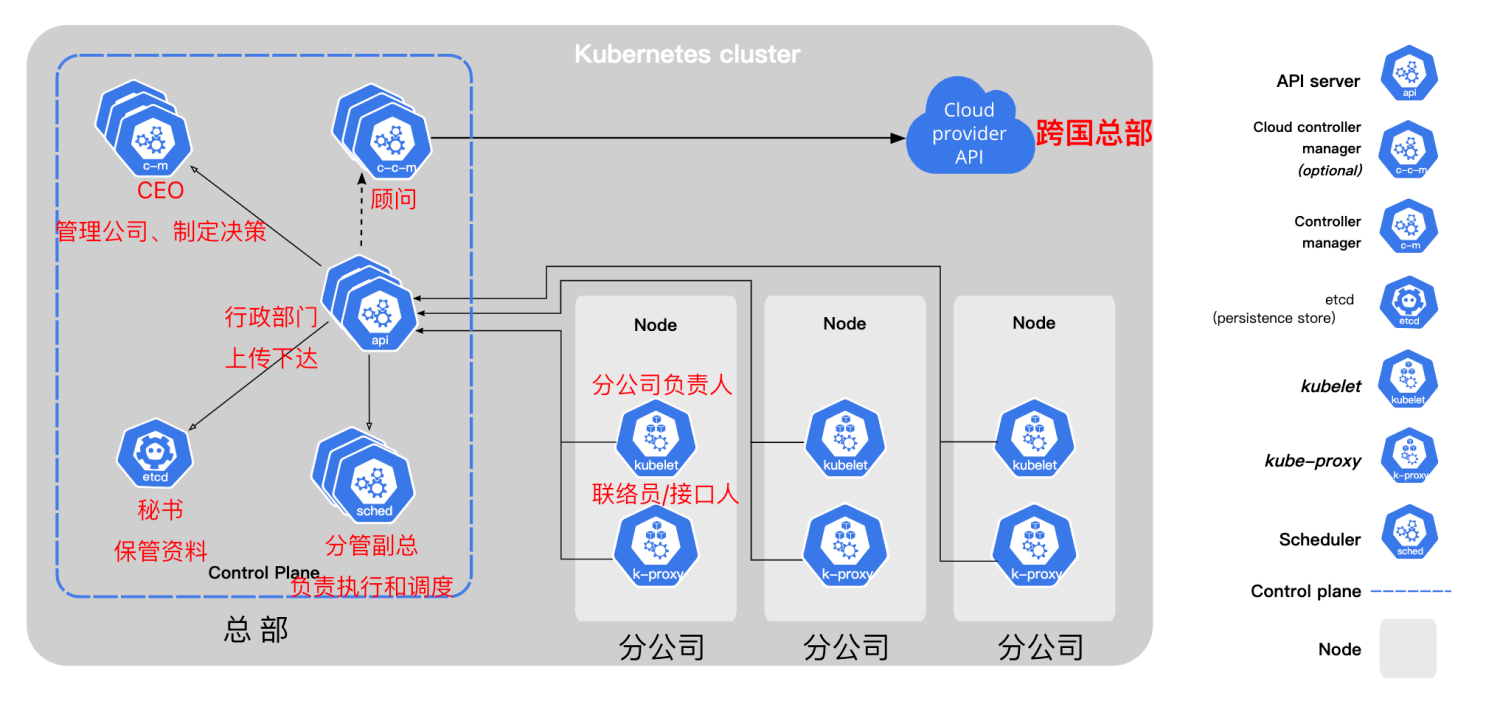
cloud-controller-manager
控制平面还包含一个可选组件cloud-controller-manager。
云控制器管理器(Cloud Controller Manager)允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
如果在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的集群不需要有云控制器管理器。
使用K3s快速搭建集群
为什么使用K3s
K3s 是一个轻量级的、完全兼容的 Kubernetes 发行版本。非常适合初学者。
K3s将所有 Kubernetes 控制平面组件都封装在单个二进制文件和进程中,文件大小<100M,占用资源更小,且包含了kubernetes运行所需要的部分外部依赖和本地存储提供程序。
K3s提供了离线安装包,安装起来非常方便,可以避免安装过程中遇到各种网络资源访问问题。
K3s特别适用于边缘计算、物联网、嵌入式和ARM移动端场景。
K3s完全兼容kubernetes,二者的操作是一样的,使用k3s完全满足我们学习kubernetes的要求,课程的最后,我们再使用kubeadm安装一个完整的集群。
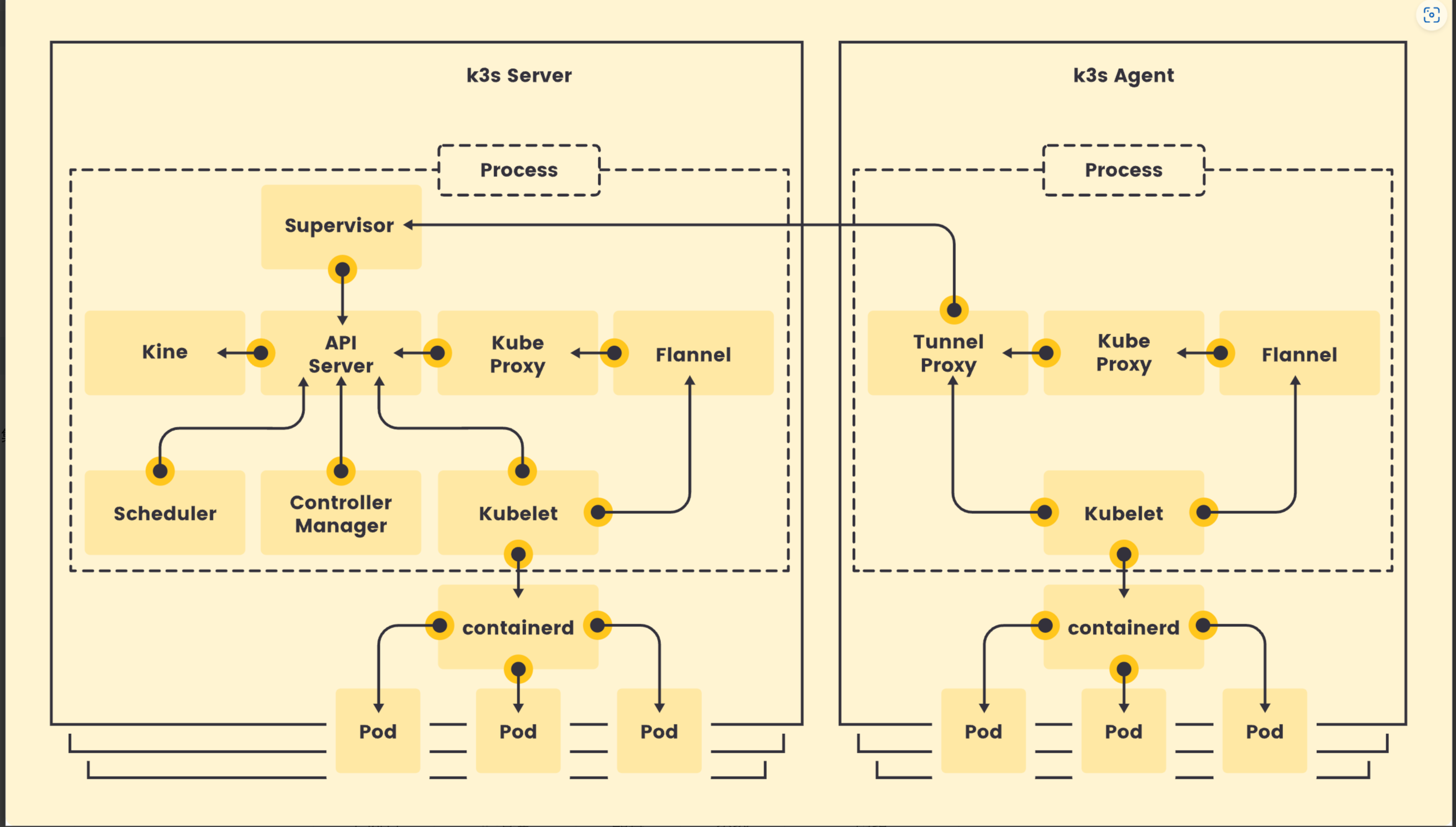
离线安装K3s集群
K3s集群分为k3s Server(控制平面)和k3s Agent(工作节点)。所有的组件都打包在单个二进制文件中。
运行环境
最低运行要求
- 内存: 512MB / CPU: 1 核心
- K3s版本:v1.25.0+k3s1
- 集群规划
1.准备工作
需要在每台机器上执行如下命令:
- 关闭防火墙
systemctl disable firewalld --now
systemctl disable nm-cloud-setup.service nm-cloud-setup.timer
- 设置selinux(需要联网)
yum install -y container-selinux selinux-policy-base
yum install -y https://rpm.rancher.io/k3s/latest/common/centos/7/noarch/k3s-selinux-0.2-1.el7_8.noarch.rpm
2.下载安装包
下载安装脚本 install.sh: https://get.k3s.io/
下载k3s二进制文件:k3s
下载必要的image:离线安装需要的image文件
这些文件都可以在github仓库中获取:https://github.com/k3s-io/k3s
3.执行安装脚本
1.将k3s二进制文件移动到/usr/local/bin目录,并添加执行权限
mv k3s /usr/local/bin
chmod +x /usr/local/bin/k3s
2.将镜像移动到/var/lib/rancher/k3s/agent/images/目录(无需解压)
mkdir -p /var/lib/rancher/k3s/agent/images/
cp ./k3s-airgap-images-amd64.tar.gz /var/lib/rancher/k3s/agent/images/
- 在k8s-master节点执行
#修改权限
chmod +x install.sh
#离线安装
INSTALL_K3S_SKIP_DOWNLOAD=true ./install.sh
#安装完成后,查看节点状态
kubectl get node
#查看token
cat /var/lib/rancher/k3s/server/node-token
#K10c4b79481685b50e4bca2513078f4e83b62d1d0b5f133a8a668b65c8f9249c53e::server:bf7b63be7f3471838cbafa12c1a1964d
- 在k8s-worker1和k8s-worker2节点执行
INSTALL_K3S_SKIP_DOWNLOAD=true \
# 地址为master节点的地址
K3S_URL=https://192.168.56.109:6443 \
# token为master节点的token
K3S_TOKEN=K1012bdc3ffe7a5d89ecb125e56c38f9fe84a9f9aed6db605f7698fa744f2f2f12f::server:fdf33f4921dd607cadf2ae3c8eaf6ad9 \
./install.sh
Pod(容器集)
Pod
Pod 是包含一个或多个容器的容器组,是 Kubernetes 中创建和管理的最小对象。
Pod 有以下特点:
- Pod是kubernetes中最小的调度单位(原子单元),Kubernetes直接管理Pod而不是容器。
- 同一个Pod中的容器总是会被自动安排到集群中的同一节点(物理机或虚拟机)上,并且一起调度。
- Pod可以理解为运行特定应用的“逻辑主机”,这些容器共享存储、网络和配置声明(如资源限制)。
- 每个 Pod 有唯一的 IP 地址。 IP地址分配给Pod,在同一个 Pod 内,所有容器共享一个 IP 地址和端口空间,Pod 内的容器可以使用localhost互相通信。
例如,你可能有一个容器,为共享卷中的文件提供 Web 服务器支持,以及一个单独的 "边车 (sidercar)" 容器负责从远端更新这些文件,如下图所示:
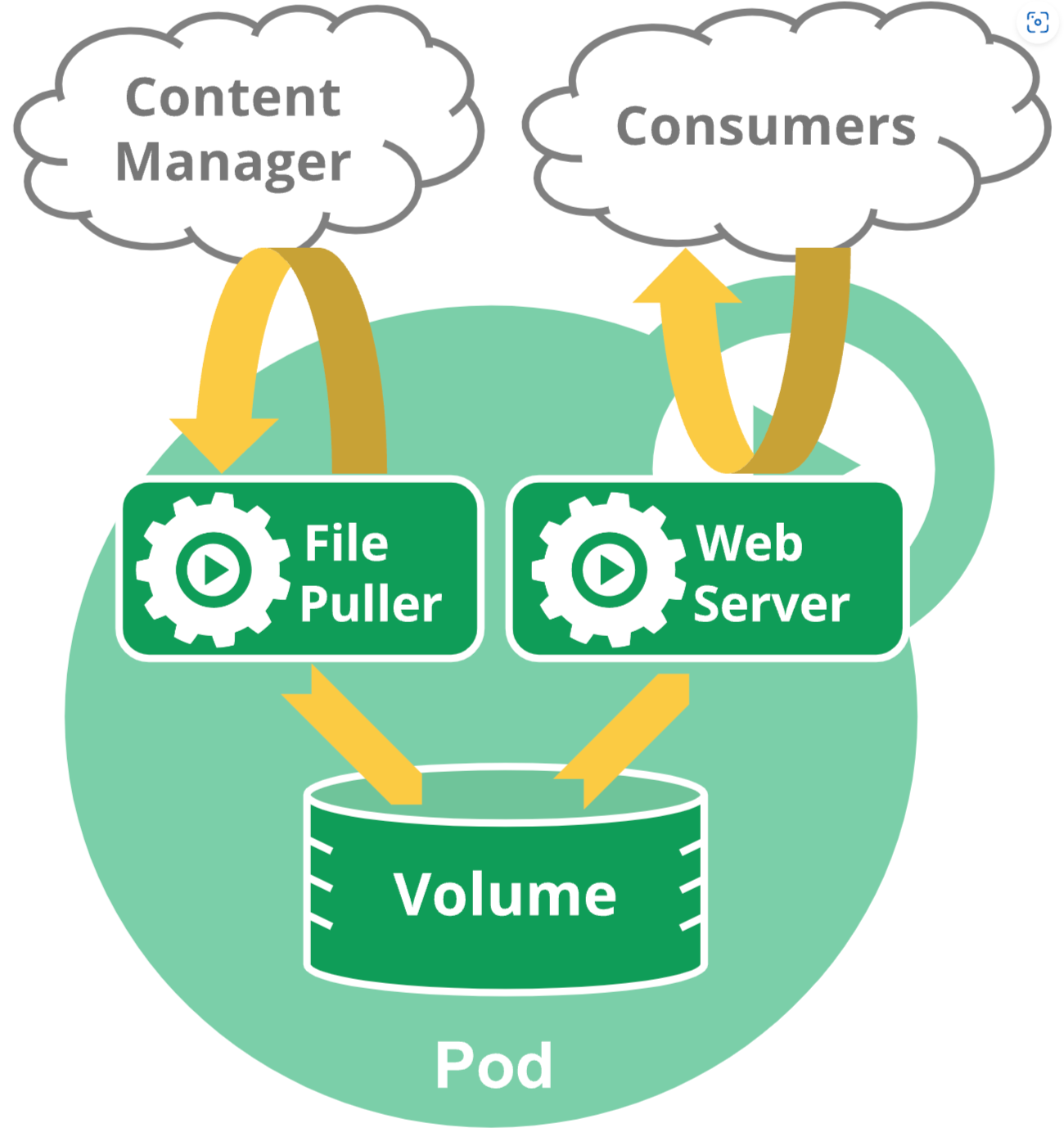
创建和管理Pod
kubectl run mynginx --image=nginx
# 查看Pod
kubectl get pod
# 描述
kubectl describe pod mynginx
# 查看Pod的运行日志
kubectl logs mynginx
# 显示pod的IP和运行节点信息
kubectl get pod -owide
# 使用Pod的ip+pod里面运行容器的端口
curl 10.42.1.3
#在容器中执行
kubectl exec mynginx -it -- /bin/bash
kubectl get po --watch
# -it 交互模式
# --rm 退出后删除容器,多用于执行一次性任务或使用客户端
kubectl run mynginx --image=nginx -it --rm -- /bin/bash
# 删除
kubectl delete pod mynginx
# 强制删除
kubectl delete pod mynginx --force

镜像加速
由于kubernetes从V1.24版本开始默认使用containerd,需要修改containerd的配置文件,才能让Pod的镜像使用镜像加速器。
配置文件路径一般为/etc/containerd/config.toml,详见阿里云镜像加速。
在K3s中配置镜像仓库
K3s 会自动生成containerd的配置文件/var/lib/rancher/k3s/agent/etc/containerd/config.toml,不要直接修改这个文件,k3s重启后修改会丢失。
为了简化配置,K3s 通过/etc/rancher/k3s/registries.yaml文件来配置镜像仓库,K3s会在启动时检查这个文件是否存在。
我们需要在每个节点上新建/etc/rancher/k3s/registries.yaml文件,配置内容如下:
mirrors:
docker.io:
endpoint:
- "https://fsp2sfpr.mirror.aliyuncs.com/"
重启每个节点
# master节点
systemctl restart k3s
# work节点
systemctl restart k3s-agent
查看配置是否生效。
cat /var/lib/rancher/k3s/agent/etc/containerd/config.toml
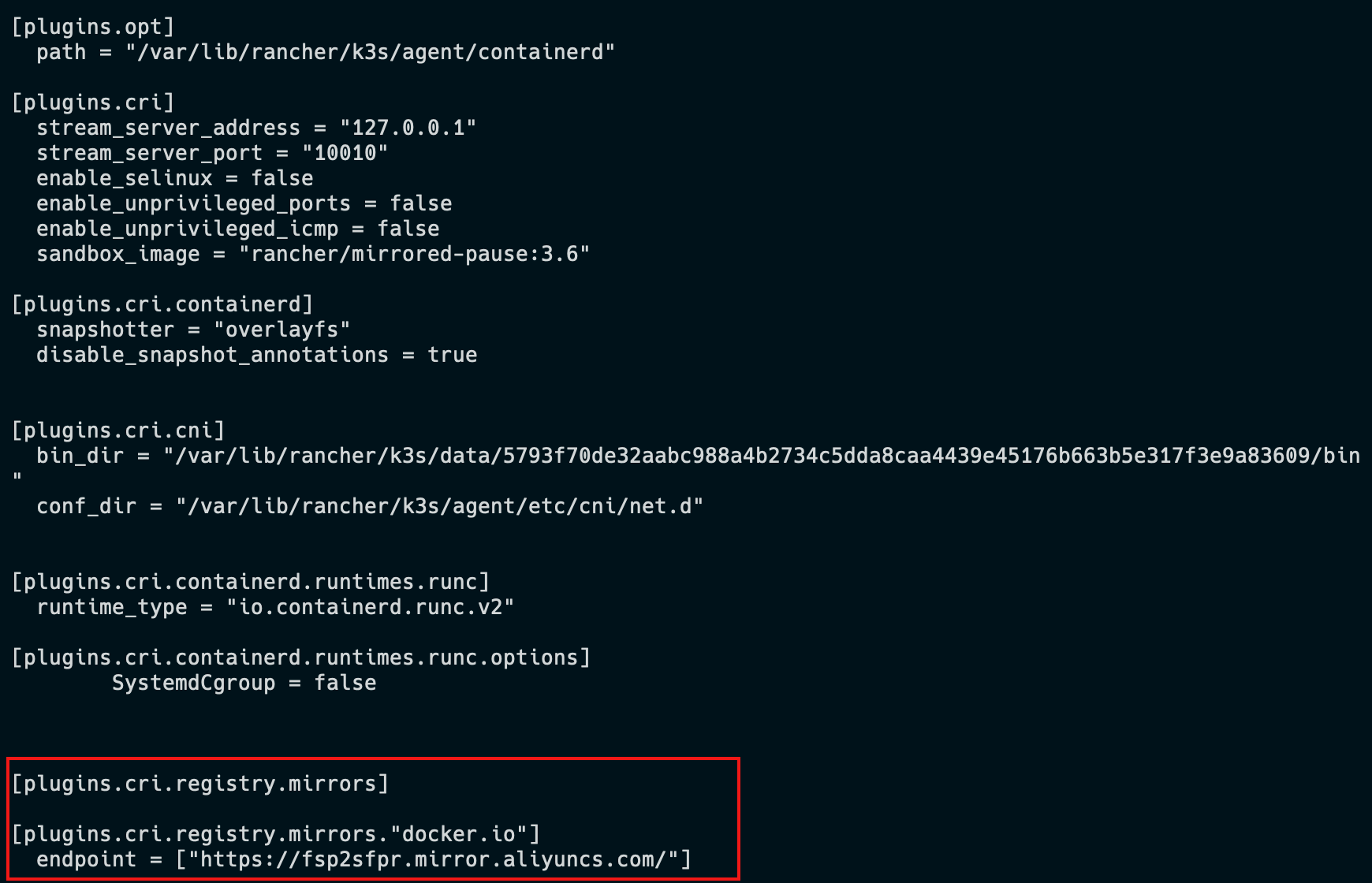
容器与镜像
容器运行时接口(CRI)
Kubelet运行在每个节点(Node)上,用于管理和维护Pod和容器的状态。
容器运行时接口(CRI)是kubelet 和容器运行时之间通信的主要协议。它将 Kubelet 与容器运行时解耦,理论上,实现了CRI接口的容器引擎,都可以作为kubernetes的容器运行时。
Docker没有实现(CRI)接口,Kubernetes使用dockershim来兼容docker。
自V1.24版本起,Dockershim 已从 Kubernetes 项目中移除。
crictl是一个兼容CRI的容器运行时命令,他的用法跟docker命令一样,可以用来检查和调试底层的运行时容器。
crictl pull mysql:5.7-debian
crictl images
在一些局域网环境下,我们没法通过互联网拉取镜像,可以手动的导出、导入镜像。
crictl命令没有导出、导入镜像的功能。
需要使用ctr命令导出、导入镜像,它是containerd的命令行接口。
- 从
docker导出镜像再导入到containerd中
docker pull alpine:3.16
docker save alpine:3.16 > alpine.tar
#kubernetes使用的镜像都在k8s.io命名空间中
ctr -n k8s.io images import alpine.tar
- 从
containerd导出、导入镜像
#导出镜像
ctr -n k8s.io images export mysql.tar docker.io/library/mysql:5.7-debian --platform linux/amd64
#导入镜像
ctr -n k8s.io images import mysql.tar
Deployment(部署)与ReplicaSet(副本集)
Deployment是对ReplicaSet和Pod更高级的抽象。
它使Pod拥有多副本,自愈,扩缩容、滚动升级等能力。
ReplicaSet(副本集)是一个Pod的集合。
它可以设置运行Pod的数量,确保任何时间都有指定数量的 Pod 副本在运行。
通常我们不直接使用ReplicaSet,而是在Deployment中声明。
#创建deployment,部署3个运行nginx的Pod
kubectl create deployment nginx-deployment --image=nginx:1.22 --replicas=3
#查看deployment
kubectl get deploy
#查看replicaSet
kubectl get rs
#删除deployment
kubectl delete deploy nginx-deployment
缩放
- 手动缩放
#将副本数量调整为5
kubectl scale deployment/nginx-deployment --replicas=5
kubectl get deploy
- 自动缩放
自动缩放通过增加和减少副本的数量,以保持所有 Pod 的平均 CPU 利用率不超过 75%。
自动伸缩需要声明Pod的资源限制,同时使用 Metrics Server 服务(K3s默认已安装)。
#自动缩放
kubectl autoscale deployment/nginx-auto --min=3 --max=10 --cpu-percent=75
#查看自动缩放
kubectl get hpa
#删除自动缩放
kubectl delete hpa nginx-deployment
滚动更新
#查看版本和Pod
kubectl get deployment/nginx-deployment -owide
kubectl get pods
#更新容器镜像
kubectl set image deployment/nginx-deployment nginx=nginx:1.23
#滚动更新
kubectl rollout status deployment/nginx-deployment
#查看过程
kubectl get rs --watch
版本回滚
#查看历史版本
kubectl rollout history deployment/nginx-deployment
#查看指定版本的信息
kubectl rollout history deployment/nginx-deployment --revision=2
#回滚到历史版本
kubectl rollout undo deployment/nginx-deployment --to-revision=2
Service(服务)
Service将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。
Service为一组 Pod 提供相同的 DNS 名,并且在它们之间进行负载均衡。
Kubernetes 为 Pod 提供分配了IP 地址,但IP地址可能会发生变化。
集群内的容器可以通过service名称访问服务,而不需要担心Pod的IP发生变化。
Kubernetes Service 定义了这样一种抽象:
逻辑上的一组可以互相替换的 Pod,通常称为微服务。
Service 对应的 Pod 集合通常是通过选择算符来确定的。
举个例子,在一个Service中运行了3个nginx的副本。这些副本是可互换的,我们不需要关心它们调用了哪个nginx,也不需要关注 Pod的运行状态,只需要调用这个服务就可以了。
创建Service对象
ServiceType 取值
- ClusterIP:将服务公开在集群内部。kubernetes会给服务分配一个集群内部的 IP,集群内的所有主机都可以通过这个Cluster-IP访问服务。集群内部的Pod可以通过service名称访问服务。
- NodePort:通过每个节点的主机IP 和静态端口(NodePort)暴露服务。 集群的外部主机可以使用节点IP和NodePort访问服务。
- ExternalName:将集群外部的网络引入集群内部。
- LoadBalancer:使用云提供商的负载均衡器向外部暴露服务。
# port是service访问端口,target-port是Pod端口
# 二者通常是一样的
kubectl expose deployment/nginx-deployment \
--name=nginx-service --type=ClusterIP --port=80 --target-port=80
# 随机产生主机端口
kubectl expose deployment/nginx-deployment \
--name=nginx-service2 --type=NodePort --port=8080 --target-port=80

访问Service
外部主机访问:192.168.56.109:32296。
1.NodePort端口是随机的,范围为:30000-32767。
2.集群中每一个主机节点的NodePort端口都可以访问。
3.如果需要指定端口,不想随机产生,需要使用配置文件来声明。
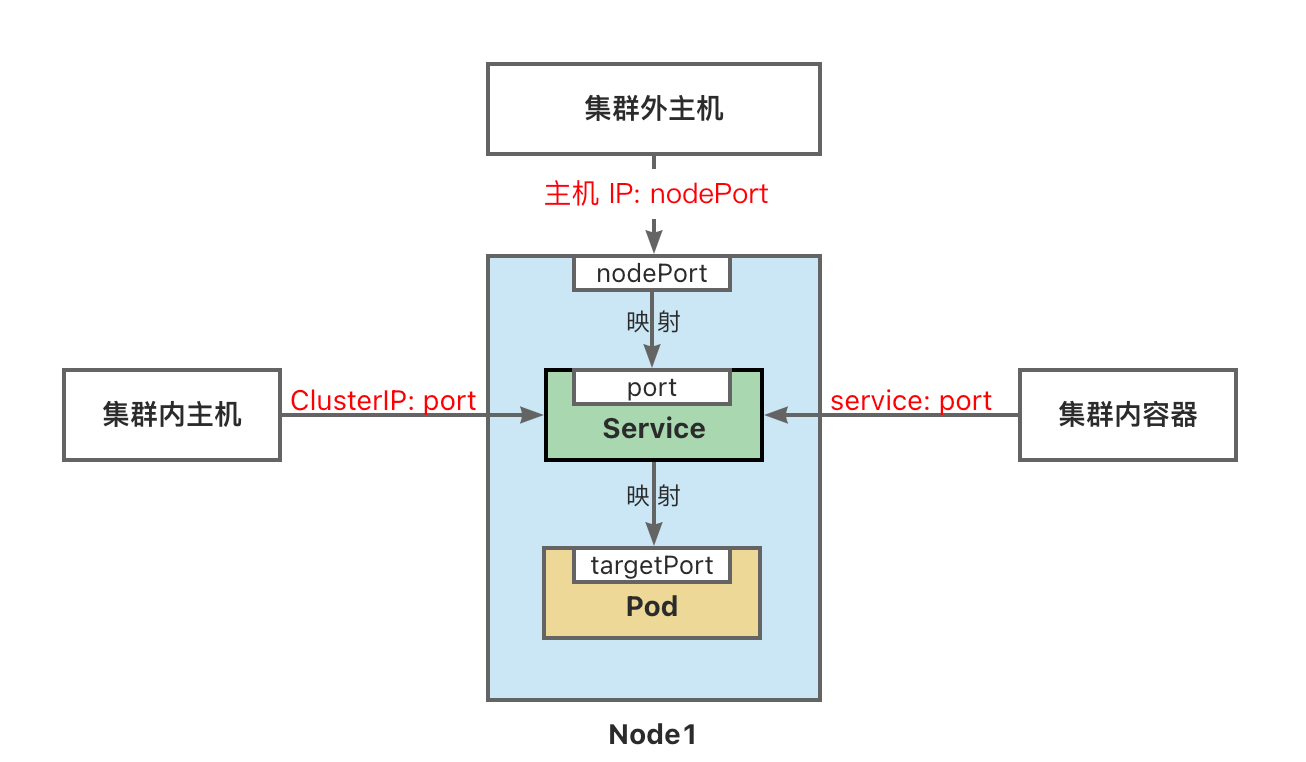
#集群内访问
curl 10.43.65.187:80
#容器内访问
kubectl run nginx-test --image=nginx:1.22 -it --rm -- sh
#
curl nginx-service:80
Namespace(命名空间)
命名空间(Namespace)是一种资源隔离机制,将同一集群中的资源划分为相互隔离的组。
命名空间可以在多个用户之间划分集群资源(通过资源配额)。
例如我们可以设置开发、测试、生产等多个命名空间。
同一命名空间内的资源名称要唯一,但跨命名空间时没有这个要求。
命名空间作用域仅针对带有名字空间的对象,例如 Deployment、Service 等。
这种作用域对集群访问的对象不适用,例如 StorageClass、Node、PersistentVolume 等。
Kubernetes 会创建四个初始命名空间:
- default 默认的命名空间,不可删除,未指定命名空间的对象都会被分配到default中。
- kube-system Kubernetes 系统对象(控制平面和Node组件)所使用的命名空间。
- kube-public 自动创建的公共命名空间,所有用户(包括未经过身份验证的用户)都可以读取它。通常我们约定,将整个集群中公用的可见和可读的资源放在这个空间中。
- kube-node-lease 租约(Lease)对象使用的命名空间。每个节点都有一个关联的 lease 对象,lease 是一种轻量级资源。lease对象通过发送心跳,检测集群中的每个节点是否发生故障。
使用kubectl get lease -A查看lease对象
使用多个命名空间
- 命名空间是在多个用户之间划分集群资源的一种方法(通过资源配额)。例如我们可以设置开发、测试、生产等多个命名空间。
- 不必使用多个命名空间来分隔轻微不同的资源。例如同一软件的不同版本: 应该使用标签 来区分同一命名空间中的不同资源。
- 命名空间适用于跨多个团队或项目的场景。对于只有几到几十个用户的集群,可以不用创建命名空间。
- 命名空间不能相互嵌套,每个 Kubernetes 资源只能在一个命名空间中。
管理命名空间
#创建命名空间
kubectl create namespace dev
#查看命名空间
kubectl get ns
#在命名空间内运行Pod
kubectl run nginx --image=nginx --namespace=dev
kubectl run my-nginx --image=nginx -n=dev
#查看命名空间内的Pod
kubectl get pods --n=dev
#查看命名空间内所有对象
kubectl get all
# 删除命名空间会删除命名空间下的所有内容
kubectl delete ns dev
切换当前命名空间
#查看当前上下文
kubectl config current-context
#将dev设为当前命名空间,后续所有操作都在此命名空间下执行。
kubectl config set-context $(kubectl config current-context) --namespace=dev
声明式对象配置
管理对象
- 命令行指令: 例如,使用kubectl命令来创建和管理 Kubernetes 对象。命令行就好比口头传达,简单、快速、高效。但它功能有限,不适合复杂场景,操作不容易追溯,多用于开发和调试。
- 声明式配置: kubernetes使用yaml文件来描述 Kubernetes 对象。声明式配置就好比申请表,学习难度大且配置麻烦。好处是操作留痕,适合操作复杂的对象,多用于生产。
常用命令缩写
| 名称 | 缩写 | Kind |
|---|---|---|
| namespaces | ns | Namespace |
| nodes | no | Node |
| pods | po | Pod |
| services | svc | Service |
| deployments | deploy | Deployment |
| replicasets | rs | ReplicaSet |
| statefulsets | sts | StatefulSet |
kubectl create deploy my-deploy --image=nginx:1.22 --replicas=3
kubectl get po
配置对象
在创建的 Kubernetes 对象所对应的 yaml文件中,需要配置的字段如下:
- apiVersion - Kubernetes API 的版本
- kind - 对象类别,例如Pod、Deployment、Service、ReplicaSet等
- metadata - 描述对象的元数据,包括一个 name 字符串、UID 和可选的 namespace
- spec - 对象的配置
Pod配置模版
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
使用yaml文件管理对象
#创建对象
kubectl apply -f my-pod.yaml
#编辑对象
kubectl edit nginx
#删除对象
kubectl delete -f my-pod.yaml
标签
标签(Labels) 是附加到对象(比如 Pod)上的键值对,用于补充对象的描述信息。
标签使用户能够以松散的方式管理对象映射,而无需客户端存储这些映射。
由于一个集群中可能管理成千上万个容器,我们可以使用标签高效的进行选择和操作容器。
- 键的格式:
- 前缀(可选)/名称(必须)。
- 有效名称和值:
- 必须为 63 个字符或更少(可以为空)
- 如果不为空,必须以字母数字字符([a-z0-9A-Z])开头和结尾
- 包含破折号-、下划线_、点.和字母或数字
label配置模版
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels: #定义Pod标签
environment: test
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
kubectl get pod --show-labels
kubectl get pod -l environment=test,app=nginx
选择器
标签选择器 可以识别一组对象。标签不支持唯一性。
标签选择器最常见的用法是为Service选择一组Pod作为后端。
Service配置模版
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector: #与Pod的标签一致
environment: test
app: nginx
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 80
targetPort: 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort: 30007
目前支持两种类型的选择运算:基于等值的和基于集合的。
多个选择条件使用逗号分隔,相当于And(&&)运算。
- 等值选择
selector:
matchLabels: # component=redis && version=7.0
component: redis
version: 7.0
- 集合选择
selector:
matchExpressions: # tier in (cache, backend) && environment not in (dev, prod)
- {key: tier, operator: In, values: [cache, backend]}
- {key: environment, operator: NotIn, values: [dev, prod]}
金丝雀发布
金丝雀部署(canary deployment)也被称为灰度发布。早期,工人下矿井之前会放入一只金丝雀检测井下是否存在有毒气体。采用金丝雀部署,你可以在生产环境的基础设施中小范围的部署新的应用代码。一旦应用签署发布,只有少数用户被路由到它,最大限度的降低影响。如果没有错误发生,则将新版本逐渐推广到整个基础设施。

部署过程
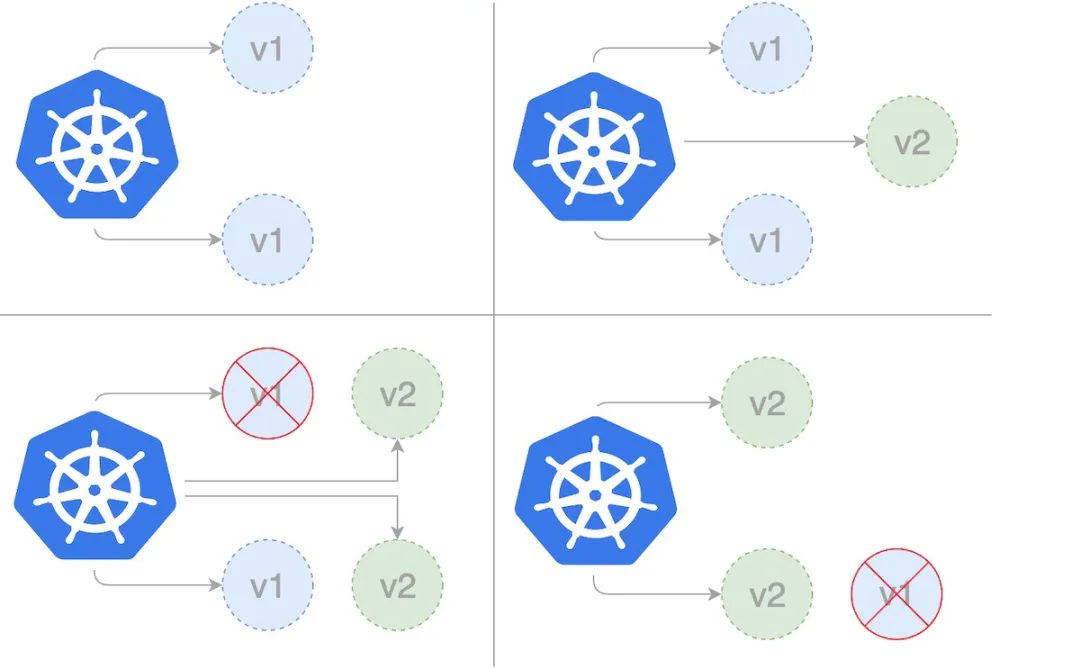
部署第一个版本
发布v1版本的应用,镜像使用nginx:1.22,数量为 3。
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-v1
namespace: dev
labels:
app: nginx-deployment-v1
spec:
replicas: 3
selector:
matchLabels: # 跟template.metadata.labels一致
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: canary-demo
namespace: dev
spec:
type: NodePort
selector: # 更Deployment中的selector一致
app: nginx
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 30008
创建Canary Deployment
发布新版本的应用,镜像使用docker/getting-started,数量为 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-canary
namespace: dev
labels:
app: nginx-deployment-canary
spec:
replicas: 1
selector:
matchLabels: # 跟template.metadata.labels一致
app: nginx
template:
metadata:
labels:
app: nginx
track: canary
spec:
containers:
- name: new-nginx
image: docker/getting-started
ports:
- containerPort: 80
分配流量
查看服务kubectl describe svc canary-demo --namespace=dev
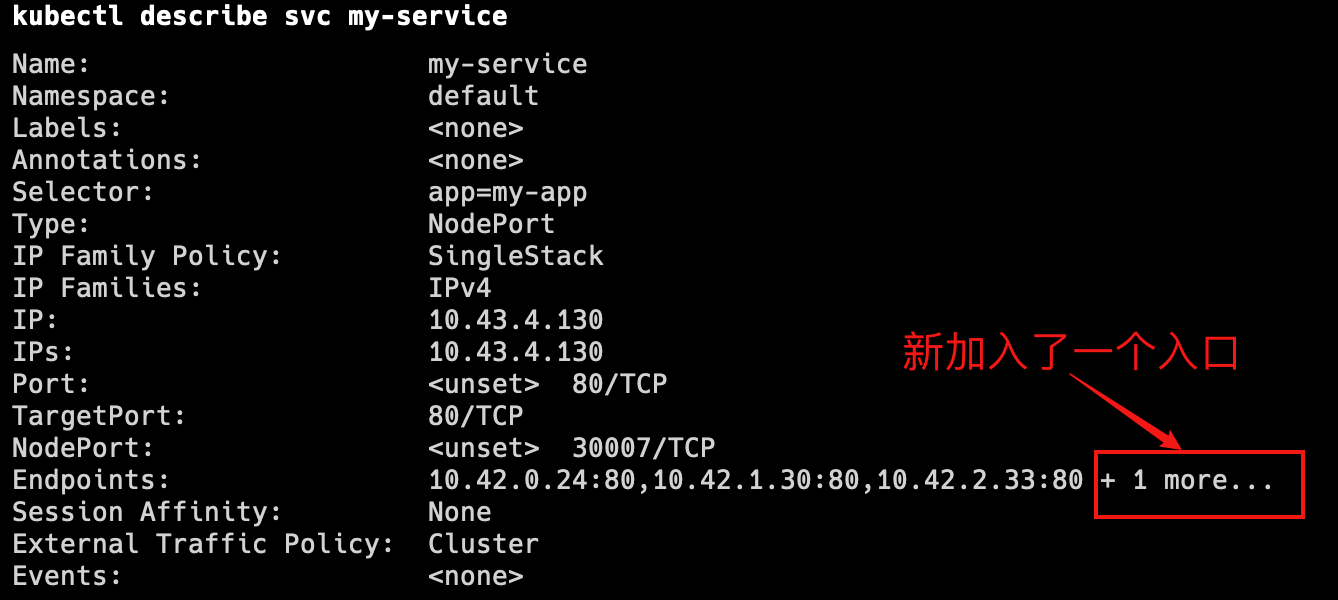
- 调整比例
待稳定运行一段时间后,扩大试用范围,将部署的v2版本数量调整为3,v1和v2的数量都是3个
kubectl scale deployment/deploy-v2-canary --replicas=3 -n=dev
- 下线旧版本
最后下线所有v1版本,所有服务升级为v2版本。
kubectl scale deployment/deploy-v1 --replicas=0 -n=dev
清空环境
使用namespace可以方便的清空环境:
kubectl delete all --all -n=dev
局限性
按照 Kubernetes 默认支持的这种方式进行金丝雀发布,有一定的局限性:
- 不能根据用户注册时间、地区等请求中的内容属性进行流量分配
- 同一个用户如果多次调用该 Service,有可能第一次请求到了旧版本的 Pod,第二次请求到了新版本的 Pod
在 Kubernetes 中不能解决上述局限性的原因是:Kubernetes Service 只在 TCP 层面解决负载均衡的问题,并不对请求响应的消息内容做任何解析和识别。如果想要更完善地实现金丝雀发布,可以考虑Istio灰度发布。
运行有状态应用
我们以MySQL数据库为例,在kubernetes集群中运行一个有状态的应用。
部署数据库几乎覆盖了kubernetes中常见的对象和概念:
- 配置文件--ConfigMap
- 保存密码--Secret
- 数据存储--持久卷(PV)和持久卷声明(PVC)
- 动态创建卷--存储类(StorageClass)
- 部署多个实例--StatefulSet
- 数据库访问--Headless Service
- 主从复制--初始化容器和sidecar
- 数据库调试--port-forward
- 部署Mysql集群--helm
创建MySQL数据库
-
配置环境变量
-
使用MySQL镜像创建Pod,需要使用环境变量设置MySQL的初始密码。
-
环境变量配置示例
-
apiVersion: v1
kind: Pod
metadata:
name: envar-demo
labels:
purpose: demonstrate-envars
spec:
containers:
- name: envar-demo-container
image: gcr.io/google-samples/node-hello:1.0
env:
- name: DEMO_GREETING
value: "Hello from the environment"
- name: DEMO_FAREWELL
value: "Such a sweet sorrow"
-
挂载卷
- 将数据存储在容器中,一旦容器被删除,数据也会被删除。
- 将数据存储到卷(Volume)中,删除容器时,卷不会被删除。
-
hostPath卷
- hostPath 卷将主机节点上的文件或目录挂载到 Pod 中。
- hostPath配置示例
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
hostPath的type值:
| DirectoryOrCreate | 目录不存在则自动创建。 |
|---|---|
| Directory | 挂载已存在目录。不存在会报错。 |
| FileOrCreate | 文件不存在则自动创建。不会自动创建文件的父目录,必须确保文件路径已经存在。 |
| File | 挂载已存在的文件。不存在会报错。 |
| Socket | 挂载 UNIX 套接字。例如挂载/var/run/docker.sock进程 |
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: data-volume
volumes:
- name: data-volume
hostPath:
# 宿主机上目录位置
path: /home/mysql/data
type: DirectoryOrCreate
注意:hostPath 仅用于在单节点集群上进行开发和测试,不适用于多节点集群;
例如,当Pod被重新创建时,可能会被调度到与原先不同的节点上,导致新的Pod没有数据。
在多节点集群使用本地存储,可以使用local卷。
ConfigMap与Secret
在Docker中,我们一般通过绑定挂载的方式将配置文件挂载到容器里。
在Kubernetes集群中,容器可能被调度到任意节点,配置文件需要能在集群任意节点上访问、分发和更新。
ConfigMap
- ConfigMap 用来在键值对数据库(etcd)中保存非加密数据。一般用来保存配置文件。
- ConfigMap 可以用作环境变量、命令行参数或者存储卷。
- ConfigMap 将环境配置信息与 容器镜像 解耦,便于配置的修改。
- ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。超出此限制,需要考虑挂载存储卷或者访问文件存储服务。
ConfigMap用法
- ConfigMap配置示例
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
- Pod中使用ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
readOnly: true
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
# 修改configMap,配置文件会被自动更新
kubectl edit cm mysql-config
Secret
- Secret 用于保存机密数据的对象。一般由于保存密码、令牌或密钥等。
data字段用来存储 base64 编码数据。stringData存储未编码的字符串。- Secret 意味着你不需要在应用程序代码中包含机密数据,减少机密数据(如密码)泄露的风险。
- Secret 可以用作环境变量、命令行参数或者存储卷文件。
Secret用法
- Secret配置示例
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
USER_NAME: YWRtaW4=
PASSWORD: MWYyZDFlMmU2N2Rm
- 将Secret用作环境变量
apiVersion: v1
kind: Secret
metadata:
name: mysql-password
type: Opaque
data:
PASSWORD: MTIzNDU2Cg==
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-password
key: PASSWORD
optional: false # 此值为默认值;表示secret已经存在了
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
readOnly: true
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
卷(Volume)
将数据存储在容器中,一旦容器被删除,数据也会被删除。卷是独立于容器之外的一块存储区域,通过挂载(Mount)的方式供Pod中的容器使用。
- 使用场景
- 卷可以在多个容器之间共享数据。
- 卷可以将容器数据存储在外部存储或云存储上。
- 卷更容易备份或迁移。
常见的卷类型
-
临时卷(Ephemeral Volume):与 Pod 一起创建和删除,生命周期与 Pod 相同
- emptyDir - 作为缓存或存储日志
- configMap 、secret、 downwardAPI - 给Pod注入数据
-
持久卷(Persistent Volume):删除Pod后,持久卷不会被删除
- 本地存储 - hostPath、 local
- 网络存储 - NFS
- 分布式存储 - Ceph(cephfs文件存储、rbd块存储)
-
投射卷(Projected Volumes):projected 卷可以将多个卷映射到同一个目录上
后端存储
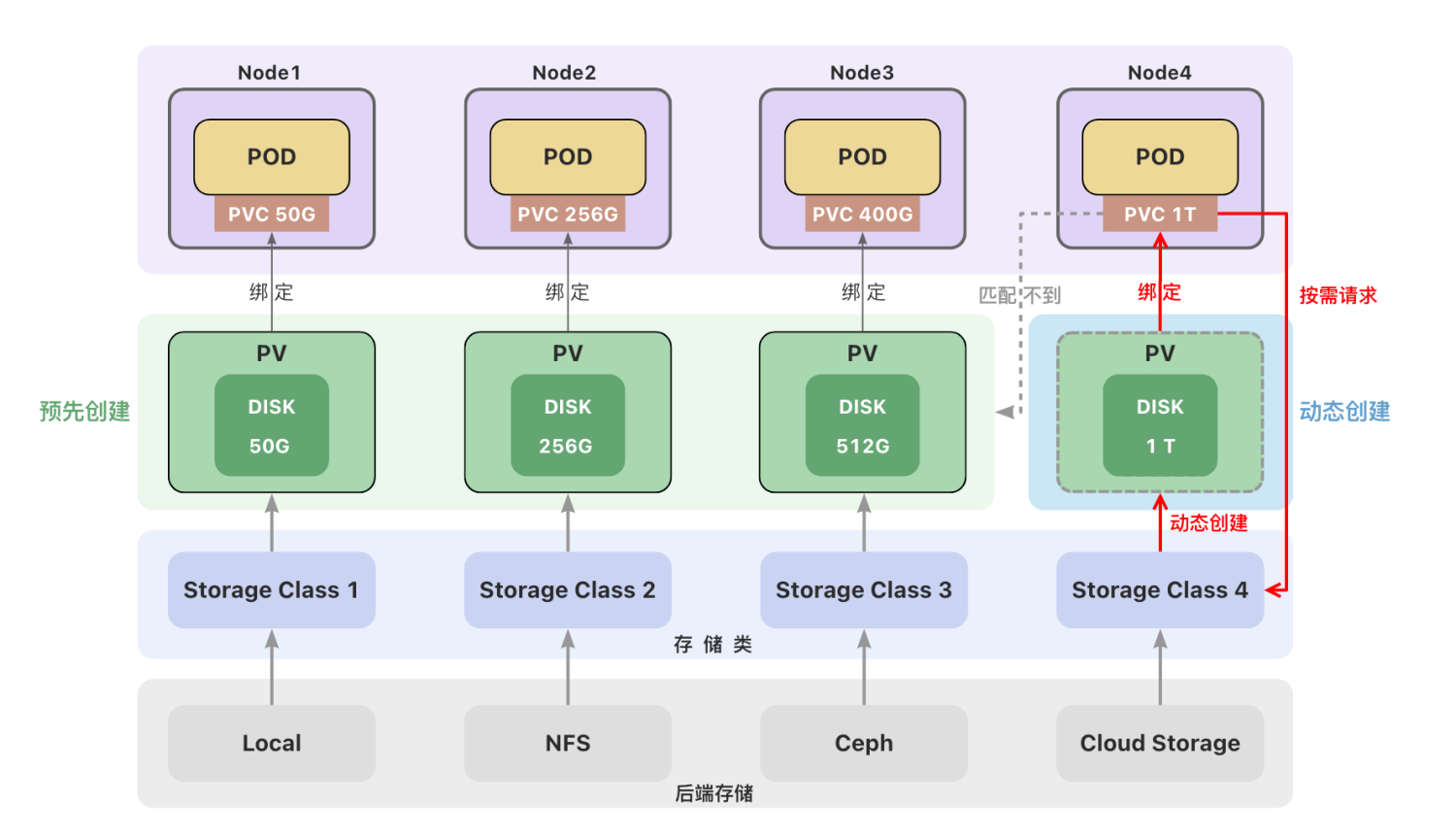
一个集群中可以包含多种存储(如local、NFS、Ceph或云存储)。
每种存储都对应一个存储类(StorageClass) ,存储类用来创建和管理持久卷,是集群与存储服务之间的桥梁。
管理员创建持久卷(PV)时,通过设置不同的StorageClass来创建不同类型的持久卷。
临时卷(EV)
- 临时卷(Ephemeral Volume)
- 与 Pod 一起创建和删除,生命周期与 Pod 相同
- emptyDir - 初始内容为空的本地临时目录
- configMap - 为Pod注入配置文件
- secret - 为Pod注入加密数据
emptyDir
emptyDir会创建一个初始状态为空的目录,存储空间来自本地的 kubelet 根目录或内存(需要将emptyDir.medium设置为Memory)。
通常使用本地临时存储来设置缓存、保存日志等。例如,将redis的存储目录设置为emptyDir
apiVersion: v1
kind: Pod
metadata:
name: redis-pod
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
configMap卷和secret卷
注意:这里的configMap和secret代表的是卷的类型,不是configMap和secret对象。
删除Pod并不会删除ConfigMap对象和secret对象。
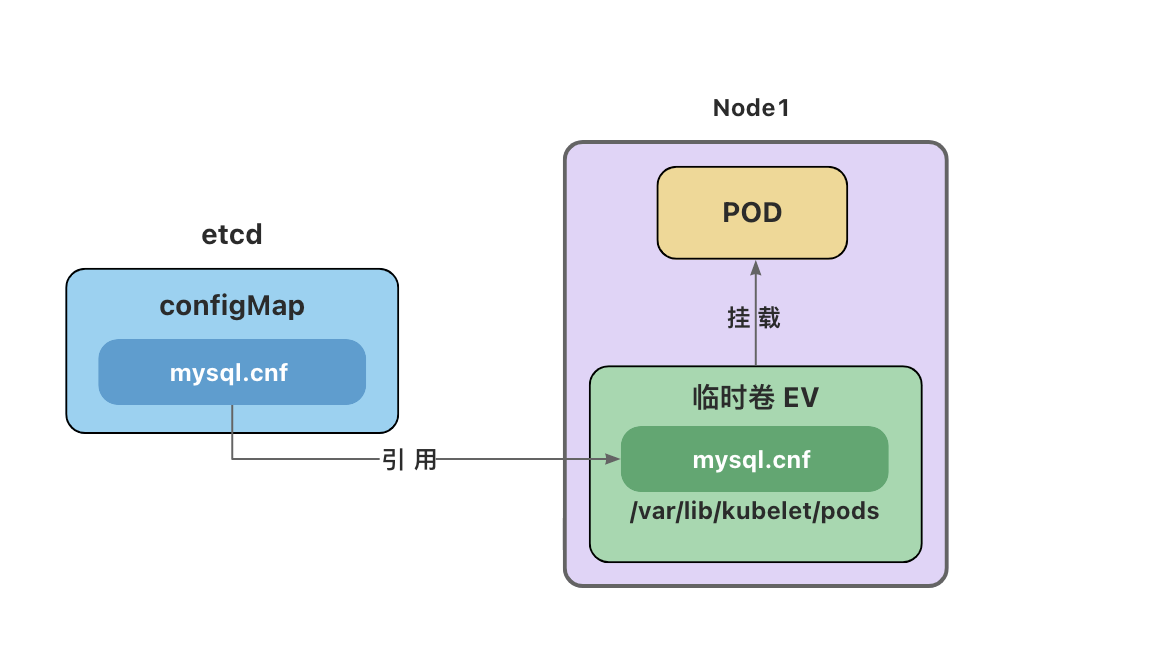
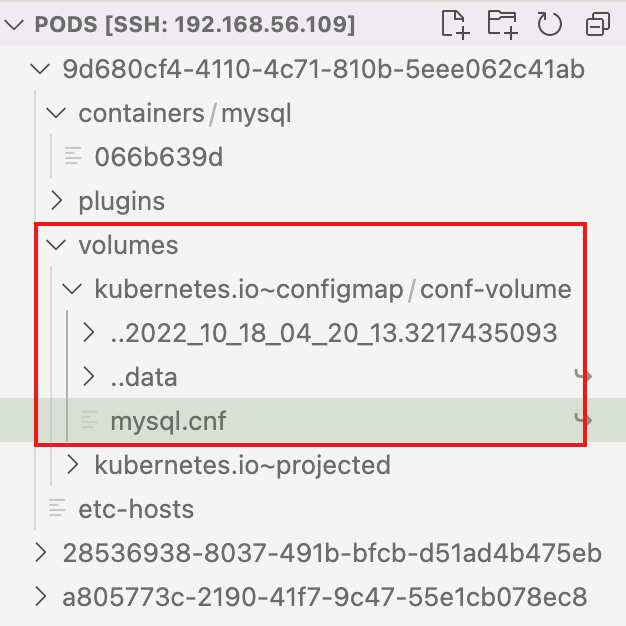
configMap卷和Secret卷是一种特殊类型的卷,kubelet引用configMap和Secret中定义的内容,在Pod所在节点上生成一个临时卷,将数据注入到Pod中。删除Pod,临时卷也会被删除。
临时卷位于Pod所在节点的/var/lib/kubelet/pods目录下。
持久卷(PV)与持久卷声明(PVC)
- 持久卷(Persistent Volume):删除Pod后,卷不会被删除
- 本地存储
- hostPath - 节点主机上的目录或文件(仅供单节点测试使用;多节点集群请用 local 卷代替)
- local - 节点上挂载的本地存储设备(不支持动态创建卷)
- 网络存储
- NFS - 网络文件系统 (NFS)
- 分布式存储
- Ceph(cephfs文件存储、rbd块存储)
- 本地存储
持久卷(PV)和持久卷声明(PVC)
持久卷(PersistentVolume,PV) 是集群中的一块存储。可以理解为一块虚拟硬盘。
持久卷可以由管理员事先创建, 或者使用存储类(Storage Class)根据用户请求来动态创建。
持久卷属于集群的公共资源,并不属于某个namespace;
持久卷声明(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。
PVC声明好比申请单,它更贴近云服务的使用场景,使用资源先申请,便于统计和计费。
Pod 将 PVC 声明当做存储卷来使用,PVC 可以请求指定容量的存储空间和访问模式 。PVC对象是带有namespace的。
创建持久卷(PV)
创建持久卷(PV)是服务端的行为,通常集群管理员会提前创建一些常用规格的持久卷以备使用。hostPath仅供单节点测试使用,当Pod被重新创建时,可能会被调度到与原先不同的节点上,导致新的Pod没有数据。多节点集群使用本地存储,可以使用local卷
创建local类型的持久卷,需要先创建存储类(StorageClass)。
本地存储类示例
# 创建本地存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: Immediate
local卷不支持动态创建,必须手动创建持久卷(PV)。
创建local类型的持久卷,必须设置nodeAffinity(节点亲和性)。
调度器使用nodeAffinity信息来将使用local卷的 Pod 调度到持久卷所在的节点上,不会出现Pod被调度到别的节点上的情况。
注意:
local卷也存在自身的问题,当Pod所在节点上的存储出现故障或者整个节点不可用时,Pod和卷都会失效,仍然会丢失数据,因此最安全的做法还是将数据存储到集群之外的存储或云存储上。
- 创建PV
PV示例/local卷示例
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-1
spec:
capacity:
storage: 4Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage #通过指定存储类来设置卷的类型
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-worker1
创建持久卷声明(PVC)
持久卷声明(PVC)是用户端的行为,用户在创建Pod时,无法知道集群中PV的状态(名称、容量、是否可用等),用户也无需关心这些内容,只需要在声明中提出申请,集群会自动匹配符合需求的持久卷(PV)。
Pod使用持久卷声明(PVC)作为存储卷。
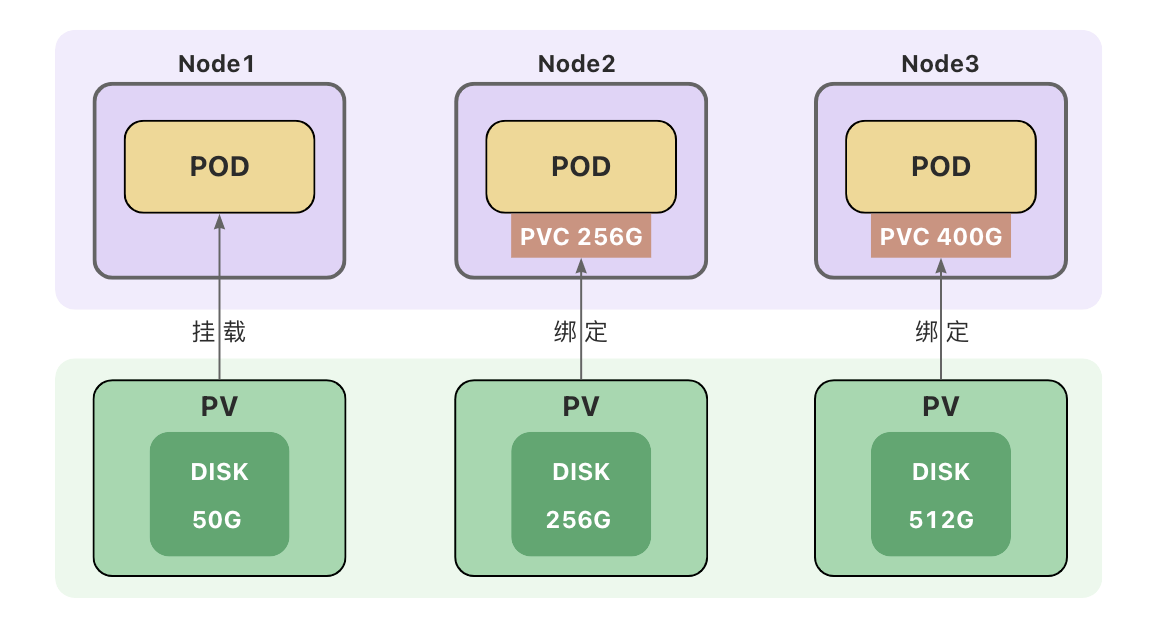
PVC示例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-pv-claim
spec:
storageClassName: local-storage # 与PV中的storageClassName一致
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
使用PVC作为卷
Pod 的配置文件指定了 PersistentVolumeClaim,但没有指定 PersistentVolume。
对 Pod 而言,PersistentVolumeClaim 就是一个存储卷。
PVC卷示例
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-pv-claim
绑定
创建持久卷声明(PVC)之后,集群会查找满足要求的持久卷(PV),将 PVC 绑定到该 PV上。
PVC与PV之间的绑定是一对一的映射关系,绑定具有排他性,一旦绑定关系建立,该PV无法被其他PVC使用。
PVC可能会匹配到比声明容量大的持久卷,但是不会匹配比声明容量小的持久卷。
例如,即使集群上存在多个 50 G大小的 PV ,他们加起来的容量大于100G,也无法匹配100 G大小的 PVC。
找不到满足要求的 PV ,PVC会无限期地处于未绑定状态(Pending) , 直到出现了满足要求的 PV时,PVC才会被绑定。
访问模式
- ReadWriteOnce
- 卷可以被一个节点以读写方式挂载,并允许同一节点上的多个 Pod 访问。
- ReadOnlyMany
- 卷可以被多个节点以只读方式挂载。
- ReadWriteMany
- 卷可以被多个节点以读写方式挂载。
- ReadWriteOncePod
- 卷可以被单个 Pod 以读写方式挂载。 集群中只有一个 Pod 可以读取或写入该 PVC。
- 只支持 CSI 卷以及需要 Kubernetes 1.22 以上版本。
卷的状态
- Available(可用)-- 卷是一个空闲资源,尚未绑定到任何;
- Bound(已绑定)-- 该卷已经绑定到某个持久卷声明上;
- Released(已释放)-- 所绑定的声明已被删除,但是资源尚未被集群回收;
- Failed(失败)-- 卷的自动回收操作失败。
卷模式
卷模式(volumeMode)是一个可选参数。
针对 PV 持久卷,Kubernetes 支持两种卷模式(volumeModes):
- Filesystem(文件系统)默认的卷模式。
- Block(块)将卷作为原始块设备来使用。
存储类(StorageClass)
创建持久卷(PV)
-
静态创建
- 管理员预先手动创建
- 手动创建麻烦、不够灵活(local卷不支持动态创建,必须手动创建PV)
- 资源浪费(例如一个PVC可能匹配到比声明容量大的卷)
- 对自动化工具不够友好
-
动态创建
- 根据用户请求按需创建持久卷,在用户请求时自动创建
- 动态创建需要使用存储类(StorageClass)
- 用户需要在持久卷声明(PVC)中指定存储类来自动创建声明中的卷。
- 如果没有指定存储类,使用集群中默认的存储类。
存储类(StorageClass)
一个集群可以存在多个存储类(StorageClass)来创建和管理不同类型的存储。
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件创建持久卷。 该字段必须指定。
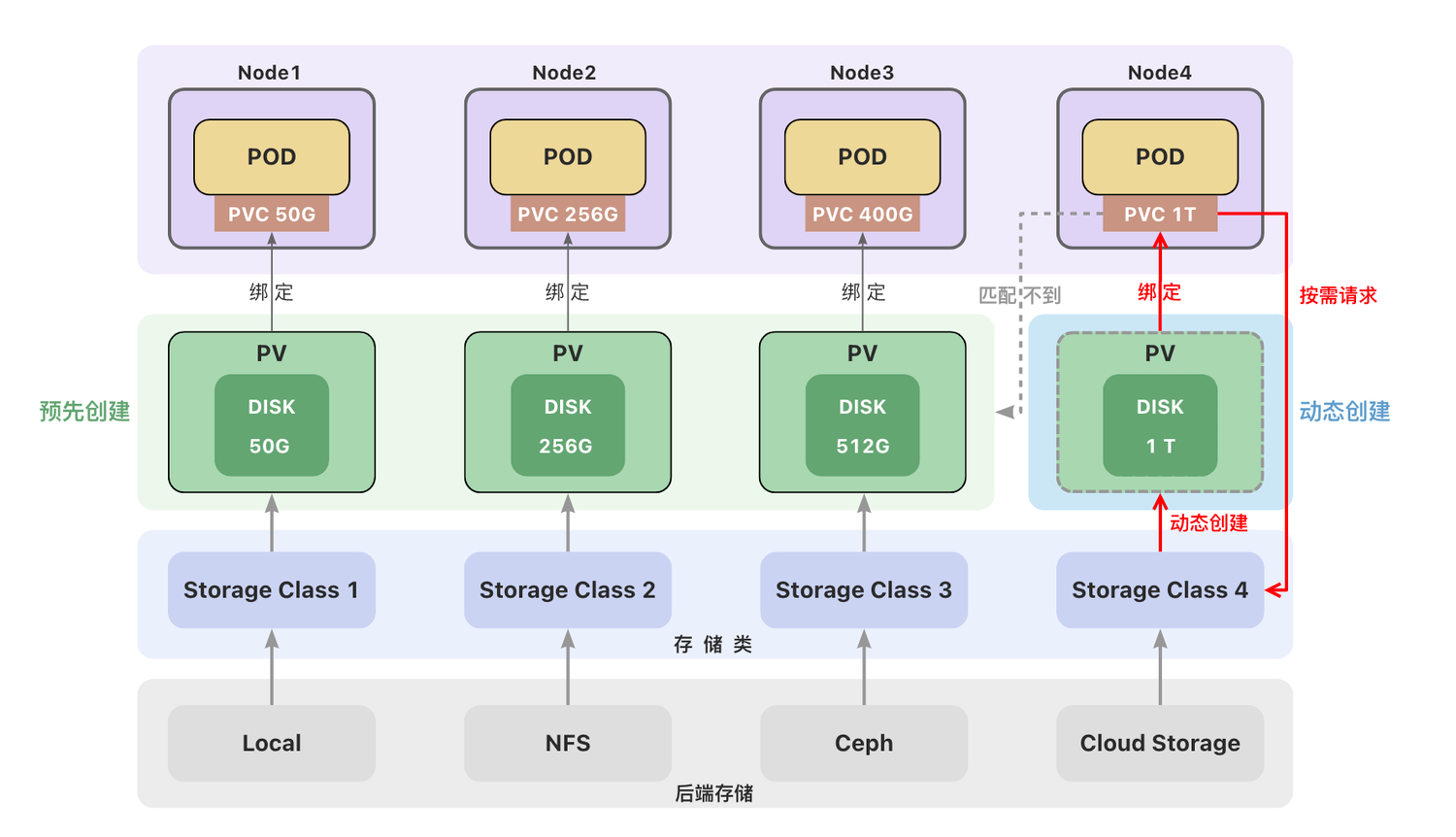
Local Path Provisioner

K3s自带了一个名为local-path的存储类(StorageClass),它支持动态创建基于hostPath或local的持久卷。创建PVC后,会自动创建PV,不需要再去手动的创建PV。删除PVC,PV也会被自动删除。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-path-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-path-pvc
卷绑定模式
volumeBindingMode用于控制什么时候动态创建卷和绑定卷。
Immediate立即创建
创建PVC后,立即创建PV并完成绑定。WaitForFirstConsume延迟创建
当使用该PVC的 Pod 被创建时,才会自动创建PV并完成绑定。
回收策略(Reclaim Policy)
回收策略告诉集群,当用户删除PVC 对象时, 从PVC中释放出来的PV将被如何处理。
- 删除(Delete)
如果没有指定,默认为Delete
当PVC被删除时,关联的PV 对象也会被自动删除。 - 保留(Retain)
StatefulSet(有状态应用集)
StatefulSet
如果我们需要部署多个MySQL实例,就需要用到StatefulSet。StatefulSet 是用来管理有状态的应用。一般用于管理数据库、缓存等。与 Deployment 类似, StatefulSet用来管理 Pod 集合的部署和扩缩。Deployment用来部署无状态应用。StatefulSet用来有状态应用。当 PVC 对象被删除时,PV 卷仍然存在,数据卷状态变为"已释放(Released)"。 此时卷上仍保留有数据,该卷还不能用于其他PVC。需要手动删除PV。
创建StatefulSet
StatefulSet配置模版
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
稳定的存储
在 StatefulSet 中使用 VolumeClaimTemplate,为每个 Pod 创建持久卷声明(PVC)。
每个 Pod 将会得到基于local-path 存储类动态创建的持久卷(PV)。 Pod 创建(或重新调度)时,会挂载与其声明相关联的持久卷。
请注意,当 Pod 或者 StatefulSet 被删除时,持久卷声明和关联的持久卷不会被删除。
Pod 标识
在具有 N 个副本的 StatefulSet中,每个 Pod 会被分配一个从 0 到 N-1 的整数序号,该序号在此 StatefulSet 上是唯一的。
StatefulSet 中的每个 Pod 主机名的格式为StatefulSet名称-序号。
上例将会创建三个名称分别为 mysql-0、mysql-1、mysql-2 的 Pod。
部署和扩缩保证
- 对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0..N-1。
- 当删除 Pod 时,它们是逆序终止的,顺序为 N-1..0。
- 在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
- 在一个 Pod 终止之前,所有的继任者必须完全关闭。
在上面的mysql示例被创建后,会按照 mysql-0、mysql-1、mysql-2 的顺序部署三个 Pod。在 mysql-0 进入 Running 和 Ready 状态前不会部署 mysql-1。在 mysql-1 进入 Running 和 Ready 状态前不会部署 mysql-2。 如果 mysql-1 已经处于 Running 和 Ready 状态,而 mysql-2 尚未部署,在此期间发生了 mysql-0 运行失败,那么 mysql-2 将不会被部署,要等到 mysql-0 部署完成并进入 Running 和 Ready 状态后,才会部署 mysql-2。如果用户想将示例中的 StatefulSet 扩缩为 replicas=1,首先被终止的是 mysql-2。 在 mysql-2 没有被完全停止和删除前,mysql-1 不会被终止。 当 mysql-2 已被终止和删除、mysql-1 尚未被终止,如果在此期间发生 mysql-0 运行失败, 那么就不会终止 mysql-1,必须等到 mysql-0 进入 Running 和 Ready 状态后才会终止 web-1。
Headless Service(无头服务)
之前我们创建了三个各自独立的数据库实例,mysql-0,mysql-1,mysql-2。
要想让别的容器访问数据库,我们需要将它发布为Service,但是Service带负载均衡功能,每次请求都会转发给不同的数据库,这样子使用过程中会有很大的问题
无头服务(Headless Services)
无头服务(Headless Service)可以为 StatefulSet 成员提供稳定的 DNS 地址。
在不需要负载均衡的情况下,可以通过指定 Cluster IP的值为 "None" 来创建无头服务。
注意:
StatefulSet中的ServiceName必须要跟Service中的metadata.name一致
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:
#重要!这里的名字要跟后面StatefulSet里ServiceName一致
name: db
labels:
app: database
spec:
ports:
- name: mysql
port: 3306
# 设置Headless Service
clusterIP: None
selector:
app: mysql
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db #重要!这里的名字要跟Service中metadata.name匹配
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
稳定的网络 ID
StatefulSet 中的每个 Pod 都会被分配一个StatefulSet名称-序号格式的主机名。
集群内置的DNS会为Service分配一个内部域名db.default.svc.cluster.local,它的格式为 服务名称.命名空间.svc.cluster.local。
Service下的每个Pod会被分配一个子域名,格式为pod名称.所属服务的域名,例如mysql-0的域名为mysql-0.db.default.svc.cluster.local。
创建Pod时,DNS域名生效可能会有一些延迟(几秒或几十秒)。
Pod之间可以通过DNS域名访问,同一个命名空间下可以省略命名空间及其之后的内容。
kubectl run dns-test -it --image=busybox:1.28 --rm
# 访问mysql-0数据库
nslookup mysql-0.db
Helm安装MySQL机群
Helm简介
Helm 是一个 Kubernetes 应用的包管理工具,类似于 Ubuntu 的 APT 和 CentOS 中的 YUM。
Helm使用chart 来封装kubernetes应用的 YAML 文件,我们只需要设置自己的参数,就可以实现自动化的快速部署应用。
安装Helm
下载安装包:
https://github.com/helm/helm/releases
https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
在K3s中使用,需要配置环境变量
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
三大概念
- Chart 代表着 Helm 包。
- 它包含运行应用程序需要的所有资源定义和依赖,相当于模版。
- 类似于maven中的pom.xml、Apt中的dpkb或 Yum中的RPM。
- Repository(仓库) 用来存放和共享 charts。
- 不用的应用放在不同的仓库中。
- Release 是运行 chart 的实例。
- 一个 chart 通常可以在同一个集群中安装多次。
- 每一次安装都会创建一个新的 release,release name不能重复。
Helm仓库
Helm有一个跟docker Hub类似的应用中心(https://artifacthub.io/),我们可以在里面找到我们需要部署的应用。
安装单节点Mysql
#添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
#查看chart
helm show chart bitnami/mysql
#查看默认值
helm show values bitnami/mysql
#安装mysql
helm install my-mysql \
--set-string auth.rootPassword="123456" \
--set primary.persistence.size=2Gi \
bitnami/mysql
#查看设置
helm get values my-mysql
#删除mysql
helm delete my-release
Helm部署MySQL集群
安装过程中有两种方式传递配置数据:
-f(或--values):使用 YAML 文件覆盖默认配置。可以指定多次,优先使用最右边的文件。-- set:通过命令行的方式对指定项进行覆盖。
如果同时使用两种方式,则 --set中的值会被合并到 -f中,但是 --set中的值优先级更高。
使用配置文件设置MySQL的参数。
auth:
rootPassword: "123456"
primary:
persistence:
size: 2Gi
enabled: true
secondary:
replicaCount: 2
persistence:
size: 2Gi
enabled: true
architecture: replication
helm install my-db -f values.yaml bitnami/mysql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号