
分布式系统——并发条件下如何保证缓存与DB数据一致性
什么是数据一致性
我们常说的数据一致性指的是在程序运行过程中本地缓存、分布式缓存、数据库三者之间的数据一致性
常见的本地缓存有 hashmap、currenthashmap、guava cache、caffeine
分布式缓存常见的有 redis、memcache
常见数据不一致常见有:
-
本地缓存与mysql不一致
-
redis缓存与mysql数据不一致
引入本地缓存的目的是增加服务的吞吐量、但是同时也会让架构变得复杂。
本地缓存与DB一致性解决方案
MQ方案
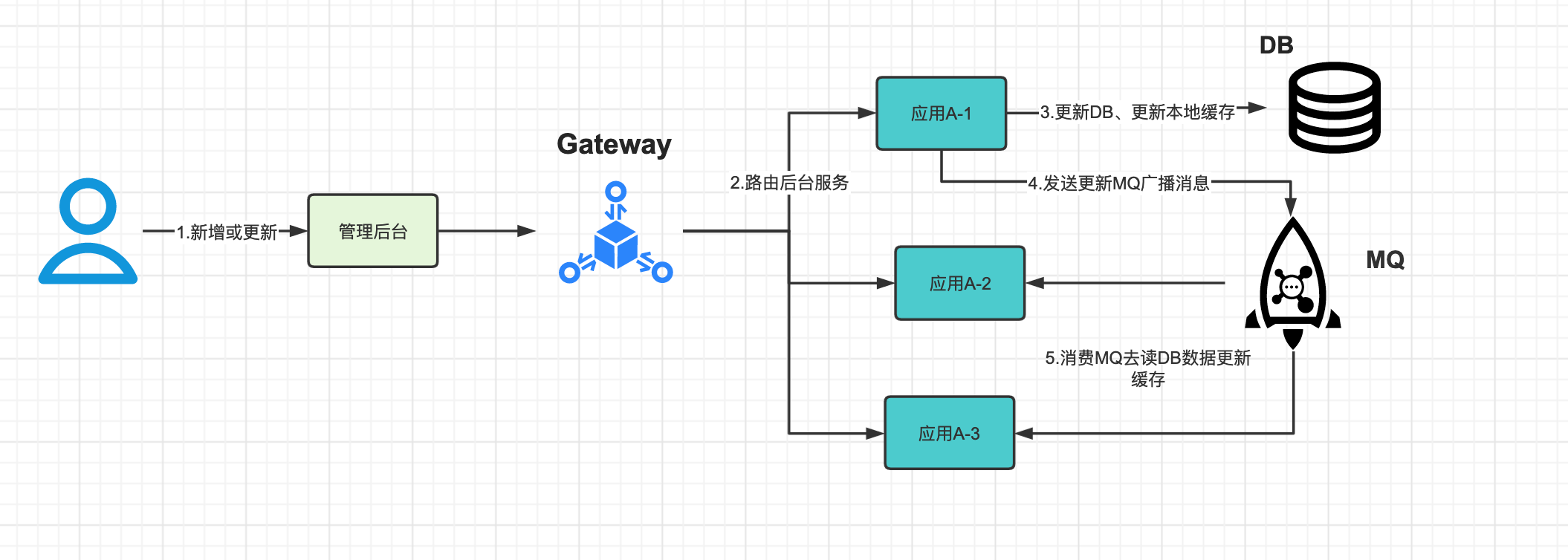
-
新增或更新了一条数据
-
通过gateway负载均衡策略转发到某一台应用A-1
-
应用A-1收到请求后,更新DB,同时更新了自己的本地缓存
-
应用A-1发送更新MQ的广播消息
-
应用A-2跟应用A-3收到消息,查询DB,更新本地缓存。
比较本地JVM变量的版本号与redis版本号
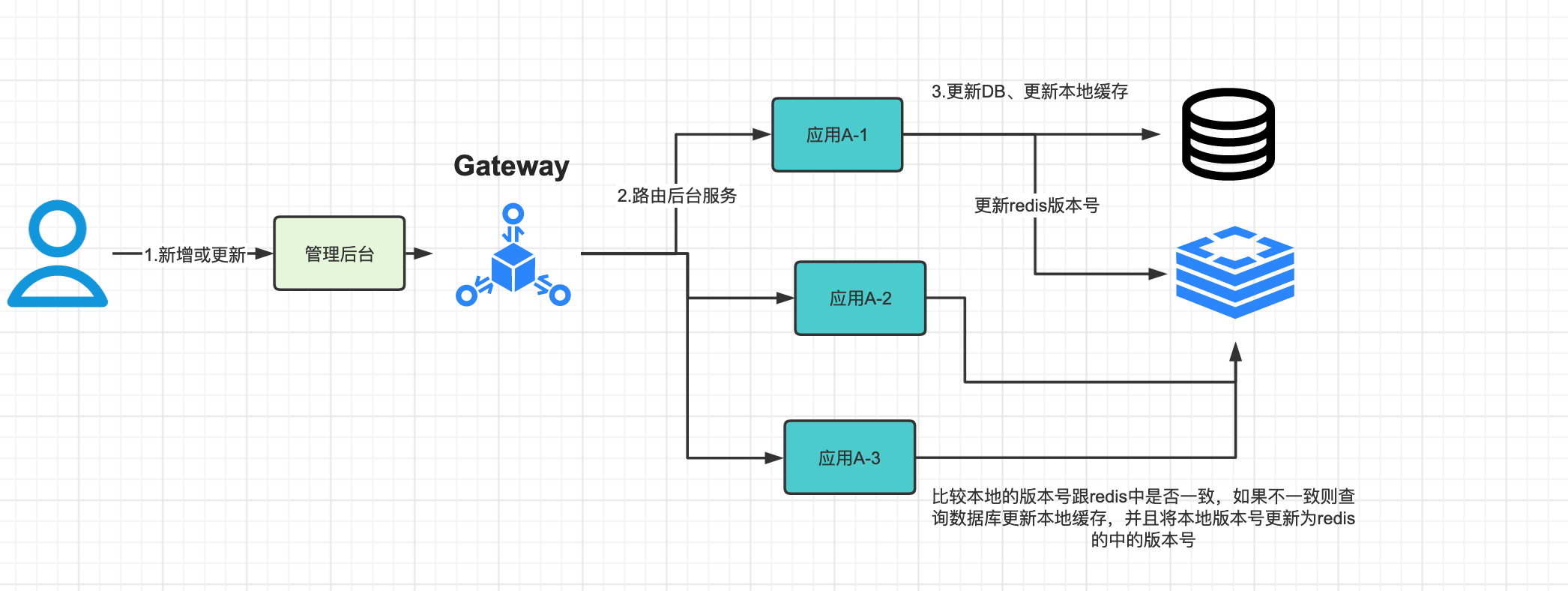
- 在应用本地定义一个成员变量LongAddr的版本号
- 比较redis中的版本号与本地变量中的是否相等
- 如果不相等则将DB中的数据读取到本地,同时将redis的版本号赋值到本地的版本号。
redis缓存与DB一致性解决方案
基于binlog方案
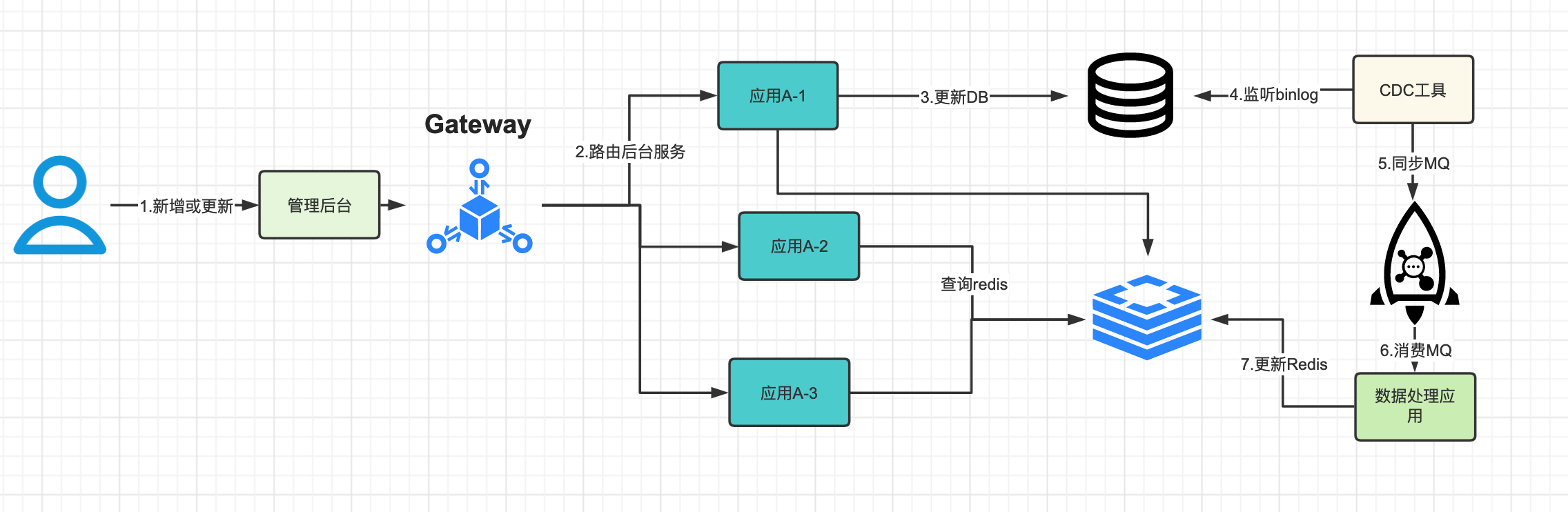
- 更新DB数据
- 通过CDC中间件监听mysql的binlog,同时同步数据到MQ
- 启动一个数据处理应用,消费MQ数据并进行数据加工
- 将加工后的数据写入redis
- 查询redis数据返回
延迟双删
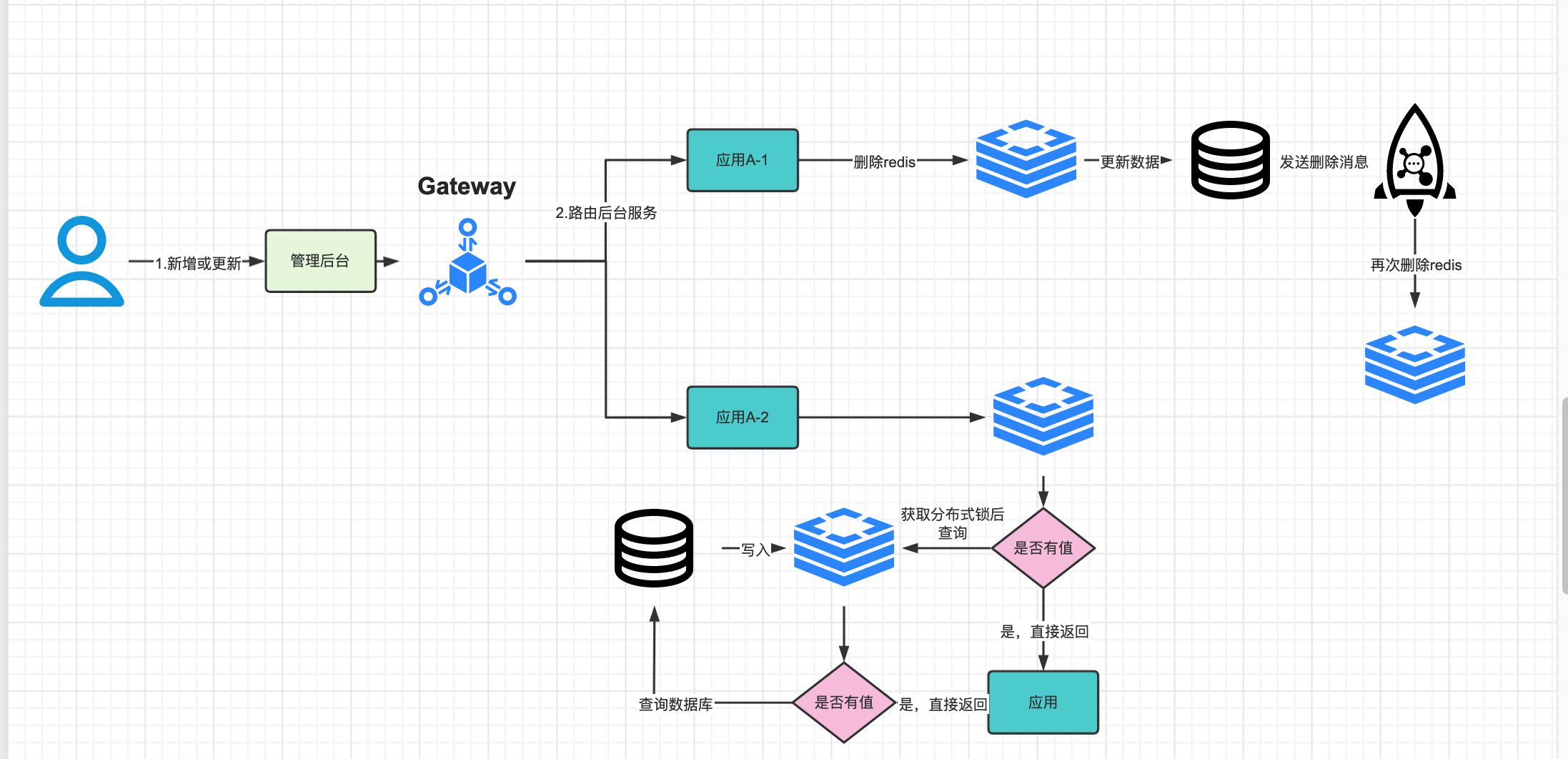
先进行缓存清除,再执行更新操作,最后(延迟N秒)再执行缓存删除,上述中延迟的时间一定要大于一次读写操作的时间,原因是如果延迟时间小于写入redis的时间,会导致请求1删除了缓存,但是请求2缓存还未写入。
基于定时任务方案

- 更新DB数据,同时写入数据到redis
- 启动一个定时任务将DB数据同步到redis
- 前端发起接口查询请求,先从redis中查询数据
- reidis中如果没有数据,加一个分布式锁,再从DB中查询数据
- 查询redis返回数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号