

.Net中XML,JSON的几种处理方式
一、XML:
1、基本了解:
xml,Extensible markup language可扩展标记语言,用于数据的传输或保存,特点,格式非常整齐数据清晰明了,并且任何语言都内置了xml分析引擎,
不需要再单独写引擎,但是相较于json解析较慢,现在很多项目任然有广泛的应用。
2、几种解析和生成xml的方式:这里,为了最后我们比较几种xml的解析以及生成速度,我们使用一个同一的xml进行生成以及解析:
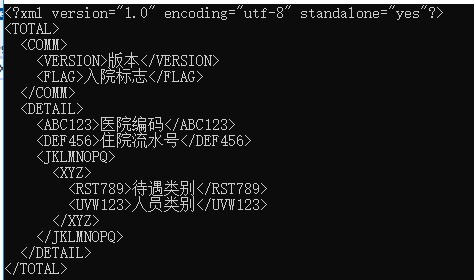
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <TOTAL> <COMM> <VERSION>版本</VERSION> <FLAG>入院标志</FLAG> </COMM> <DETAIL> <ABC123>医院编码</ABC123> <DEF456>住院流水号</DEF456> <JKLMNOPQ> <XYZ> <RST789>待遇类别</RST789> <UVW123>人员类别</UVW123> </XYZ> </JKLMNOPQ> </DETAIL> </TOTAL>
这是一个简单自己加的医院用的部分数据,可以使用自己觉的好用的xml,这里生成全部,获取数据我们全部取待遇类别这一项。
A、XmlReader和XmlWriter类:
public static string CreateXml() { //Indent属性设置或获取是否缩进的值 var xws = new XmlWriterSettings() {Indent=true,Encoding = Encoding.UTF8 }; StringBuilder sb = new StringBuilder(); //调用XmlWriter的静态生成方法Create,需要2个参数或者一个参数,一个作为输出 //另一个设置xml的格式 using (XmlWriter xw = XmlWriter.Create(sb,xws)) { //这里括号里的属性用来设置standalone的值 xw.WriteStartDocument(true); xw.WriteStartElement("TOTAL"); xw.WriteStartElement("COMM"); xw.WriteElementString("VERSION", "版本"); xw.WriteElementString("FLAG", "入院标志"); xw.WriteEndElement(); xw.WriteStartElement("DETAIL"); xw.WriteElementString("ABC123", "医院编码"); xw.WriteElementString("DEF456", "住院流水号"); xw.WriteStartElement("JKLMNOPQ"); xw.WriteStartElement("XYZ"); xw.WriteElementString("RST789", "待遇类别"); xw.WriteElementString("UVW123", "人员类别"); xw.WriteEndElement(); xw.WriteEndElement(); xw.WriteEndElement(); xw.WriteEndDocument(); } //这里因为字符串的格式是utf-16,通过最简单的方式调用Replace方法即可。如果是stringwriter,则使用派生类重写Encoding方法即可。 return sb.ToString().Replace("utf-16","utf-8"); }
这里我们先来简单解释一下standalone的意思,这个表示你所写的xml是否是独立的,如果为yes则表示它是独立的不能引用任何的DTD文件,
如果是no则表示它不是独立的,可以用外部的DTD文件,DTD文件:Document Type Definition文档类型定义,它是一套语法规则,用来检验你所写的
标准通用标记语言或者可扩展标记语言是否符合规则。
这里可以看到这个创建还是很简单的,WriteStartDocument创建文档,WriteEndDocument结束文档,WriteStartElement创建标签,WriteEndElement
创建结束标签,如果有具体值的使用WriteElementString(),接受2个参数:标签名和具体的值,同样的如果此标签有属性,使用WriteAttributeString()方法
即可。上面是书写xml的过程,现在开始获取xml的值:
public static string GetXmlInnerValue() { string result = string.Empty; //仍然调用XmlReader的Create静态方法生成 using (XmlReader reader = XmlReader.Create("Hospital.xml")) { while (reader.Read()) { try { //Read()方法会连xml的空白一起读,所以要加上XmlNodeType.Element来读元素 if (reader.MoveToContent() == XmlNodeType.Element && reader.Name == "RST789") { //这里微软建议尽量使用ReadElementContentAsString()方法,速度更快 //因为某些元素会比较复杂,所以使用ReadAsString方法要捕获异常,在异常中继续调用Read()方法就行了 result = reader.ReadElementContentAsString(); } else { reader.Read(); } } catch (Exception ex) { reader.Read(); } } } return result; }

这里也比较简单,通过调用Read()方法,在通过Name属性值,就可以确定我们要找的值。如果是要找属性值,调用
Reader的GetAttribute()方法即可,参数是属性的名称。
B、XmlSerializer类,通过序列化的手段操作xml,当然,用了序列化,那么相对的时间也会多一点,后面来证明,先建对象:
public class XYZ { [XmlElement("RST789")] public string Treatment { get; set; } [XmlElement("UVW123")] public string Personnel{ get; set; } }
public class JKLMNOPQ { [XmlElement] public XYZ XYZ { get; set; } }
public class DETAIL { [XmlElement("ABC123")] public string HospitalId { get; set; } [XmlElement("DEF456")] public string ResidentId { get; set; } [XmlElement] public JKLMNOPQ JKLMNOPQ { get; set; } }
public class COMM { [XmlElement] public string VERSION { get; set; } [XmlElement] public string FLAG { get; set; } }
[XmlRoot] public class TOTAL { [XmlElement] public COMM COMM { get; set; } [XmlElement] public DETAIL DETAIL { get; set; } }
这里我在项目里新建了个Model文件夹,然后添加了这5个类,可以看到这些类或者属性上面都有特性,特性是个常用也比较好用的东西,
可以暂时理解为注释这样一种东西对它所描述的东西的一个注解,后面详细会说,XmlRoot代表是xml中的根元素,XmlElement代表元素,
XmlAttribute代表属性,XmlIgnore则表示不序列化,后面如果有参数,则参数值表示在Xml中真实的值,比如类XYZ中,Treatment待遇类别,
但是xml中当然不能用Treatment显示,要用RST789显示,放在特性中就可以了,现在生成xml:
public static TOTAL GetTotal() => new TOTAL { COMM = new COMM { VERSION = "版本", FLAG = "入院标志" }, DETAIL = new DETAIL { HospitalId = "医院编码", ResidentId = "住院流水号", JKLMNOPQ = new JKLMNOPQ { XYZ = new XYZ { Treatment = "待遇类别", Personnel = "人员类别" } } } }; public static string CreateXml() { string xml = string.Empty; using (StringWriter sw = new StringWriter()) { XmlSerializerNamespaces xsn = new XmlSerializerNamespaces(); xsn.Add(string.Empty,string.Empty); XmlSerializer serializer = new XmlSerializer(typeof(TOTAL)); serializer.Serialize(sw,GetTotal(),xsn); xml = sw.ToString().Replace("utf-16","utf-8"); } return xml; }
先说明下第一个方法,这里用了C#6.0的新特性,如果表达式体方法只有一个,可以通过lambda语法来书写。
第二个方法里面直接调用XmlSerializer的Serialize方法进行序列化就可以了,那么反序列化用DeSerialize方法就可以了,这里的Serialize方法
有多钟参数,笔者可根据需要做相应调整,这里xml声明中的standalone不能做对应的书写,查了半天没有查到,如果再用XmlWriter或者DOM
做的话就用到了那这种方法的结合,如果有更好的方法可以留言,感激感激。
public static string GetXmlInnerValue() { TOTAL total = null; using (FileStream fs = new FileStream("Hospital.xml",FileMode.Open)) { XmlSerializer serializer = new XmlSerializer(typeof(TOTAL)); total = serializer.Deserialize(fs) as TOTAL; } return total.DETAIL.JKLMNOPQ.XYZ.Treatment; }

这里我尽量不适用XmlReader之类的转换xml方法,反序列化将xml转换为类,然后通过属性取到所需要的值。
C、DOM:现在说明很常见的一种解析xml方式DOM ,Document Obejct Model文档对象模型。说明一下DOM的工作方式,先将xml文档装入到内存,
然后根据xml中的元素属性创建一个树形结构,也就是文档对象模型,将文档对象化。那么优势显而易见,我么可以直接更新内存中的树形结构,因此
对于xml的插入修改删除效率更高。先看xml的书写:
public static string CreateXml() { XmlDocument doc = new XmlDocument(); XmlElement total = doc.CreateElement("TOTAL"); XmlElement comm = doc.CreateElement("COMM"); total.AppendChild(comm); XmlElement version = doc.CreateElement("VERSION"); version.InnerXml = "版本"; comm.AppendChild(version); XmlElement flag = doc.CreateElement("FLAG"); flag.InnerXml = "入院标志"; comm.AppendChild(flag); XmlElement detail = doc.CreateElement("DETAIL"); total.AppendChild(detail); XmlElement abc123 = doc.CreateElement("ABC123"); abc123.InnerXml = "医院编码"; detail.AppendChild(abc123); XmlElement def456 = doc.CreateElement("DEF456"); def456.InnerXml = "住院流水号"; detail.AppendChild(def456); XmlElement JKLMNOPQ = doc.CreateElement("JKLMNOPQ"); detail.AppendChild(JKLMNOPQ); XmlElement XYZ = doc.CreateElement("XYZ"); JKLMNOPQ.AppendChild(XYZ); XmlElement RST789 = doc.CreateElement("RST789"); RST789.InnerXml = "待遇类别"; XmlElement UVW123 = doc.CreateElement("UVW123"); UVW123.InnerXml = "人员类别"; XYZ.AppendChild(RST789); XYZ.AppendChild(UVW123); XmlDeclaration declaration = doc.CreateXmlDeclaration("1.0","utf-8","yes"); doc.AppendChild(declaration); doc.AppendChild(total); //XmlDocument的InnerXml属性只有元素内的内容,OuterXml则包含整个元素 return doc.OuterXml; }

这里的创建Xml还是比较简单的,document create一个XmlElement,Append一下,最后全部append到document上就可以了。
说明一下innerXml和innerText,这个学过html的人应该都懂,innertext和innerhtml区别一样,如果是纯字符,则两者通用,如果是
带有标签这种的<>,这样innerText则会将其翻译为<和>这样,而innerXml则不会翻译。另外如果是获取xml的内容,innerText
会获取所有的值,而innerXml则会将节点一起返回,现在获取xml的值:
public static string GetXmlInnerValue() { string result = string.Empty; XmlDocument doc = new XmlDocument(); doc.Load("Hospital.xml"); XmlNode xn = doc.SelectSingleNode("/TOTAL/DETAIL/JKLMNOPQ/XYZ/RST789"); result = xn.InnerXml; return result; }

这里经常用的就是XmlNode类,所有节点的抽象基类,提供了对节点的操作方法和属性,XmlNodeList类XmlNode的一组,如果有重复的节点
则使用XmlNodeList通过doc的GetElementsByTagName()获取,然后通过index获取需要的具体节点。还有这里SelectSingleNode()方法的参数
是这个节点的具体位置,而非节点名称,不然会报NullReferenceException。再说一下常用的属性,有HasChildNodes是否有子节点,ChildNodes
所有子节点,FirstChild第一个子节点,ParentChild父节点,NextSibling下一个兄弟节点,PreviousSibling 上一个兄弟节点。
D、使用LINQ解析:简单说下linq是什么,语言集成查询C#里面linq提供了不同数据的抽象层,所以可以使用相同的语法访问不同的数据源,简单来说
就是可以查询出一系列的数据不仅仅是从数据库查询,后面的篇章会进行详细说明。
public static string CreateXml() { string xml = string.Empty; XDocument doc = new XDocument( new XDeclaration("1.0","utf-8","yes"), new XElement("TOTAL", new XElement("COMM", new XElement("VERSION","版本"), new XElement("FLAG","入院标志")), new XElement("DETAIL", new XElement("ABC123","医院编码"), new XElement("DEF456","住院流水号"), new XElement("JKLMNOPQ", new XElement("XYZ", new XElement("RST789","待遇类别"), new XElement("UVW123","人员类别")))))); StringBuilder sb = new StringBuilder(); using (XmlWriter xw = XmlWriter.Create(sb)) { doc.WriteTo(xw); } xml = sb.ToString().Replace("utf-16","utf-8"); return xml; }

这里使用了XDocument这个类创建xml也是很简单的,主要注意一下括号别多别少就行了,同样需要编码转换不然仍然出来的是utf-16。
public static string GetXmlInnerValue() { string result = string.Empty; XDocument doc = XDocument.Load("Hospital.xml"); var query = from r in doc.Descendants("RST789") select r; foreach (var item in query) { result = item.Value; } return result; }

这里Linq同样也是使用以操作内存的方式操作xml,和DOM的方式比较类似,也是比较快速的方法。
E、XPathNavigator类:System.Xml.XPath下的一个抽象类,它根据实现IXPathNavigable的接口的类创建,如XPathDocument,XmlDocument。由XPathDocument创建的XPathNavigator是只读对象,对于.net framework由XmlDocument创建的XPathNavigator可以进行修改,它的CanEdit属性为true,必须要在4.6版本以上,可以使用#if进行判断。对于.net core没有提供CreateNavigator这个方法所以它始终是可读的。这个类可以理解为一个光标搜索,一个Navigator对数据进行导航,它不是一个流模型,对于xml只分析和读取一次。
public static string GetXmlInnerValue() { string str = string.Empty; XPathDocument doc = new XPathDocument("Hospital.xml"); XPathNavigator navigator = doc.CreateNavigator(); XPathNodeIterator iterator = navigator.Select("/TOTAL/DETAIL/JKLMNOPQ/XYZ/RST789"); while (iterator.MoveNext()) { if (iterator.Current.Name == "RST789") { str = iterator.Current.Value; } } return str; }
public static string GetValue() { string result = string.Empty; XPathDocument doc = new XPathDocument("Hospital.xml"); XPathNavigator navigator = doc.CreateNavigator(); XPathNodeIterator iterator = navigator.Select("/TOTAL"); while (iterator.MoveNext()) { XPathNodeIterator iteratorNew = iterator.Current.SelectDescendants(XPathNodeType.Element, false); while (iteratorNew.MoveNext()) { if (iteratorNew.Current.Name== "RST789") { result = iteratorNew.Current.Value; } } } return result; }
如果没有重复节点的情况下直接用第一种写好路径就行了,如果有重复节点就要用第二种进行多次循环了。现在我们用StopWatch进行时间监测。
static void Main(string[] args) { Console.WriteLine("生成xml的时间:"); Stopwatch sw = new Stopwatch(); sw.Start(); XmlReaderAndXmlWriter.CreateXml(); sw.Stop(); Console.WriteLine($"XmlReaderAndXmlWriter生成时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XmlSerializerSample.CreateXml(); sw.Stop(); Console.WriteLine($"XmlSerializerSample生成时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); DomSample.CreateXml(); sw.Stop(); Console.WriteLine($"DomSample生成时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); LinqSample.CreateXml(); sw.Stop(); Console.WriteLine($"LinqSample生成时间:{sw.Elapsed}"); sw.Reset(); Console.WriteLine("====================================================="); Console.WriteLine("查询xml的时间:"); sw.Restart(); XmlReaderAndXmlWriter.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XmlReaderAndXmlWriter查询时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XmlSerializerSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XmlSerializerSample查询时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); DomSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"DomSample查询时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); LinqSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"LinqSample查询时间:{sw.Elapsed}"); sw.Reset(); sw.Restart(); XPathNavigatorSample.GetXmlInnerValue(); sw.Stop(); Console.WriteLine($"XPathNavigatorSample查询时间:{sw.Elapsed}"); }

这里我们可以看到无论是生成还是查询都是DOM的操作更为快速一点,序列化相比就慢很多了,另外比较新的技术XPathNavigator也很快了,
再综合代码的精简程度,选择合适的方法进行传输数据就可以了。现在开始总结JSON的2种常用用法。
二、JSON:
1、简介:Javascript Object Notation是一种轻量级的数据交互格式,采用完全独立于语言的格式传输和存储数据,语法简介,相较于xml解析速度更快。
2、介绍2种常用的解析方式。
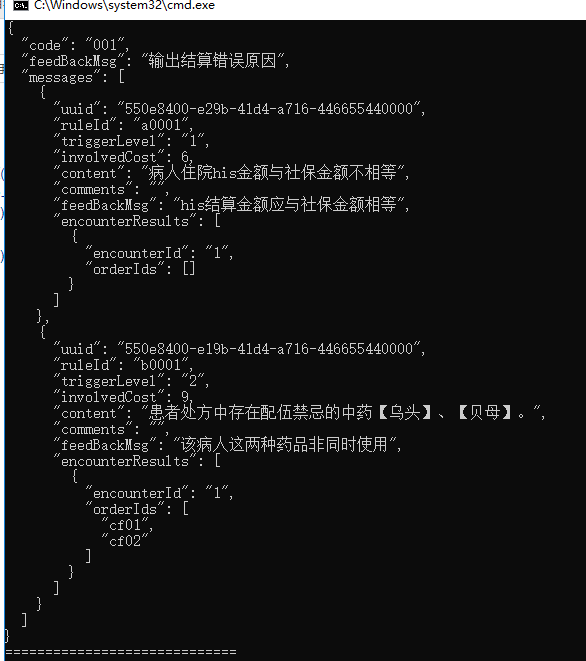
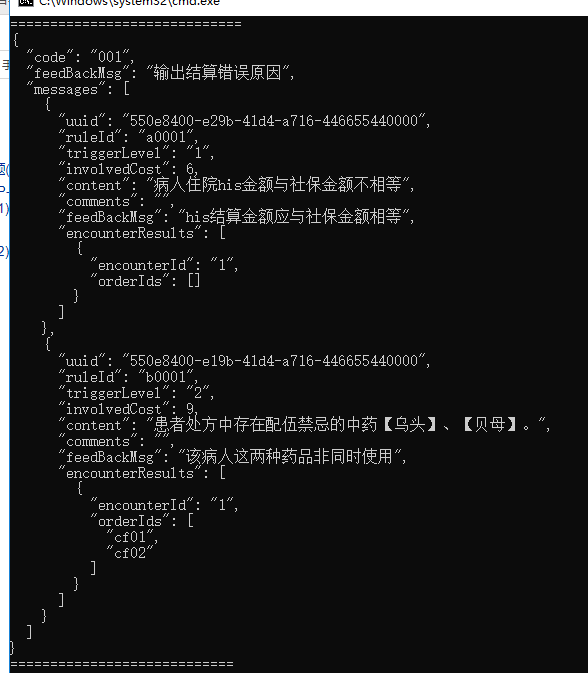
先设定一个json做比较对象:
{ "code": "001", "feedBackMsg": "输出结算错误原因", "messages": [ { "uuid": "550e8400-e29b-41d4-a716-446655440000", "ruleId": "a0001", "triggerLevel": "1", "involvedCost": 6, "content": "病人住院his金额与社保金额不相等", "comments": "", "feedBackMsg": "his结算金额应与社保金额相等", "encounterResults": [ { "encounterId": "1", "orderIds": [] } ] }, { "uuid": "550e8400-e19b-41d4-a716-446655440000", "ruleId": "b0001", "triggerLevel": "2", "involvedCost": 9, "content": "患者处方中存在配伍禁忌的中药【乌头】、【贝母】。", "comments": "", "feedBackMsg": "该病人这两种药品非同时使用", "encounterResults": [ { "encounterId": "1", "orderIds": [ "cf01", "cf02" ] } ] } ] }
然后用2种方式分别生成:
第一种:
public static string CreateJson1() { string json = string.Empty; Dictionary<string, object> data = new Dictionary<string, object> { {"code" ,"001" }, {"feedBackMsg" ,"输出结算错误原因" }, {"messages" ,new List<object>{ new Dictionary<string,object> { {"uuid" ,"550e8400-e29b-41d4-a716-446655440000"}, {"ruleId" ,"a0001"}, {"triggerLevel" ,"1"}, {"involvedCost" ,6}, {"content" ,"病人住院his金额与社保金额不相等"}, {"comments","" }, {"feedBackMsg" ,"his结算金额应与社保金额相等"}, {"encounterResults" ,new List<object> { new Dictionary<string,object>{ {"encounterId","1" }, {"orderIds" ,new List<object> { } } } } } }, new Dictionary<string, object> { {"uuid" ,"550e8400-e19b-41d4-a716-446655440000"}, {"ruleId" ,"b0001"}, {"triggerLevel" ,"2"}, {"involvedCost" ,9}, {"content" ,"患者处方中存在配伍禁忌的中药【乌头】、【贝母】。"}, {"comments" ,""}, {"feedBackMsg" ,"该病人这两种药品非同时使用"}, {"encounterResults" ,new List<object> { new Dictionary<string,object> { {"encounterId","1" }, {"orderIds" ,new List<object> { "cf01","cf02" } } } } } } } } }; json = JsonConvert.SerializeObject(data,Formatting.Indented); return json; }
第二种:
public static string CreateJson2() { var root = new JObject { {"code" ,"001"} ,{ "feedBackMsg", "输出结算错误原因" } ,{"messages" , new JArray { new JObject { { "uuid", "550e8400-e29b-41d4-a716-446655440000" }, {"ruleId" ,"a0001" } ,{"triggerLevel" ,"1"} ,{"involvedCost" ,6} ,{"content" ,"病人住院his金额与社保金额不相等"} , {"comments" ,""} ,{"feedBackMsg" ,"his结算金额应与社保金额相等"} ,{"encounterResults" ,new JArray{ new JObject { { "encounterId" ,"1"} ,{ "orderIds" ,new JArray { } } } } } } , new JObject{ {"uuid" , "550e8400-e19b-41d4-a716-446655440000" } ,{ "ruleId" ,"b0001"} ,{ "triggerLevel", "2"} , {"involvedCost" ,9 } ,{"content" ,"患者处方中存在配伍禁忌的中药【乌头】、【贝母】。" } ,{"comments" ,""} , {"feedBackMsg" ,"该病人这两种药品非同时使用"} ,{"encounterResults" ,new JArray{ new JObject{ { "encounterId", "1"} , {"orderIds" ,new JArray{"cf01" ,"cf02"} } } } } } } } }; return root.ToString(); }
这里这2种方法都引用了 这个第三方文件,可以在Nuget包中直接找到,然后添加引用即可,第一种采用序列化
这个第三方文件,可以在Nuget包中直接找到,然后添加引用即可,第一种采用序列化
Dictionary,第二种用JObject和JArray生成,都很简单,而且可以处理很复杂的json字符串,比较麻烦的就是写这个的时候必须非常认真,稍一溜号
可能大括号就再也对不上了。。。这里讲2种比较通用的方法就可以了,当然还可以直接把json用字符串直接拼起来,本来还想说一下比较近的LitJson,
但是这个第三方程序有个不足,它的内部定义编码是unicode,对于中文会进行转换,可以从git上下载源码然后改动以后就对中文没有影响了,也可以
使用正则表达式的Unescape方法转换。
public static string CreateJson() { JsonWriter writer = new JsonWriter(); writer.WriteObjectStart(); writer.WritePropertyName("code"); writer.Write("001"); writer.WritePropertyName("feedBackMsg"); writer.Write("输出结算错误原因"); writer.WritePropertyName("messages"); writer.WriteArrayStart(); writer.WriteObjectStart(); writer.WritePropertyName("uuid"); writer.Write("550e8400-e29b-41d4-a716-446655440000"); writer.WritePropertyName("ruleId"); writer.Write("a0001"); writer.WritePropertyName("triggerLevel"); writer.Write("1"); writer.WritePropertyName("involvedCost"); writer.Write(6); writer.WritePropertyName("content"); writer.Write("病人住院his金额与社保金额不相等"); writer.WritePropertyName("feedBackMsg"); writer.Write("该病人这两种药品非同时使用"); writer.WritePropertyName("comments"); writer.Write(""); writer.WriteArrayStart(); writer.WriteObjectStart(); writer.WritePropertyName("encounterId"); writer.Write("1"); writer.WritePropertyName("orderIds"); writer.WriteArrayStart(); writer.WriteArrayEnd(); writer.WriteObjectEnd(); writer.WriteArrayEnd(); writer.WriteObjectEnd(); writer.WriteArrayEnd(); writer.WriteObjectEnd(); return System.Text.RegularExpressions.Regex.Unescape(writer.ToString()); }

这里看到中文编码合适,现在开始解析json串中的值。
这里我们取OrderId中的第二个值,第一种用反序列化的方法:先构造实体类。
public class RootObject { public string code { get; set; } public string feedBackMsg { get; set; } public List<Messages> messages { get; set; } } public class Messages { public string uuid { get; set; } public string ruleId { get; set; } public string triggerLevel { get; set; } public int involvedCost { get; set; } public string content { get; set; } public string comments { get; set; } public string feedBackMsg { get; set; } public List<EncounterResults> encounterResults { get; set; } } public class EncounterResults { public string encounterId { get; set; } public List<string> orderIds { get; set; } }
public static string GetJsonInnerValue2(string json) { var newType = JsonConvert.DeserializeObject<RootObject>(json); return newType.messages[1].encounterResults[0].orderIds[1]; }
这里只要盯好每个元素是什么类型的就可以了,代码还是很简单的。第二种方法我们选择使用LitJson,这里只取值所以不需要考虑一下
中文乱码的情况,并且使用LitJson不需要构造实体类,非常方便。
public static string GetJsonInnerValue3(string json) { JsonData data = JsonMapper.ToObject(json); return data["feedBackMsg"].ToString(); } public static string GetJsonInnerValue4(string json) { JsonData data = JsonMapper.ToObject(json); return data["messages"][1]["encounterResults"][0]["orderIds"][1].ToString(); }

当然这个东西还是需要先在Nuget包中下载引用,很简单方便。
三、Xml和Json之间的相互转换:
1、先看xml转换为json,仍然选取前面的xml进行转换:
public static string XmlToJsonTest() { string json = string.Empty; XmlDocument doc = new XmlDocument(); doc.Load("Hospital.xml"); XmlNode node = doc.SelectSingleNode("/TOTAL"); json = JsonConvert.SerializeXmlNode(node); return json; }

因为xml里面还有XmlDeclaration,所以通过JsonConvert的SerializeXmlNode通过节点的方式转换,如果想去掉根节点,调用
SerializerXmlNode的重载方法即可。
2,现在用json转换为xml:
public static string JsonToXmlTest() { string xml = string.Empty; string json = "{\"code\":\"001\",\"feedBackMsg\":\"输出结算错误原因\",\"messages\":[{\"uuid\":\"550e8400-e29b-41d4-a716-446655440000\",\"ruleId\":\"a0001\",\"triggerLevel\":\"1\",\"involvedCost\":6,\"content\":\"病人住院his金额与社保金额不相等\",\"comments\":\"\",\"feedBackMsg\":\"his结算金额应与社保金额相等\",\"encounterResults\":[{\"encounterId\":\"1\",\"orderIds\":[]}]},{\"uuid\":\"550e8400-e19b-41d4-a716-446655440000\",\"ruleId\":\"b0001\",\"triggerLevel\":\"2\",\"involvedCost\":9,\"content\":\"患者处方中存在配伍禁忌的中药【乌头】、【贝母】。\",\"comments\":\"\",\"feedBackMsg\":\"该病人这两种药品非同时使用\",\"encounterResults\":[{\"encounterId\":\"1\",\"orderIds\":[\"cf01\",\"cf02\"]}]}]}"; XmlDocument doc = JsonConvert.DeserializeXmlNode(json,"root"); xml = doc.OuterXml; return xml; }

这里因为json中没有根节点,所以使用DeserializeXmlNode的重载方法,加一个root根节点即可。
这样最后xml和json之间的相互转换也完成了,数据传输的总结到此结束了,还有不明之处,请多多指教。
2019-03-01 12:03:56

