

表查询数据准备及测试、ORM常见查询关键字、双下划线查询、查看ORM底层SQL语句、ORM外键字段创建、外键字段数据操作、正反向概念、基于对象的跨表查询(子查询)、基于双下划线的跨表查询(连表操作)
表查询数据准备及测试、ORM常见查询关键字、双下划线查询、查看ORM底层SQL语句、ORM外键字段创建、外键字段数据操作、正反向概念、基于对象的跨表查询(子查询)、基于双下划线的跨表查询(连表操作)
一、表查询数据准备及测试环境搭建
1.django自带一个sqlite3小型数据库
该数据库功能非常有限,并且针对日期类型的数据兼容性很差
2.django切换MySQL数据库
django1.x
import pymysql
pymysql.install_as_MySQLdb()
django2.x/3.x/4.x
pip install mysqlclient
3.定义模型类
class User(models.Model):
uid = models.AutoField(primary_key=True, verbose_name='编号')
name = models.CharField(max_length=32, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
join_time = models.DateField(auto_now_add=True)
"""
日期字段重要参数
auto_now:每次操作数据并保存都会自动更新当前时间
auto_now_add:只在创建数据的那一刻自动获取当前时间之后如果不人为更改则不变
"""
4.数据库迁移命令(模型类对应的映射关系是表)
python38 manage.py makemigrations
python38 manage.py migrate
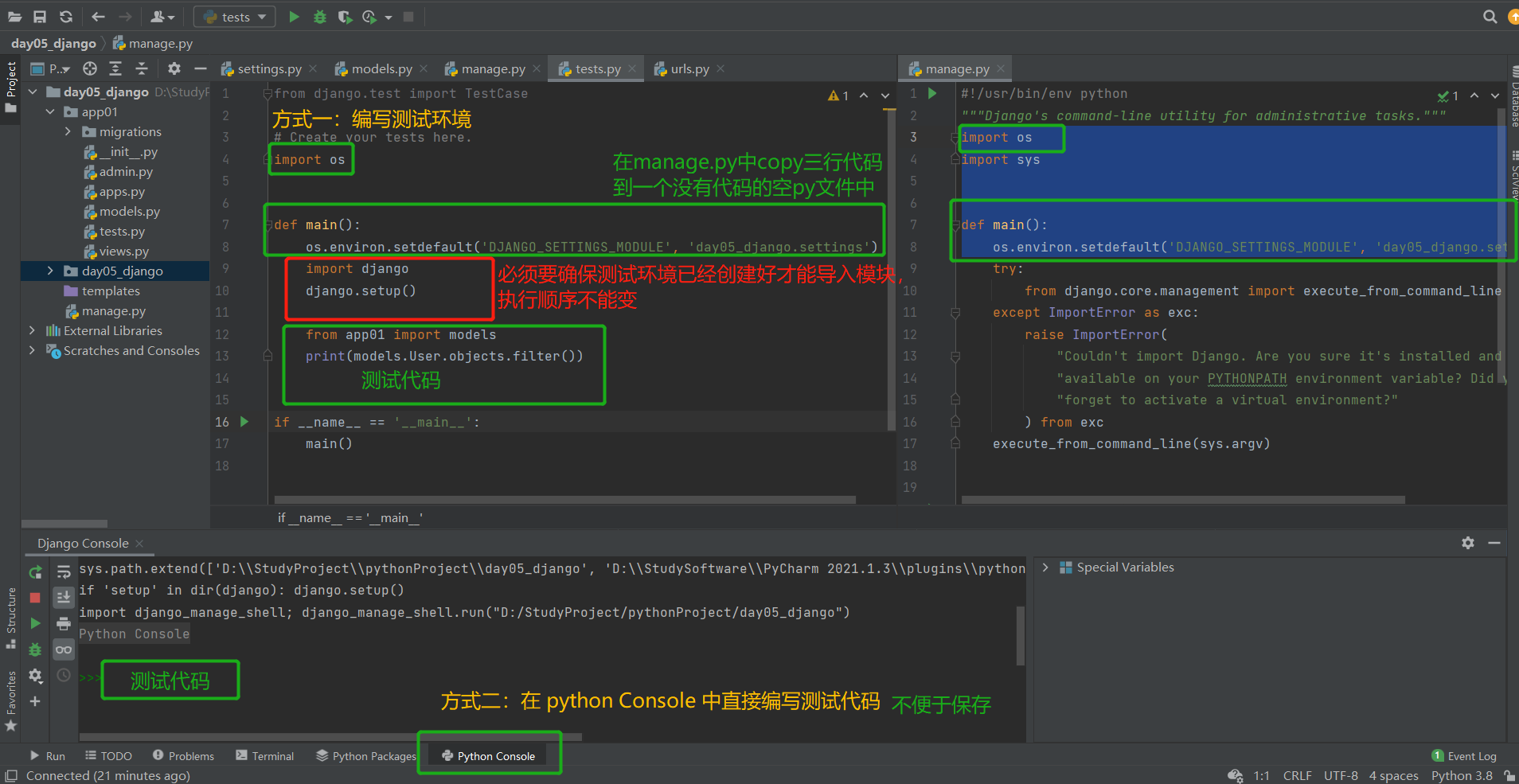
5.模型层测试环境准备
# 不能够导入模块直接写测试脚本会报错
方式一:在任意空的py文件中准备环境
# Create your tests here.
import os
def main():
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'day05_django.settings')
import django
django.setup()
from app01 import models
print(models.User.objects.filter())
if __name__ == '__main__':
main()
方式二:pycharm提供的测试环境
python ConSole 命令行测试环境
二、ORM常见查询关键字
1.当需要查询数据主键字段值的时候,可以使用pk忽略掉数据字段的真正的名字
数据对象.pk
'''自动找到主键字段,无需核查主键字段的真正名字,通过pk直接获取'''
2.创建数据的两种方式
1)create()
'''创建数据,返回值就是当前创建的数据对象'''
res = models.User.objects.create(name='jason', age=18)
print(res) # res就是数据对象
print(res.name)
print(res.age)
print(res.uid)
print(res.pk) # 自动找到主键字段
2)对象.save()
'''利用实例化对象然后调用save方法创建'''
user_obj = models.User(name='kevin', age=20)
user_obj.save()
3.在模型类中可以定义一个__str__方法,便于后续数据对象被打印展示的时候查看方便
def __str__(self):
'''对象被执行打印(print、页面展示、数据查询)操作的时候自动触发'''
# 数据库迁移命令是在编写的代码与数据库有关系有影响才会执行,添加数据与数据库是没有关系的
return f'对象:{self.name}' # 该方法必须要返回一个字符串类型的数据
4.Queryset中如果是列表套对象那么可直接for循环取值以及索引取值,但是不支持负索引取值会报错
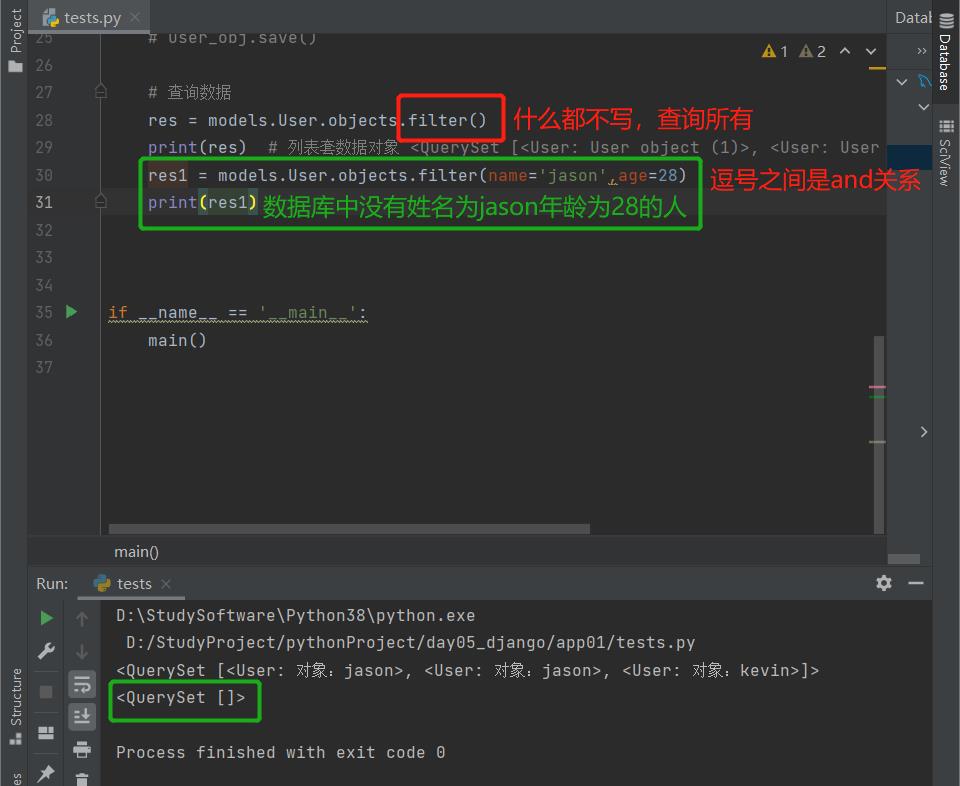
1.filter():筛选数据
筛选数据,返回值是一个QuerySet(可以看成列表套数据对象)
1)括号内不写查询条件,默认就是查询所有
2)括号内填写查询条件,并且支持多个,之间用逗号隔开,默认是and关系
# 查询数据
res = models.User.objects.filter()
print(res) # 列表套数据对象 <QuerySet [<User: User object (1)>, <User: User object (2)>, <User: User object (3)>]>
res1 = models.User.objects.filter(name='jason',age=28)
print(res1) # <QuerySet []>
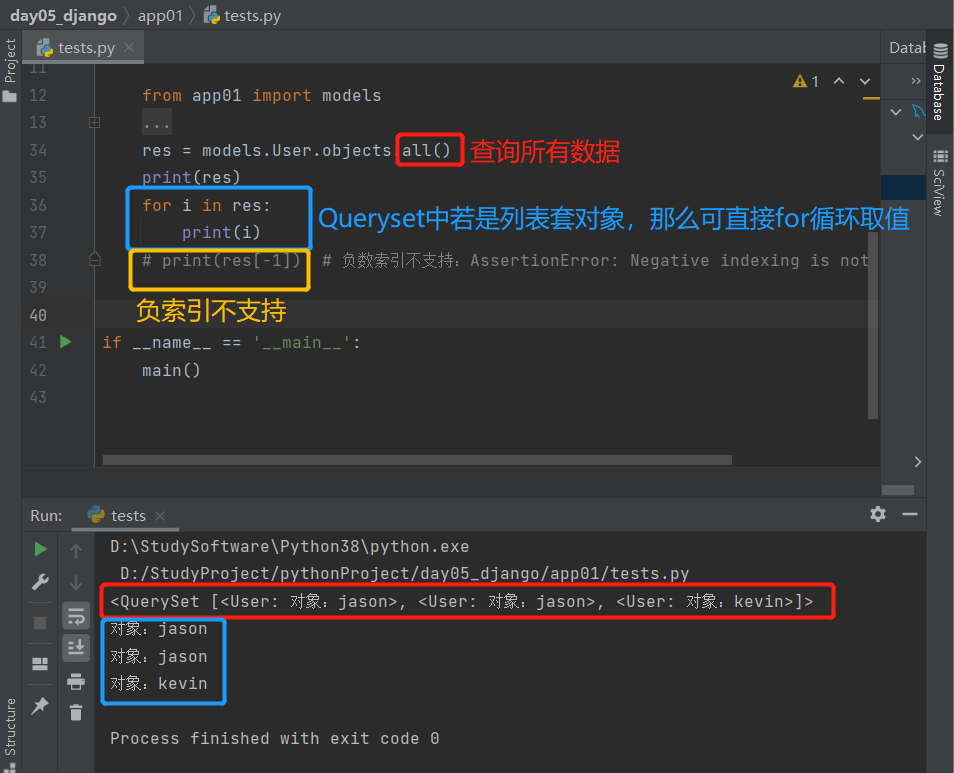
2.all():查询所有数据
查询所有的数据,返回值是一个QuerySet(可以看成是列表套数据对象)
'''Queryset中如果是列表套对象那么可直接for循环取值以及索引取值,但是不支持负索引取值会报错'''
# 查询所有数据
res = models.User.objects.all()
print(res)
for i in res:
print(i)
print(res[-1]) # 负数索引不支持:AssertionError: Negative indexing is not supported.
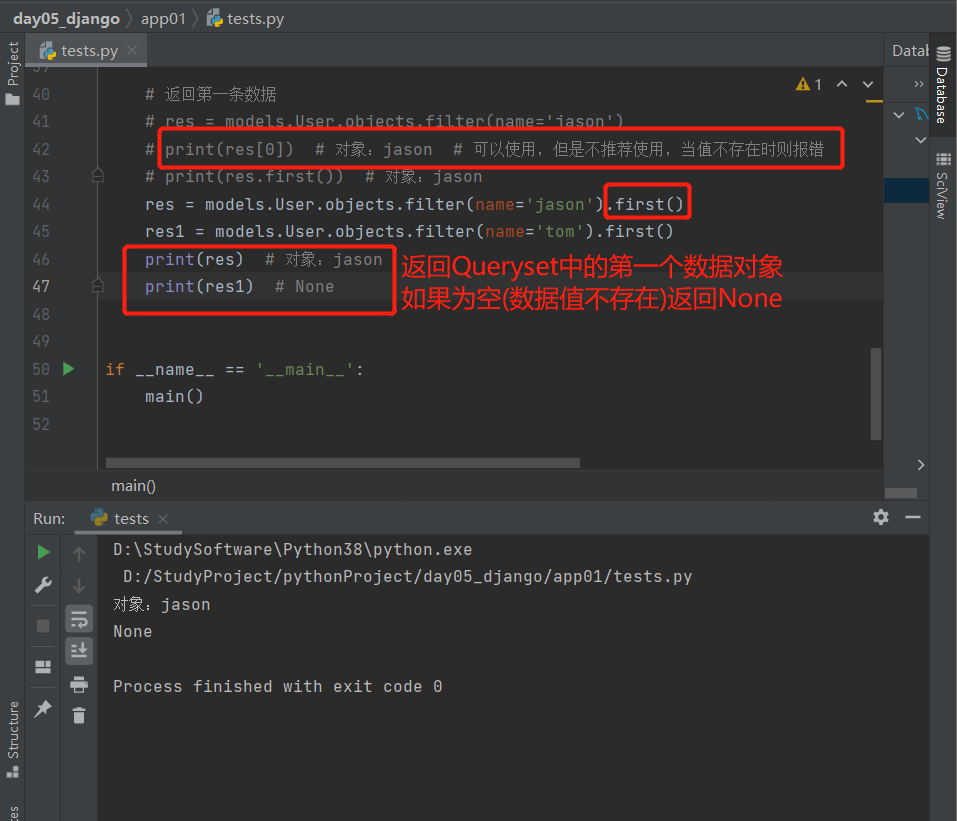
3.first():返回第一条记录
获取Queryset中的第一个数据对象,如果为空则返回None
# 返回第一条数据
res = models.User.objects.filter(name='jason')
print(res[0]) # 对象:jason # 可以使用,但是不推荐使用,当值不存在时则报错
print(res.first()) # 对象:jason
res = models.User.objects.filter(name='jason').first()
res1 = models.User.objects.filter(name='tom').first()
print(res) # 对象:jason
print(res1) # None
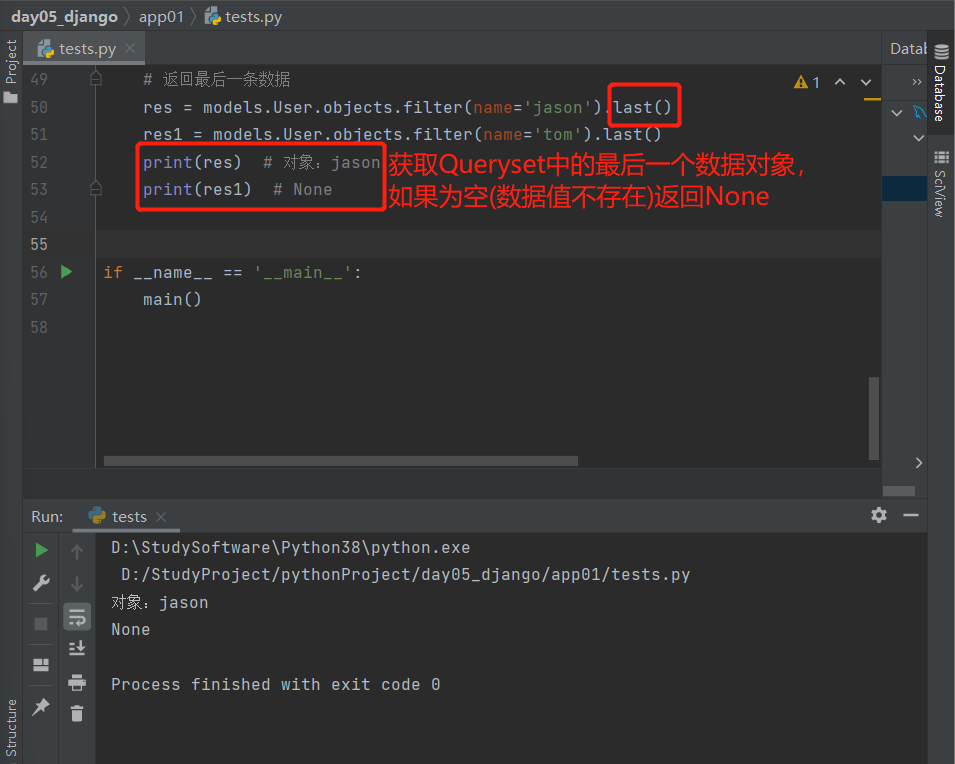
4.last():返回最后一条数据
获取Queryset中最后一个数据对象,如果为空则返回None
# 返回最后一条数据
res = models.User.objects.filter(name='jason').last()
res1 = models.User.objects.filter(name='tom').last()
print(res) # 对象:jason
print(res1) # None
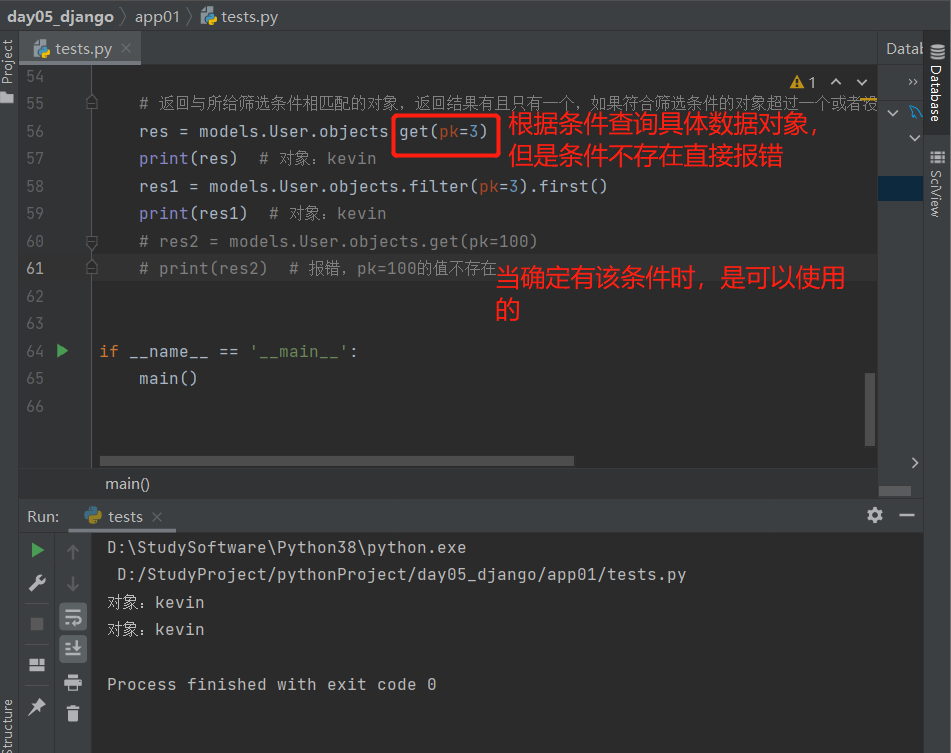
5.get():返回与所给筛选条件相匹配的对象
直接根据条件查询具体的数据对象,但是条件不存在直接报错,不推荐使用
'''返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误'''
# 返回与所给筛选条件相匹配的对象
res = models.User.objects.get(pk=3)
print(res) # 对象:kevin
res1 = models.User.objects.filter(pk=3).first()
print(res1) # 对象:kevin
res2 = models.User.objects.get(pk=100)
print(res2) # 报错,pk=100的值不存在
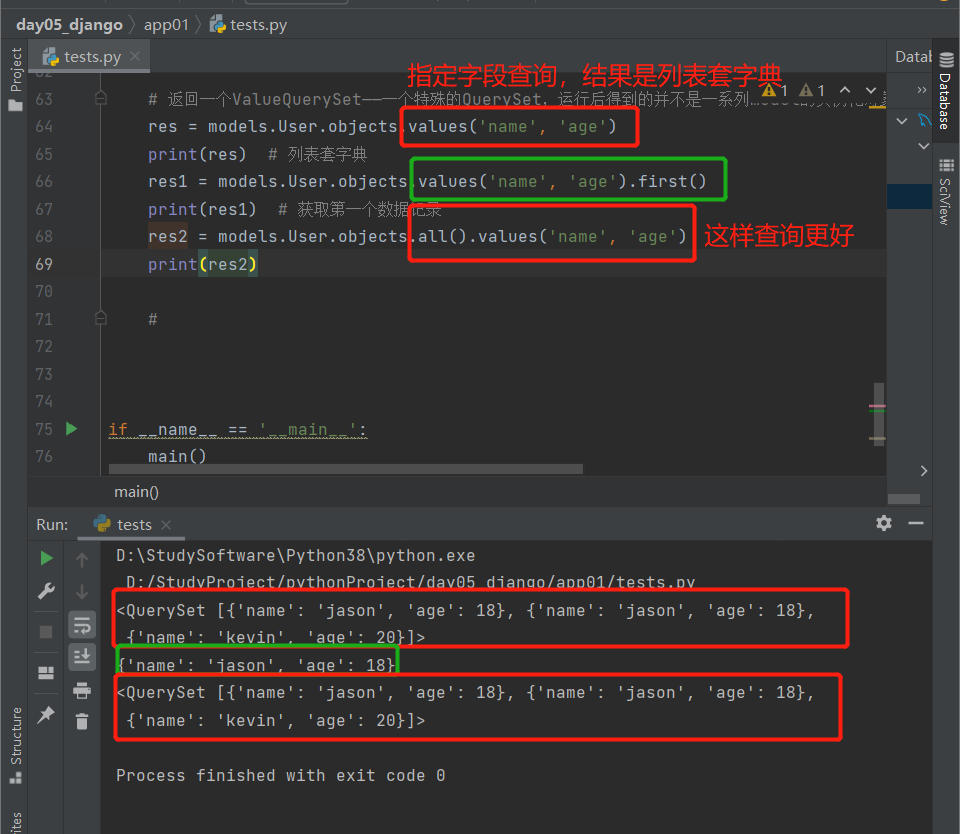
6.values():指定查询字段
指定查询字段,结果是Queryset(可以看成是列表套字典数据)
'''返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列'''
# 指定查询字段
res = models.User.objects.values('name', 'age')
print(res) # 列表套字典
res1 = models.User.objects.values('name', 'age').first()
print(res1) # 获取第一个数据记录
res2 = models.User.objects.all().values('name', 'age')
print(res2)
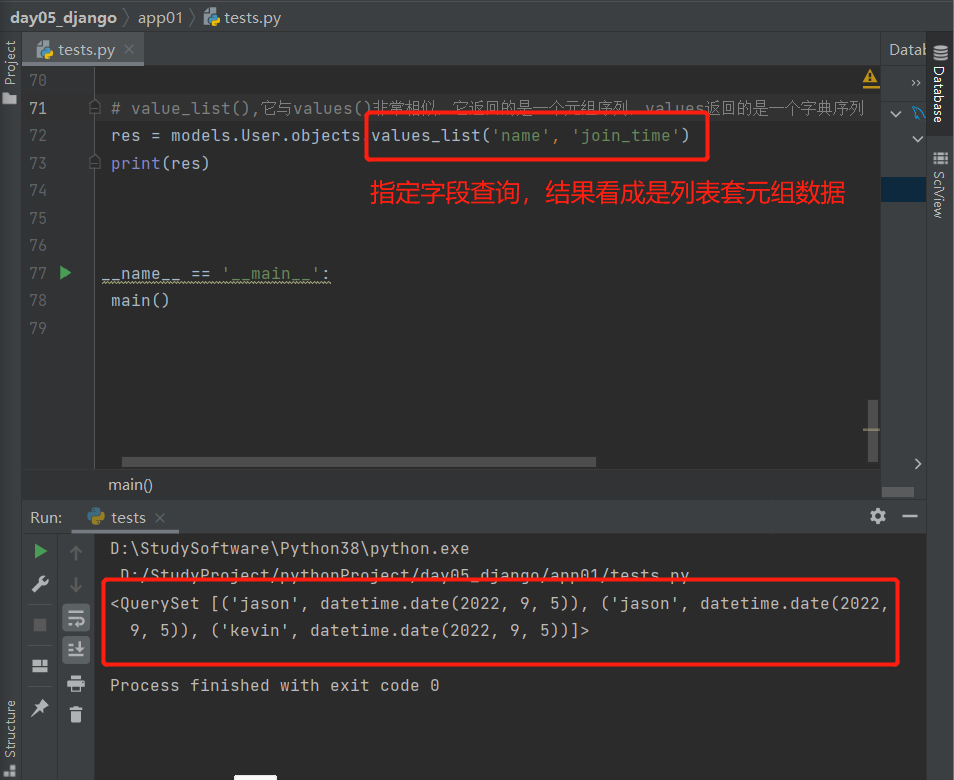
7.values_list():指定查询字段
指定查询字段,结果是Queryset(可以看成是列表套元组数据)
'''value_list(),它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列'''
# 指定查询字段
res = models.User.objects.values_list('name', 'join_time')
print(res)
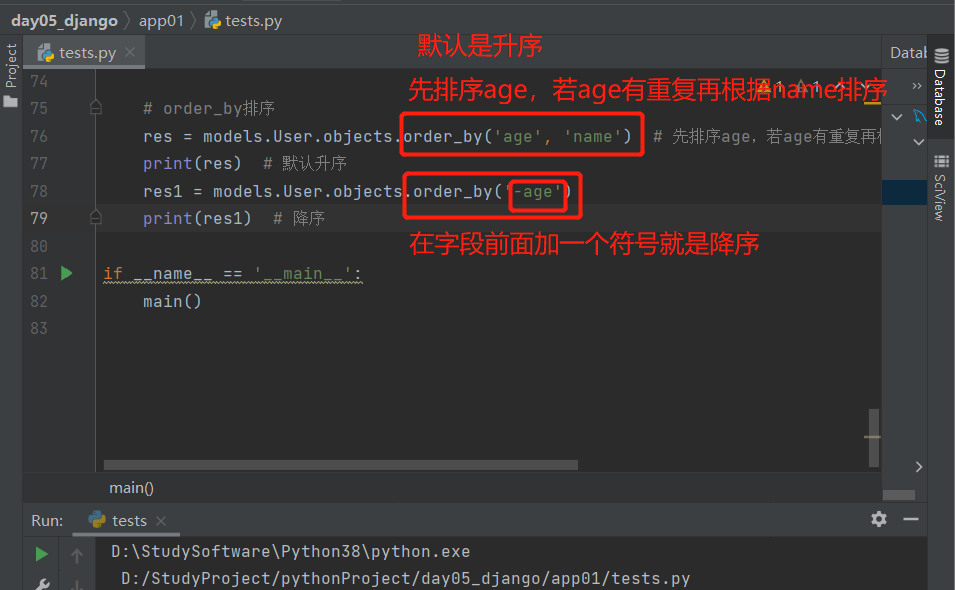
8.order_by():排序
指定字段排序,默认是升序;在字段前加负号则为降序,并且支持多个字段排序
# 排序
res = models.User.objects.order_by('age', 'name') # 先排序age,若age有重复再根据那么排序
print(res) # 默认升序
res1 = models.User.objects.order_by('-age')
print(res1) # 降序
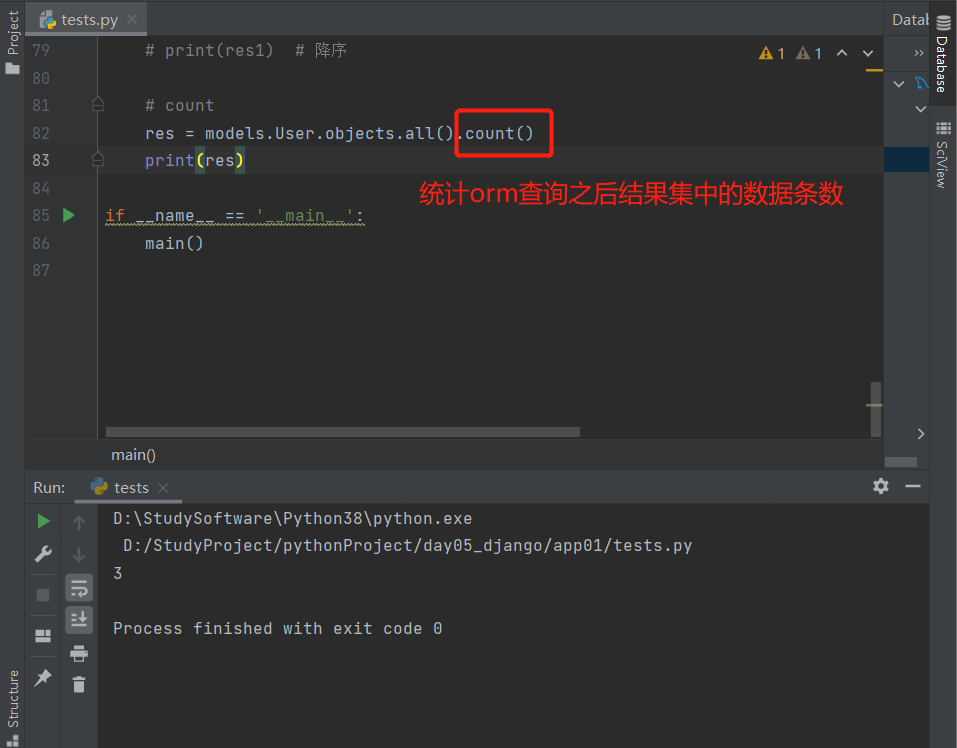
9.count():返回数据库中匹配查询(QuerySet)的对象数量。
统计orm查询之后结果集中的数据条数
# count 统计
res = models.User.objects.all().count()
print(res)
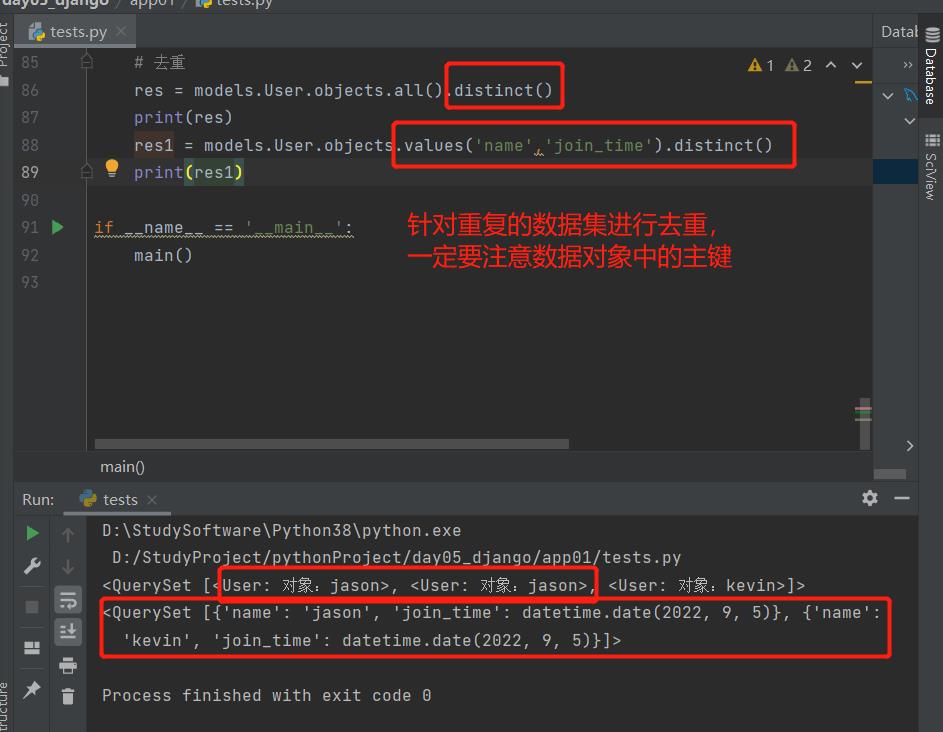
10.distinct():去重
针对重复的数据集进行去重,一定要注意数据对象中的主键
'''从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。)'''
# 去重
res = models.User.objects.all().distinct()
print(res)
res1 = models.User.objects.values('name','join_time').distinct()
print(res1)
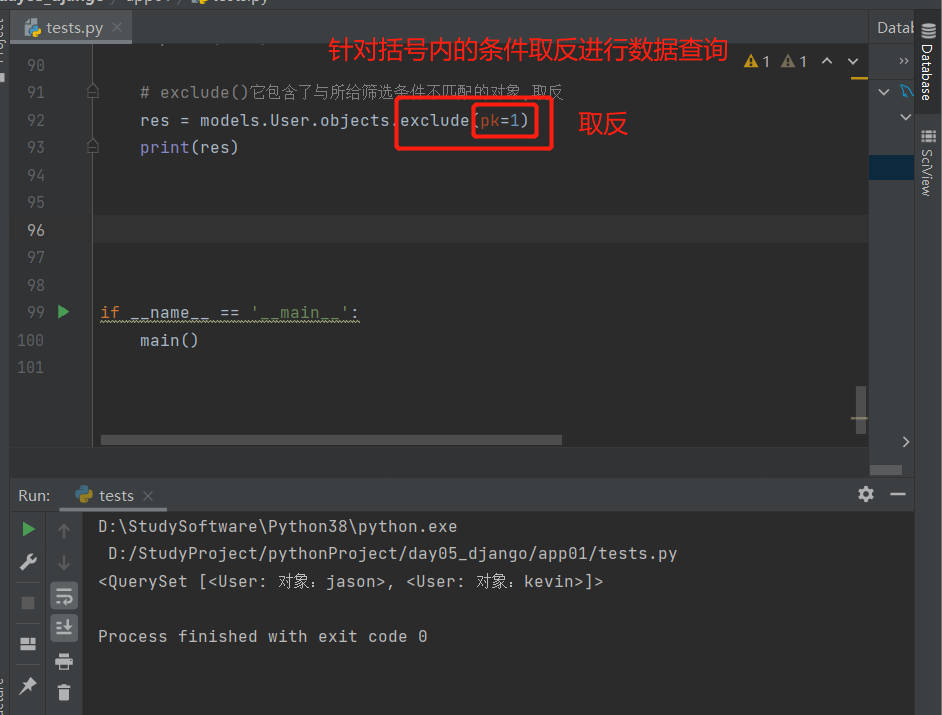
11.exclude():取反
针对括号内的条件取反进行数据查询,QuerySet(可以看成是列表套数据对象)
'''它包含了与所给筛选条件不匹配的对象'''
# exclude(),取反
res = models.User.objects.exclude(pk=1)
print(res)
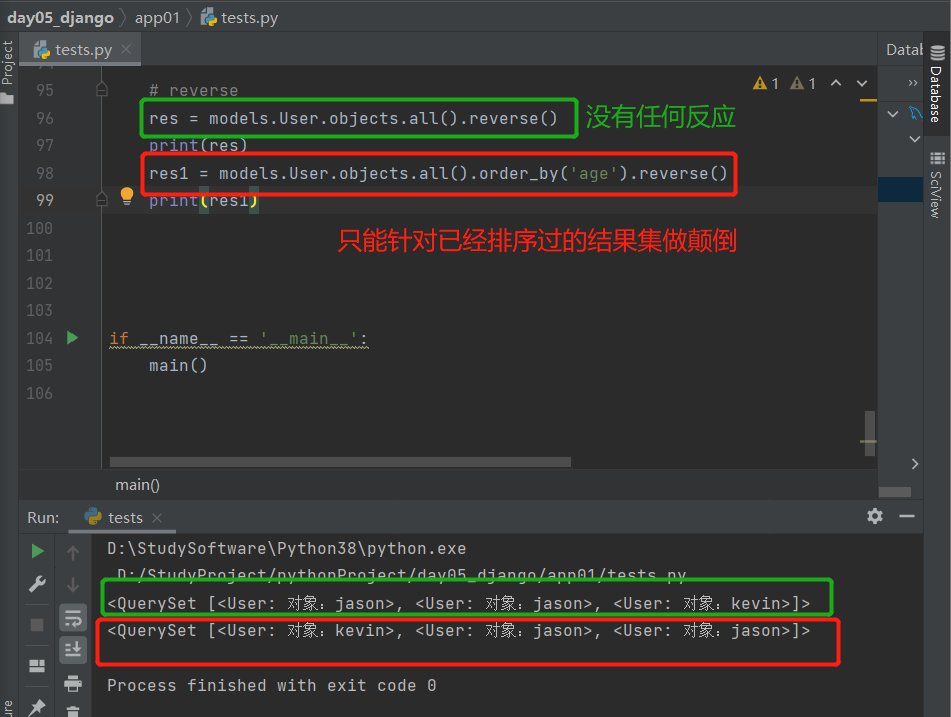
12.reverse():颠倒
针对已经排了序的结果集做颠倒
'''对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。'''
# reverse,颠倒
res = models.User.objects.all().reverse()
print(res)
res1 = models.User.objects.all().order_by('age').reverse()
print(res1)
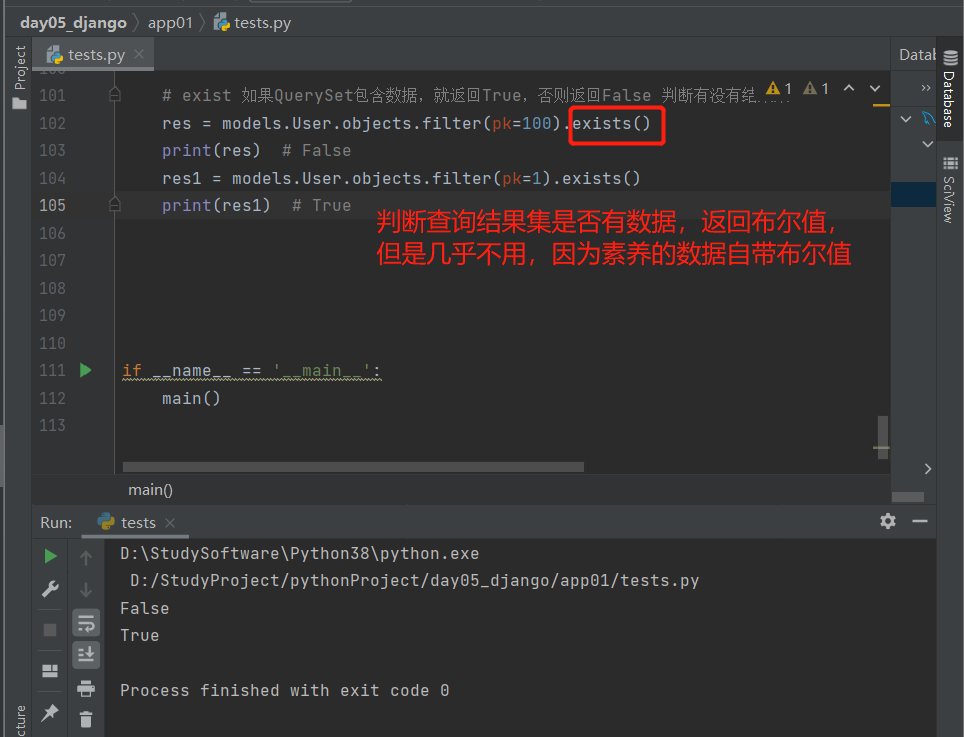
13.exists():查询所有数据
判断查询结果集是否有数据,返回布尔值,但是几乎不用因为所有数据自带布尔值
'''如果QuerySet包含数据,就返回True,否则返回False'''
# exist
res = models.User.objects.filter(pk=100).exists()
print(res) # False
res1 = models.User.objects.filter(pk=1).exists()
print(res1) # True
14.raw():自己写SQL语句
# raw
res = models.User.objects.raw('select * from app01_user')
print(res)
print(list(res))
执行SQL语句
还可以借助于模块
from django.db import connection
cursor = connection.cursor()
cursor.execute("insert into hello_author(name) VALUES ('郭敬明')")
cursor.execute("update hello_author set name='韩寒' WHERE name='郭敬明'")
cursor.execute("delete from hello_author where name='韩寒'")
cursor.execute("select * from hello_author")
cursor.fetchone()
cursor.fetchall()
三、神奇的双下划线的查询
1.比较运算符
字段__gt 大于
字段__lt 小于
字段__gte 大于等于
字段__lte 小于等于
res = models.User.objects.filter(age__gt=20) # 年龄大于20
print(res)
res1 = models.User.objects.filter(age__lt=20) # 年龄小于20
print(res1)
res2 = models.User.objects.filter(age__gte=20) # 年龄大于等于20
print(res2)
res3 = models.User.objects.filter(age__lte=20) # 年龄小于等于20
print(res3)
2.成员运算符
字段__in 查询数据条件在什么内的数据
res = models.User.objects.filter(age__in=[20, 22, 24]) # 年龄在20 22 24 的人
print(res)
3.范围查询(数字)
字段__range 查询多少到多少的数据
# 年龄在20~30之间的数据
res = models.User.objects.filter(age__range=(20,30)) # 顾头顾尾
print(res)
4.模糊查询
字段__contains 不忽略大小写
字段__icontains 忽略大小写
# 查询姓名中含有字母j的数据
res = models.User.objects.filter(name__contains='j') # 不忽略大小写
print(res) # <QuerySet [<User: 对象:jason>, <User: 对象:jack>]>
res1 = models.User.objects.filter(name__icontains='j') # 忽略大小写
print(res1) # <QuerySet [<User: 对象:jason>, <User: 对象:JasonNB>, <User: 对象:jack>]>
5.日期处理
字段__year 查询年份为多少的数据
字段__month 查询月份为多少的数据
字段__day 查询日子为多少的数据
# 查询注册年份是2020年的数据
res = models.User.objects.filter(join_time__year=2020)
print(res) # <QuerySet [<User: 对象:JasonNB>]>
# 查询注册月份是8月的数据
res1 = models.User.objects.filter(join_time__month=8)
print(res1) # <QuerySet [<User: 对象:tom>]>
# 查询注册日子是18的数据
res2 = models.User.objects.filter(join_time__day=18)
print(res2) # <QuerySet [<User: 对象:tom>]>
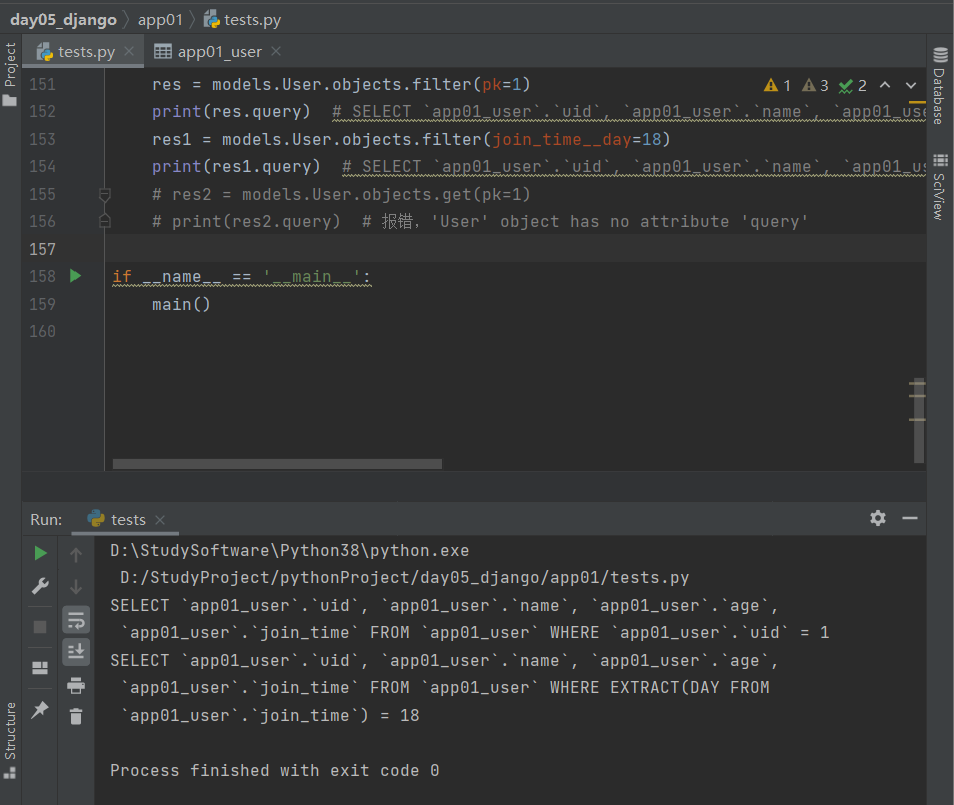
四、查看ORM底层的SQL语句
方式一:如果是Queryset对象 那么可以直接点query查看SQL语句
res = models.User.objects.filter(pk=1)
print(res.query) # SELECT `app01_user`.`uid`, `app01_user`.`name`, `app01_user`.`age`, `app01_user`.`join_time` FROM `app01_user` WHERE `app01_user`.`uid` = 1
res1 = models.User.objects.filter(join_time__day=18)
print(res1.query) # SELECT `app01_user`.`uid`, `app01_user`.`name`, `app01_user`.`age`, `app01_user`.`join_time` FROM `app01_user` WHERE EXTRACT(DAY FROM `app01_user`.`join_time`) = 18
# res2 = models.User.objects.get(pk=1)
# print(res2.query) # 报错,'User' object has no attribute 'query'
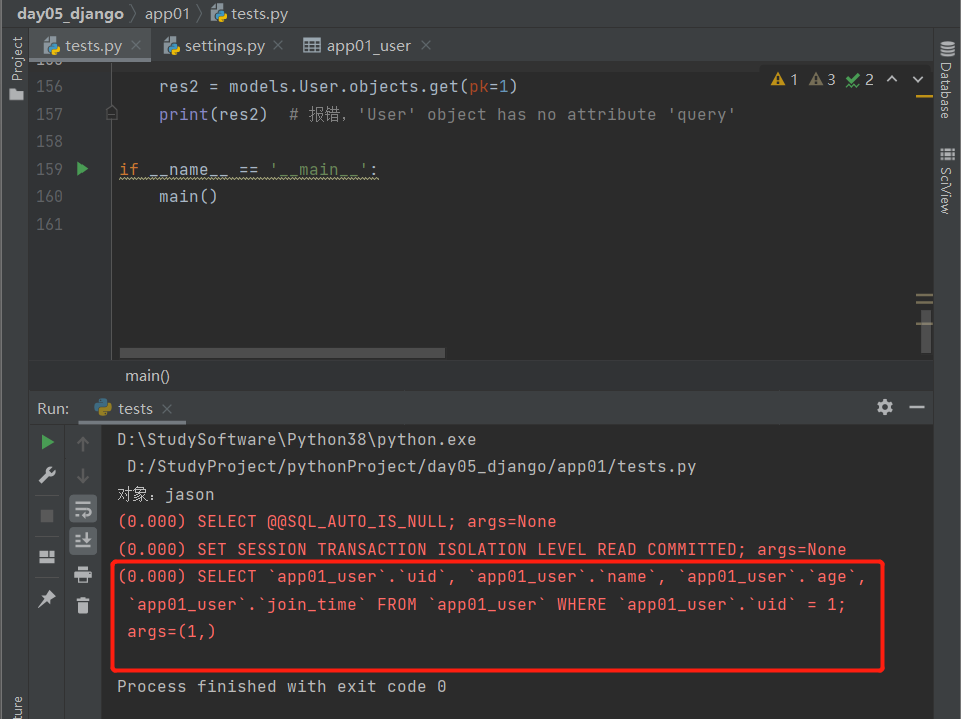
方式二:在Django项目的settings.py文件中,在最后复制粘贴如下代码:
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上。
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
五、ORM外键字段创建
一对多:
orm中外键建在多的一方
models.Foreignkey()(会自动添加_id后缀)
多对多:
orm中有三种创建多对多字段的方式 models.ManyToManyField()
1)直接在查询频率较高的表中填写字段即可,自动创建第三张关系表
2)自己创建第三张关系表
3)自己创建第三张关系表,到那时还是要orm多对多字段做关联
一对一:
orm中外键字段建在查询频率较高的表中 models.OneToOneField()(会自动添加_id后缀)
PS:
django1.X 针对 models.ForeignKey() models.OneToOneField()不需要on_delete
django2.X 3.X 则需要添加on_delete参数
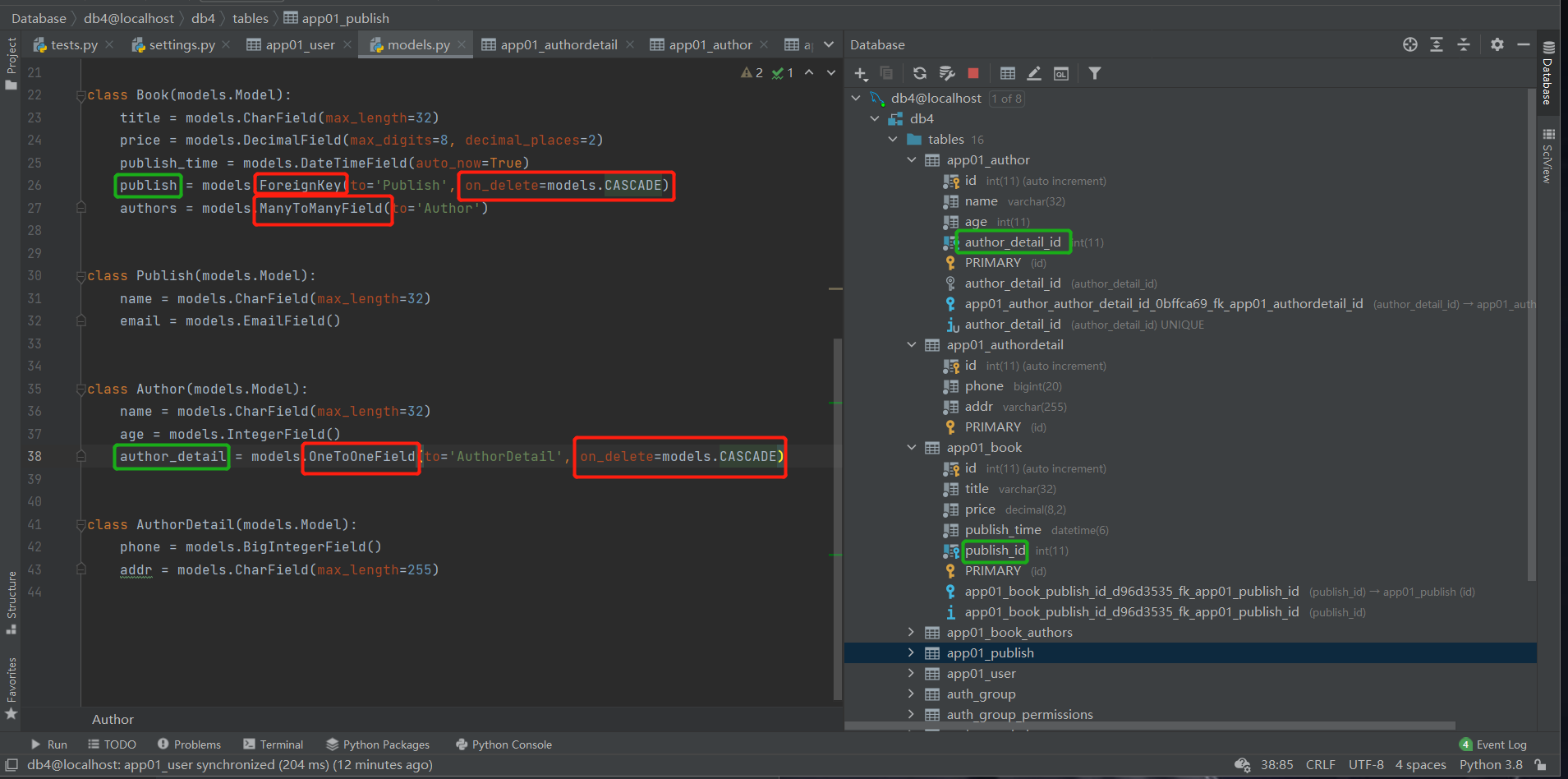
六、外键字段数据操作
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
方式1:直接给实际字段添加关联数据值:
publish_id = 1
方式2:间接使用外键虚拟字段添加数据对象:
一对一:author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
多对多:authors = models.ManyToManyField(to='Author')
# 添加book的数据值
models.Book.objects.create(title='小鞠带你环游世界', price=88.88, publish_id=1)
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.create(title='小鞠的白日梦初级', price=56.66, publish=publish_obj)
models.Book.objects.create(title='小鞠的白日梦中级', price=56.66, publish=publish_obj)
add():添加数据,括号内可以填写数字值也可以填写数据对象,支持多个
# 将书和作者关系表,需要操作第三张表,第三张是虚拟表
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(1) # 朝第三张表添加数据
book_obj.authors.add(2,3) # 朝第三张表添加数据
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj)
book_obj.authors.add(author_obj,author_obj1)
remove():删除数据,括号内可以填写数字值也可以填写数据对象,支持多个
book_obj = models.Book.objects.filter(pk=1).first()
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
book_obj.authors.remove(1)
book_obj.authors.remove(2,3)
book_obj.authors.remove(author_obj)
book_obj.authors.remove(author_obj,author_obj1)
set():修改数据,括号内必须是可迭代对象( (,)、[,]),本质是先删除数据再添加数据
book_obj = models.Book.objects.filter(pk=1).first()
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
book_obj.authors.set([2,])
book_obj.authors.set([2,3])
book_obj.authors.set([author_obj,])
book_obj.authors.set([author_obj,author_obj1])
clear():清空指定数据,括号内不需要任何参数
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.clear()
七、正反向概念
正反向的概念核心在于外键字段在哪张表中
正向查询:通过A表的条件查询B表中的数据,外键字段在A表中
反向查询:通过B表的条件查询A表中的数据,外键字段在A表中
ORM跨表查询口诀>>>:正向查询按外键字段
反向查询按表名小写
八、基于对象的跨表查询(子查询)
# 1.查询主键为1的数据对应的出版社名称
# 1.1先根据条件查询数据对象(先查询书籍对象)
book_obj = models.Book.objects.filter(pk=1).first()
# 1.2以对象为基准
print(book_obj.publish) # 出版社对象:清华出版社
# 2.查询主键为3的书籍对应的作者
# 2.1先根据条件查询数据对象(先查书籍对象)
book_obj = models.Book.objects.filter(pk=3).first()
# 2.2以对象为基准,思考正反向概念(书查作者,外键在书表中,所以是正向查询)
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all()) # <QuerySet [<Author: 作者对象:xj>, <Author: 作者对象:zxr>]>
# 3.查询jason的作者详情
# 3.1先根据条件查询数据对象
author_obj = models.Author.objects.filter(name='xj').first()
# 3.2以对象为基准,思考正反向概念(作者表查作者详情表,外键在作者表,所以正向查询)
print(author_obj.author_detail) # 作者详情对象:18856082140
# 4.查询清华出版社出版的书籍
# 4.1先根据条件查询数据对象
publish_obj = models.Publish.objects.filter(name='清华出版社').first()
# 4.2以对象为基准,思考正反向概念(出版社表查询书籍表,外键在书籍表,所以是反向查询)
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all()) # <QuerySet [<Book: 书籍对象:小鞠带你环游世界>, <Book: 书籍对象:小鞠的白日梦初级>, <Book: 书籍对象:小鞠的白日梦中级>, <Book: 书籍对象:小鞠的白日梦终级>]>
# 5.查询xj写过的书
# 5.1先根据条件查询数据对象
author_obj = models.Author.objects.filter(name='xj').first()
# 5.2以对象为基准,思考正反向概念(作者表查询书籍表,外键在书籍表,所以是反向查询)
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all()) # <QuerySet [<Book: 书籍对象:小鞠的白日梦中级>]>
# 6.查询电话是18856082140的作者
# 6.1先根据条件查询数据对象
author_detail_obj = models.AuthorDetail.objects.filter(phone='18856082140').first()
# 6.2以对象为基准,思考正反向概念(作者详情表查询作者表,外键在作者表,所以是反向查询)
print(author_detail_obj.author) # 作者对象:xj
九、基于双下划线的跨表查询(连表操作)
'''基于双下划线的正向跨表查询'''
# 1.查询主键为1的书籍对应的出版社名称及书名
res = models.Book.objects.filter(pk=1).values('publish__name','title')
print(res) # <QuerySet [{'publish__name': '清华出版社', 'title': '小鞠带你环游世界'}]>
# 2.查询主键为3的书籍对应的作者姓名及书名
res = models.Book.objects.filter(pk=3).values('authors__name','title')
print(res)
# 3.查询xj的作者的电话号码和地址
res = models.Author.objects.filter(name='xj').values('author_detail__phone','author_detail__addr')
print(res) # <QuerySet [{'author_detail__phone': 18856082140, 'author_detail__addr': '安徽池州'}]>
'''基于双下划线的反向跨表查询'''
# 4.查询清华出版社出版的书籍名称和价格
res = models.Publish.objects.filter(name='清华出版社').values('book__title','book__price')
print(res) # <QuerySet [{'book__title': '小鞠带你环游世界', 'book__price': Decimal('88.88')}, {'book__title': '小鞠的白日梦初级', 'book__price': Decimal('56.66')}, {'book__title': '小鞠的白日梦中级', 'book__price': Decimal('56.66')}, {'book__title': '小鞠的白日梦终级', 'book__price': Decimal('56.66')}]>
# 5.查询xj写过的书的名称和日期
res = models.Author.objects.filter(name='xj').values('book__title','book__publish_time')
print(res) # <QuerySet [{'book__title': '小鞠的白日梦中级', 'book__publish_time': datetime.datetime(2022, 9, 5, 13, 15, 28, 483591, tzinfo=<UTC>)}]>
# 6.查询电话是18856082140的作者姓名和年龄
res = models.AuthorDetail.objects.filter(phone=18856082140).values('author__name','author__age')
print(res) # <QuerySet [{'author__name': 'xj', 'author__age': 28}]>
小结:
当表与表之间的关系是一对多或者多对多时,那么需要使用.all()查询,否则查询结果为None
当表与表之间的关系是一对多或者多对赌且子查询是反向概念时,需要使用: 对象.表名小写_set.all()
当表与表之间的关系是一对一,正向概念是外键字段,反向概念就是表名小写


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用