
分布式系统 掌握要点
1. 从集中式到分布式
2. 分布式Session
服务一般分为有状态和无状态,而分布式sessoion就是针对有状态的服务。
分布式Session的几种实现方式
- 基于数据库的Session共享
- 基于resin/tomcat web容器本身的session复制机制
- 基于oscache/Redis/memcached 进行 session 共享。
- 基于cookie 进行session共享
2.1 Session复制
Session Replication 方式管理 (即session复制)
简介:将一台机器上的Session数据广播复制到集群中其余机器上
使用场景:机器较少,网络流量较小
优点:实现简单、配置较少、当网络中有机器Down掉时不影响用户访问
缺点:广播式复制到其余机器有一定廷时,带来一定网络开销
2.2 Session绑定
Session Sticky 方式管理
简介:即粘性Session、当用户访问集群中某台机器后,强制指定后续所有请求均落到此机器上
使用场景:机器数适中、对稳定性要求不是非常苛刻
优点:实现简单、配置方便、没有额外网络开销
缺点:网络中有机器Down掉时、用户Session会丢失、容易造成单点故障
2.3 Session服务器(靠谱)
缓存集中式管理
简介:将Session存入分布式缓存集群中的某台机器上,当用户访问不同节点时先从缓存中拿Session信息
使用场景:集群中机器数多、网络环境复杂
优点:可靠性好
缺点:实现复杂、稳定性依赖于缓存的稳定性、Session信息放入缓存时要有合理的策略写入
目前生产中使用到的
- 基于tomcat配置实现的MemCache缓存管理session实现(麻烦)
- 基于OsCache和shiro组播的方式实现(网络影响)
- 基于spring-session+redis实现的(最适合)
3. 分布式缓存
3.1 Redis
3.2 一致性hash
4. 数据库
4.1 读写分离
MySql主从配置,读写分离并引入中间件,开源的MyCat,阿里的DRDS都是不错的选择。
如果是对高可用要求比较高,但是又没有相应的技术保障,建议使用阿里云的RDS或者Redis相关数据库,省事省力又省钱。
4.1.1 主从热备
4.2 分库
4.3 分表
5. 一致性
5.1 分布式事务
5.1.1 CAP
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性), 好的响应性能
Partition tolerance(分区容错性) 可靠性
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
忠告:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
关系数据库的ACID模型拥有 高一致性 + 可用性 很难进行分区:
Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
Consistency一致性. 在事务开始或结束时,数据库应该在一致状态。
Isolation隔离层. 事务将假定只有它自己在操作数据库,彼此不知晓。
Durability. 一旦事务完成,就不能返回。
跨数据库事务:2PC (two-phase commit), 2PC is the anti-scalability pattern (Pat Helland) 是反可伸缩模式的,JavaEE中的JTA事务可以支持2PC。因为2PC是反模式,尽量不要使用2PC,使用BASE来回避。
5.1.2 BASE
BASE模型反ACID模型,完全不同ACID模型,牺牲高一致性,获得可用性或可靠性:
Basically Available基本可用。支持分区失败(e.g. sharding碎片划分数据库)
Soft state软状态 状态可以有一段时间不同步,异步。
Eventually consistent最终一致,最终数据是一致的就可以了,而不是时时高一致。
BASE思想的主要实现有
1.按功能划分数据库
2.sharding碎片
BASE思想主要强调基本的可用性,如果你需要High 可用性,也就是纯粹的高性能,那么就要以一致性或容错性为牺牲,BASE思想的方案在性能上还是有潜力可挖的。
5.1.3 2PC/3PC
2PC
Two Phase Commitment Protocol
两阶段提交协议
实现分布式事务的关键就是两阶段提交协议。在此协议中,一个或多个资源管理器的活动均由一个称为事务协调器的单独软件组件来控制。此协议中的五个步骤如下:
• 应用程序调用事务协调器中的提交方法。
• 事务协调器将联络事务中涉及的每个资源管理器,并通知它们准备提交事务(这是第一阶段的开始)。
• 为 了以肯定的方式响应准备阶段,资源管理器必须将自己置于以下状态:确保能在被要求提交事务时提交事务,或在被要求回滚事务时回滚事务。大多数资源管理器会 将包含其计划更改的日记文件(或等效文件)写入持久存储区中。如果资源管理器无法准备事务,它会以一个否定响应来回应事务协调器。
• 事务协调器收集来自资源管理器的所有响应。
• 在 第二阶段,事务协调器将事务的结果通知给每个资源管理器。如果任一资源管理器做出否定响应,则事务协调器会将一个回滚命令发送给事务中涉及的所有资源管理 器。如果资源管理器都做出肯定响应,则事务协调器会指示所有的资源管理器提交事务。一旦通知资源管理器提交,此后的事务就不能失败了。通过以肯定的方式响 应第一阶段,每个资源管理器均已确保,如果以后通知它提交事务,则事务不会失败。
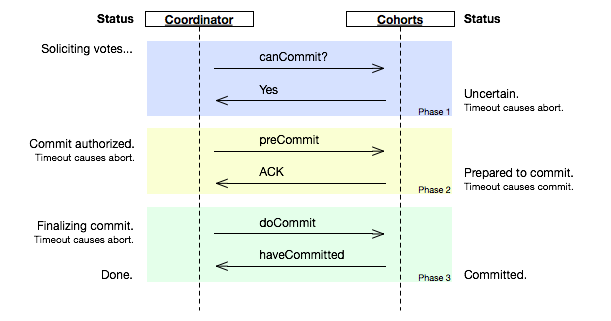
3PC
Three Phase Commitment Protocol
In computer networking and databases, the three-phase commit protocol (3PC) is a distributed algorithm which lets all nodes in a distributed system agree to commit a transaction. Unlike the two-phase commit protocol (2PC) however, 3PC is non-blocking. Specifically, 3PC places an upper bound on the amount of time required before a transaction either commits oraborts. This property ensures that if a given transaction is attempting to commit via 3PC and holds some resource locks, it will release the locks after the timeout.
3PC was originally described by Dale Skeen and Michael Stonebraker in their paper, “A Formal Model of Crash Recovery in a Distributed System”[1]. In that work, they modeled 2PC as a system of non-deterministic finite state automata and proved that it is not resilient to a random single site failure. The basic observation is that in 2PC, while one site is in the “prepared to commit” state, the other may be in either the “commit” or the “abort” state. From this analysis, they developed 3PC to avoid such states and it is thus resilient to such failures.
5.1.4 Paxos
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个「一致性算法」以保证每个节点看到的指令一致。一个通用的一致性算法可以应用在许多场景中,是分布式计算中的重要问题。因此从20世纪80年代起对于一致性算法的研究就没有停止过。节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。Paxos 算法就是一种基于消息传递模型的一致性算法。
5.2 分布式锁
5.2.1 Redisson
redisson是redis官网推荐的java语言实现分布式锁的项目。当然,redisson远不止分布式锁,还包括其他一些分布式结构。详情请移步:https://github.com/mrniko/redisson/wiki
redisson支持4种链接redis的方式:
Cluster(集群)
Sentinel servers(哨兵)
Single server(单机)
6. 负载均衡
- DNS负载均衡,一般域名注册商的dns服务器不支持,但博主用的阿里云解析已经支持
- 四层负载均衡(F5、LVS),工作在TCP协议下
- 七层负载均衡(Nginx、haproxy),工作在Http协议下
6.1 硬件 F5
F5 负载均衡器
数据流量过大的网络中,单一设备无法承担,于是就再回了一台设备用来分担网络的流量,F5负载均衡器就是实现合理的分配网络中的业务流量,使之不至于出现一台设备过忙,一台不能发挥作用。使俩台设备合理的分担网络流量的负担。F5是负载均衡产品的一个品牌,其地位类似于诺基亚在手机品牌中的位置。除了F5以外,Radware、Array、A10、Cisco、深信服等都是负载均衡的牌子,但由于F5在这类产品中影响最大,所以经常说F5负载均衡。
6.2 软件 LVS
在分析 服务器 集群 实现 虚拟网络服务 的相关技术上,LVS集群中实现的三种IP负载均衡技术VS/NAT、VS/TUN、VS/DR的工作原理.
6.2 负载均衡策略
负载均衡策略的优劣及其实现的难易程度有两个关键因素:一、负载均衡算法,二、对网络系统状况的检测方式和能力。
1、rr 轮询调度算法。顾名思义,轮询分发请求。
优点:实现简单
缺点:不考虑每台服务器的处理能力
2、wrr 加权调度算法。我们给每个服务器设置权值weight,负载均衡调度器根据权值调度服务器,服务器被调用的次数跟权值成正比。
优点:考虑了服务器处理能力的不同
3、sh 原地址散列:提取用户IP,根据散列函数得出一个key,再根据静态映射表,查处对应的value,即目标服务器IP。过目标机器超负荷,则返回空。
4、dh 目标地址散列:同上,只是现在提取的是目标地址的IP来做哈希。
优点:以上两种算法的都能实现同一个用户访问同一个服务器。
5、lc 最少连接。优先把请求转发给连接数少的服务器。
优点:使得集群中各个服务器的负载更加均匀。
6、wlc 加权最少连接。在lc的基础上,为每台服务器加上权值。算法为:(活动连接数*256+非活动连接数)÷权重 ,计算出来的值小的服务器优先被选择。
优点:可以根据服务器的能力分配请求。
7、sed 最短期望延迟。其实sed跟wlc类似,区别是不考虑非活动连接数。算法为:(活动连接数+1)*256÷权重,同样计算出来的值小的服务器优先被选择。
8、nq 永不排队。改进的sed算法。我们想一下什么情况下才能“永不排队”,那就是服务器的连接数为0的时候,那么假如有服务器连接数为0,均衡器直接把请求转发给它,无需经过sed的计算。
9、LBLC 基于局部性的最少连接。均衡器根据请求的目的IP地址,找出该IP地址最近被使用的服务器,把请求转发之,若该服务器超载,最采用最少连接数算法。
10、LBLCR 带复制的基于局部性的最少连接。均衡器根据请求的目的IP地址,找出该IP地址最近使用的“服务器组”,注意,并不是具体某个服务器,然后采用最少连接数从该组中挑出具体的某台服务器出来,把请求转发之。若该服务器超载,那么根据最少连接数算法,在集群的非本服务器组的服务器中,找出一台服务器出来,加入本服务器组,然后把请求转发之。
7. 消息队列
“消息队列”是在消息的传输过程中保存消息的容器。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ等等。
消息队列的主要特点是异步处理,主要目的是减少请求响应时间和解耦。所以主要的使用场景就是将比较耗时而且不需要即时(同步)返回结果的操作作为消息放入消息队列。同时由于使用了消息队列,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响,即解耦和。
7.1 RabbitMQ
RabbitMQ是一个在AMQP基础上完成的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
7.2 ZeroMQ
ZMQ (以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个 socket library,他使得 Socket 编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ 的明确目标是“成为标准网络协议栈的一部分,之后进入 Linux 内核”。现在还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD 套接字之上的一层封装。ZMQ 让编写高性能网络应用程序极为简单和有趣。
7.3 ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
7.4 Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
8. 服务化
8.1 服务注册于发现 Zookeeper
8.2 架构
8.2.1 微服务
8.2.1.1 Spring Boot
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。用我的话来理解,就是spring boot其实不是什么新的框架,它默认配置了很多框架的使用方式,就像maven整合了所有的jar包,spring boot整合了所有的框架(不知道这样比喻是否合适)。
Spring Boot可以轻松创建可以“运行”的独立的,生产级的基于Spring的应用程序。我们对Spring平台和第三方图书馆有一个看法,所以你可以从最开始的时候开始。大多数Spring Boot应用程序需要很少的Spring配置。
特征:
- 创建独立的Spring应用程序
- 直接嵌入Tomcat,Jetty或Undertow(不需要部署WAR文件)
- 提供有意思的“启动”POM来简化您的Maven配置
- 尽可能自动配置弹簧
- 提供生产就绪功能,如指标,运行状况检查和外部化配置
- 绝对没有代码生成,也不需要XML配置
8.2.1.2 Dubbo
是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。 其核心部分包含:
- 远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
- 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持
- 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
8.2.2 RPC
RPC(Remote Procedure Call Protocol)——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。RPC采用客户机、服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。有多种RPC模式和执行。最初由Sun公司提出。IETF ONC宪章重新修订了Sun版本,使得ONC RPC协议成为IETF标准协议。现在使用最普遍的模式和执行是开放式软件基础的分布式计算环境(DCE)。
8.2.3 SOA
面向服务的架构(Service-Oriented Architecture)
是一个组件模型,它将应用程序的不同功能单元(称为服务)通过这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
9. 虚拟化 Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
10. 计算平台
10.1 实时
10.1.1 Apache Storm
Apache Storm 是一个免费的开源分布式实时计算系统。
Storm可以轻松地可靠地处理无限数据流,实时处理Hadoop进行批处理。Storm很简单,可以使用任何编程语言,而且使用起来很有趣!
Storm有很多用例:实时分析,在线机器学习,连续计算,分布式RPC,ETL等。Storm很快:一个基准点在每个节点每秒处理超过一百万个元组。它是可扩展的,容错的,保证您的数据将被处理,并且易于设置和操作。
Storm与您已经使用的排队和数据库技术相结合。Storm拓扑消耗数据流并以任意复杂的方式处理这些流,重新分配计算的每个阶段之间的流,但需要。阅读更多的教程。
10.2 离线
在规则,模型上线之前,在离线的环境里面进行仿真验证,来对规则和模型进行效能的评估,避免人为因素造成不准确性从而造成的资损。起初为了达到这个目的,离线计算平台就这样孕育而生了
11. 容灾、异地多活

 浙公网安备 33010602011771号
浙公网安备 33010602011771号