

分布式理论(一)CAP 理论
分布式理论(一) CAP理论
一.CAP理论前言
CAP原则又称为CAP理论,主要思想是在任何一个分布式系统中都无法同时满足CAP。
C(Consistency):表示一致性,所有的节点同一时间看到的是相同的数据。
A(Avaliablity):表示可用性,不管是否成功,确保一个请求都能接收到响应。
P(Partion Tolerance):分区容错性,系统任意分区后,在网络故障时,仍能操作。
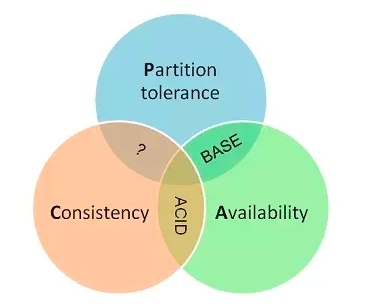
如上所述,正如Gilbert认为,一致性其实就是关系型数据库所讲的ACID,一个用户请求要么是成功,要么是失败的,不能有处于一个中间状态;一旦一个事务完成,将来所有事务都必须基于这个完成后的状态;未完成的事务不会互相影响;一旦一个事务完成,就是持戒的。可用性其实就是对于一个系统而言,所有的请求都应该“成功”并且收到“响应”。分区容错性其实就是指分布式系统的容错性,一个节点出现了故障,不影响整个集群的正常使用。
二.CAP理论介绍
如图,在一个网络中,N1和N2即分布式系统中的两个节点,他们都共享数据块V,其中有一个值是为V0。
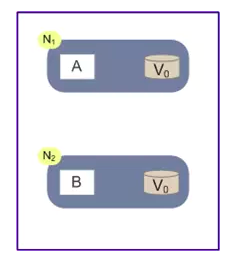
l 在满足一致性的时候,A中的V0应该和B中的V0保持一致的,即V0=V0
l 在满足可用性的时候,无论请求访问A或者是B都应该得到响应。
l 在满足分区可用性的时候,A和B随便一个出现宕机或者网络不通的情况下,都不应该影响整个系统的可用性。
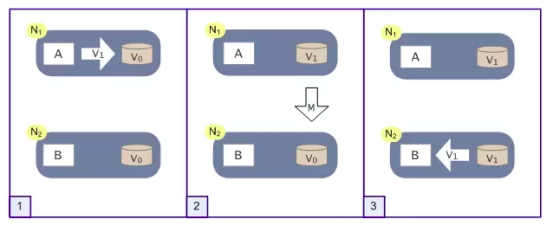
上述描述如果A程序更新V0值为V1,然后在更新B上的副本为V1,当一个请求访问B时,得到的结果是V1。如下图所示:
但是分布式系统中,有些时候这些并不能按照你想的这样进行,在分布式系统中通常情况下网络是分区的,如果出现了网络延迟,导致N1上更新的消息无法到达N2上,即N2上的数据副本依然是V0,当一个请求访问B时,获取到的结果是V0,而访问A时,获取到的结果是V1,这就导致了在用户看来是同一个请求,得到的结果是不一样的。如下图
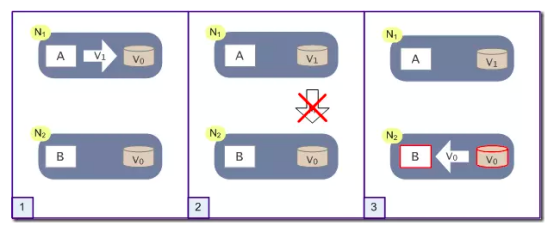
在这个时候,方案的设计者就应该在这里做出两种选择:
(1)牺牲数据一致性,保证可用性。响应旧的数据V0给用户。
(2)牺牲可用性,保证数据一致性。阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1
三.CAP之间取舍
接下来我们就谈一谈CAP,这三者之间是如何取舍的:
(1)CA without P
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
常见模型例子:
单站点数据库;集群数据库等,网上找的还有:LDAP协议,xFS文件系统
实现方式:
两阶段提交;缓存验证协议
(2) CP without A
如果不要求A(可用),相当于每个请求都需要在节点之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式,以及Zookeeper等中间件
常见模型例子:
分布式数据库;分布式锁;大部分的协议;Zookeeper
实现方式:
悲观锁;少数分区不可用
(3) AP wihtout C
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于。
常见模型例子:
Web缓存;DNS;NoSQL;
实现方式:
到期或者租赁;解决冲突;乐观锁
CAP的意义:
在系统架构时,应该根据具体的业务场景来权衡CAP,就拿大多数的门户网站来说,因为机器数量庞大,部署节点分散,网络故障时常态,可用性是必须要保证的,所以在设计的时候就会考虑舍弃一些一致性而选择AP模型。但是对于数据一致性较高的银行系统来说,可以用于系统临时不可用,但是数据必须要保持一致来说,选择CP模型无可厚非。

