和朱晔一起复习Java并发(五):并发容器和同步器
和朱晔一起复习Java并发(五):并发容器和同步器
本节我们先会来复习一下java.util.concurrent下面的一些并发容器,然后再会来简单看一下各种同步器。
ConcurrentHashMap和ConcurrentSkipListMap的性能
首先,我们来测试一下ConcurrentHashMap和ConcurrentSkipListMap的性能。
前者对应的非并发版本是HashMap,后者是跳表实现,Map按照Key顺序排序(当然也可以提供一个Comparator进行排序)。
在这个例子里,我们不是简单的测试Map读写Key的性能,而是实现一个多线程环境下使用Map最最常见的场景:统计Key出现频次,我们的Key的范围是1万个,然后循环1亿次(也就是Value平均也在1万左右),10个并发来操作Map:
@Slf4j
public class ConcurrentMapTest {
int loopCount = 100000000;
int threadCount = 10;
int itemCount = 10000;
@Test
public void test() throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("hashmap");
normal();
stopWatch.stop();
stopWatch.start("concurrentHashMap");
concurrent();
stopWatch.stop();
stopWatch.start("concurrentSkipListMap");
concurrentSkipListMap();
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
private void normal() throws InterruptedException {
HashMap<String, Long> freqs = new HashMap<>();
ForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, loopCount).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(itemCount);
synchronized (freqs) {
if (freqs.containsKey(key)) {
freqs.put(key, freqs.get(key) + 1);
} else {
freqs.put(key, 1L);
}
}
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//log.debug("normal:{}", freqs);
}
private void concurrent() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>(itemCount);
ForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, loopCount).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(itemCount);
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//log.debug("concurrentHashMap:{}", freqs);
}
private void concurrentSkipListMap() throws InterruptedException {
ConcurrentSkipListMap<String, LongAdder> freqs = new ConcurrentSkipListMap<>();
ForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, loopCount).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(itemCount);
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//log.debug("concurrentSkipListMap:{}", freqs);
}
}
这里可以看到,这里的三种实现:
- 对于normal的实现,我们全程锁住了HashMap然后进行读写
- 对于ConcurrentHashMap,我们巧妙利用了一个computeIfAbsent()方法,实现了判断Key是否存在,计算获取Value,put Key Value三步操作,得到一个Value是LongAdder(),然后因为LongAdder是线程安全的所以直接调用了increase()方法,一行代码实现了5行代码效果
- ConcurrentSkipListMap也是一样
运行结果如下:
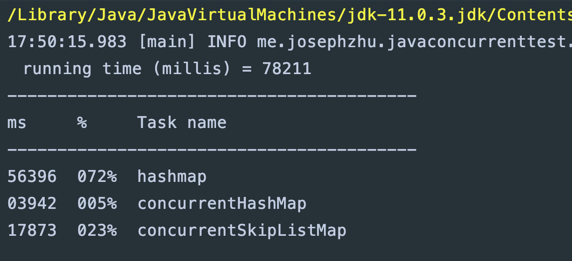
可以看到我们利用ConcurrentHashMap巧妙实现的并发词频统计功能,其性能相比有锁的版本高了太多。
值得注意的是,ConcurrentSkipListMap的containsKey、get、put、remove等类似操作时间复杂度是log(n),加上其有序性,所以性能和ConcurrentHashMap有差距。
如果我们打印一下ConcurrentSkipListMap最后的结果,差不多是这样的:
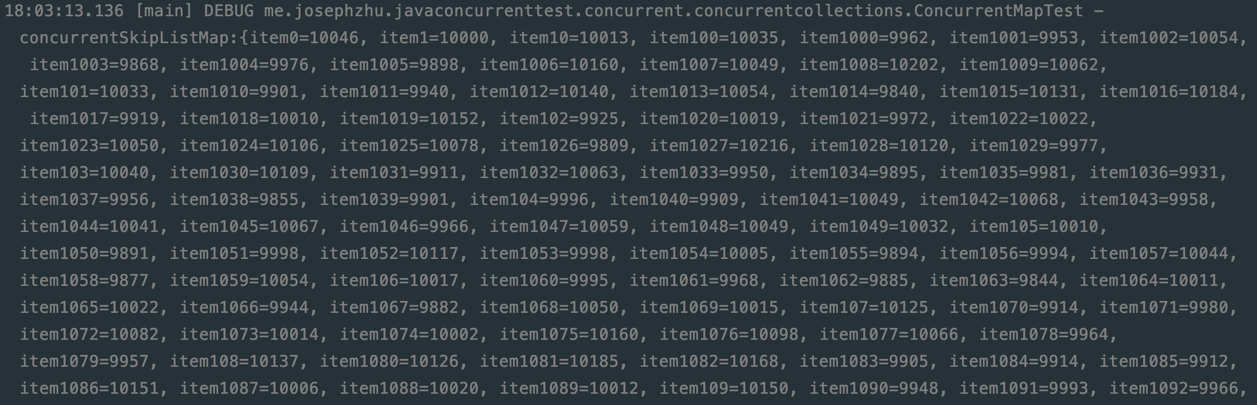
可以看到Entry按照了Key进行排序。
ConcurrentHashMap的那些原子操作方法
这一节我们比较一下computeIfAbsent()和putIfAbsent()的区别,这2个方法很容易因为误用导致一些Bug。
- 第一个是性能上的区别,如果Key存在的话,computeIfAbsent因为传入的是一个函数,函数压根就不会执行,而putIfAbsent需要直接传值。所以如果要获得Value代价很大的话,computeIfAbsent性能会好
- 第二个是使用上的区别,computeIfAbsent返回是的是操作后的值,如果之前值不存在的话就返回计算后的值,如果本来就存在那么就返回本来存在的值,putIfAbsent返回的是之前的值,如果原来值不存在那么会得到null
写一个程序来验证一下:
@Slf4j
public class PutIfAbsentTest {
@Test
public void test() {
ConcurrentHashMap<String, String> concurrentHashMap = new ConcurrentHashMap<>();
log.info("Start");
log.info("putIfAbsent:{}", concurrentHashMap.putIfAbsent("test1", getValue()));
log.info("computeIfAbsent:{}", concurrentHashMap.computeIfAbsent("test1", k -> getValue()));
log.info("putIfAbsent again:{}", concurrentHashMap.putIfAbsent("test2", getValue()));
log.info("computeIfAbsent again:{}", concurrentHashMap.computeIfAbsent("test2", k -> getValue()));
}
private String getValue() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return UUID.randomUUID().toString();
}
}
在这里获取值的操作需要1s,从运行结果可以看到,第二次值已经存在的时候,putIfAbsent还耗时1s,而computeIfAbsent不是,而且还可以看到第一次值不存在的时候putIfAbsent返回了null,而computeIfAbsent返回了计算后的值:
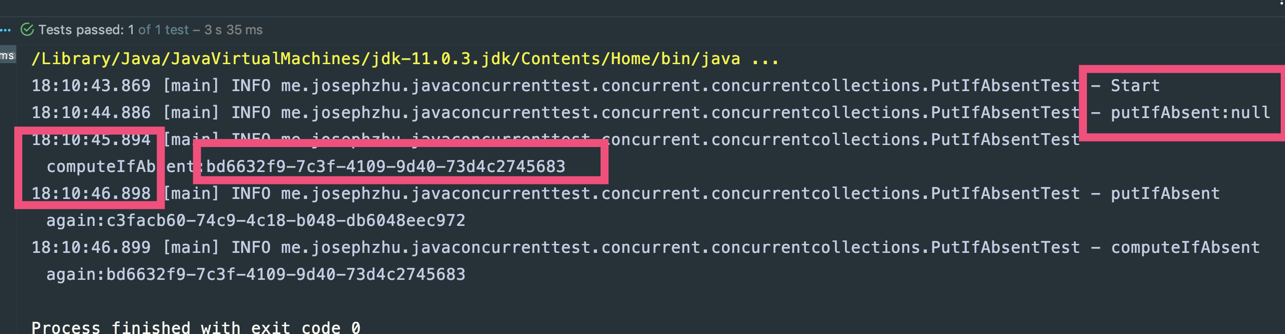
使用的时候一定需要根据自己的需求来使用合适的方法。
ThreadLocalRandom的误用
之前的例子里我们用到了ThreadLocalRandom,这里简单提一下ThreadLocalRandom可能的误用:
@Slf4j
public class ThreadLocalRandomMisuse {
@Test
public void test() throws InterruptedException {
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
IntStream.rangeClosed(1, 5)
.mapToObj(i -> new Thread(() -> log.info("wrong:{}", threadLocalRandom.nextInt())))
.forEach(Thread::start);
IntStream.rangeClosed(1, 5)
.mapToObj(i -> new Thread(() -> log.info("ok:{}", ThreadLocalRandom.current().nextInt())))
.forEach(Thread::start);
TimeUnit.SECONDS.sleep(1);
}
}
一句话而言,我们应该每次都ThreadLocalRandom.current().nextInt()这样用而不是实例化了ThreadLocalRandom.current()每次调用nextInt()。观察一下两次输出可以发现,wrong的那5次得到的随机数都是一样的:
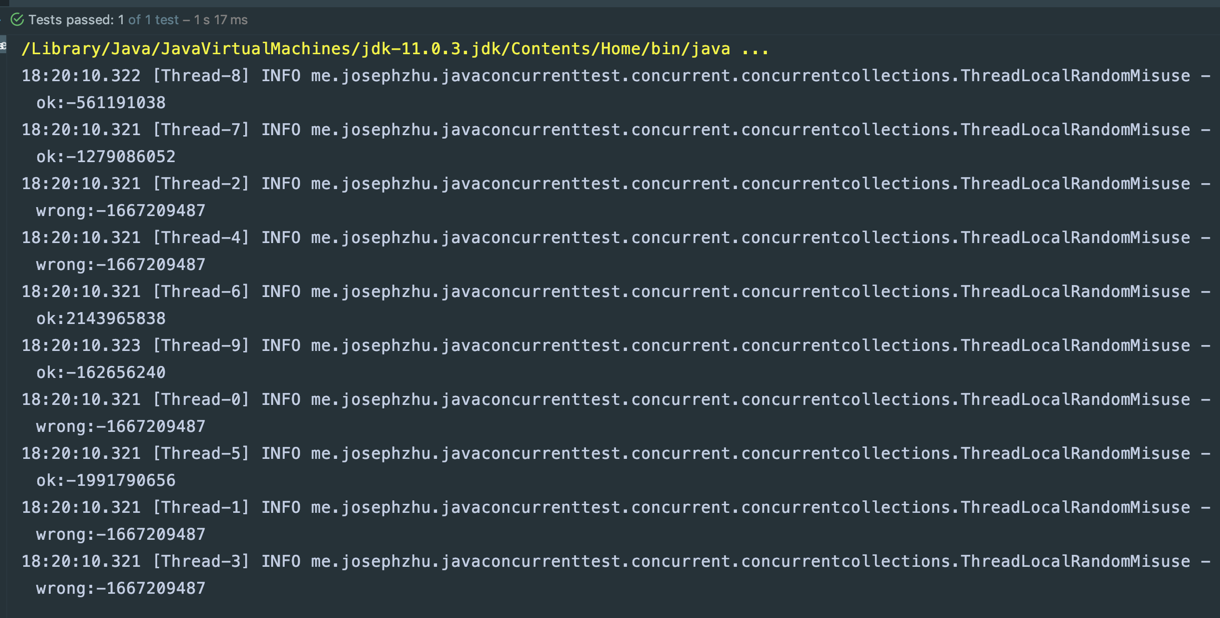
ConcurrentHashMap的并发reduce功能测试
ConcurrentHashMap提供了比较高级的一些方法可以进行并发的归并操作,我们写一段程序比较一下使用遍历方式以及使用reduceEntriesToLong()统计ConcurrentHashMap中所有值的平均数的性能和写法上的差异:
@Slf4j
public class ConcurrentHashMapReduceTest {
int loopCount = 100;
int itemCount = 10000000;
@Test
public void test() {
ConcurrentHashMap<String, Long> concurrentHashMap = LongStream.rangeClosed(1, itemCount)
.boxed()
.collect(Collectors.toMap(i -> "item" + i, Function.identity(),(o1, o2) -> o1, ConcurrentHashMap::new));
StopWatch stopWatch = new StopWatch();
stopWatch.start("normal");
normal(concurrentHashMap);
stopWatch.stop();
stopWatch.start("concurrent with parallelismThreshold=1");
concurrent(concurrentHashMap, 1);
stopWatch.stop();
stopWatch.start("concurrent with parallelismThreshold=max long");
concurrent(concurrentHashMap, Long.MAX_VALUE);
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
private void normal(ConcurrentHashMap<String, Long> map) {
IntStream.rangeClosed(1, loopCount).forEach(__ -> {
long sum = 0L;
for (Map.Entry<String, Long> item : map.entrySet()) {
sum += item.getValue();
}
double average = sum / map.size();
Assert.assertEquals(itemCount / 2, average, 0);
});
}
private void concurrent(ConcurrentHashMap<String, Long> map, long parallelismThreshold) {
IntStream.rangeClosed(1, loopCount).forEach(__ -> {
double average = map.reduceEntriesToLong(parallelismThreshold, Map.Entry::getValue, 0, Long::sum) / map.size();
Assert.assertEquals(itemCount / 2, average, 0);
});
}
}
执行结果如下:
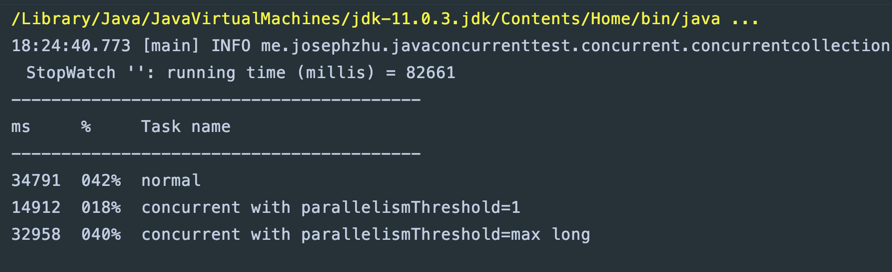
可以看到并行归并操作对于比较大的HashMap性能好不少,注意一点是传入的parallelismThreshold不是并行度(不是ForkJoinPool(int parallelism)的那个parallelism)的意思,而是并行元素的阈值,传入Long.MAX_VALUE取消并行,传入1充分利用ForkJoinPool。
当然,我们这里只演示了reduceEntriesToLong()一个方法,ConcurrentHashMap还有十几种各种reduceXXX()用于对Key、Value和Entry进行并行归并操作。
ConcurrentHashMap的误用
其实这里想说的之前的文章中也提到过,ConcurrentHashMap不能确保多个针对Map的操作是原子性的(除非是之前提到computeIfAbsent()和putIfAbsent()等等),比如在下面的例子里,我们有一个9990大小的ConcurrentHashMap,有多个线程在计算它离10000满员还有多少差距,然后填充差距:
@Test
public void test() throws InterruptedException {
int limit = 10000;
ConcurrentHashMap<String, Long> concurrentHashMap = LongStream.rangeClosed(1, limit - 10)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1, o2) -> o1, ConcurrentHashMap::new));
log.info("init size:{}", concurrentHashMap.size());
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int __ = 0; __ < 10; __++) {
executorService.execute(() -> {
int gap = limit - concurrentHashMap.size();
log.debug("gap:{}", gap);
concurrentHashMap.putAll(LongStream.rangeClosed(1, gap)
.boxed()
.collect(Collectors.toMap(i -> UUID.randomUUID().toString(), Function.identity())));
});
}
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
log.info("finish size:{}", concurrentHashMap.size());
}
这段代码显然是有问题的:
- 第一,诸如size()、containsValue()等(聚合状态的)方法仅仅在没有并发更新的时候是准确的,否则只能作为统计、监控来使用,不能用于控制程序运行逻辑
- 第二,即使size()是准确的,在计算出gap之后其它线程可能已经往里面添加数据了,虽然putAll()操作这一操作是线程安全的,但是这个这个计算gap,填补gap的逻辑并不是原子性的,不是说用了ConcurrentHashMap就不需要锁了
输出结果如下:
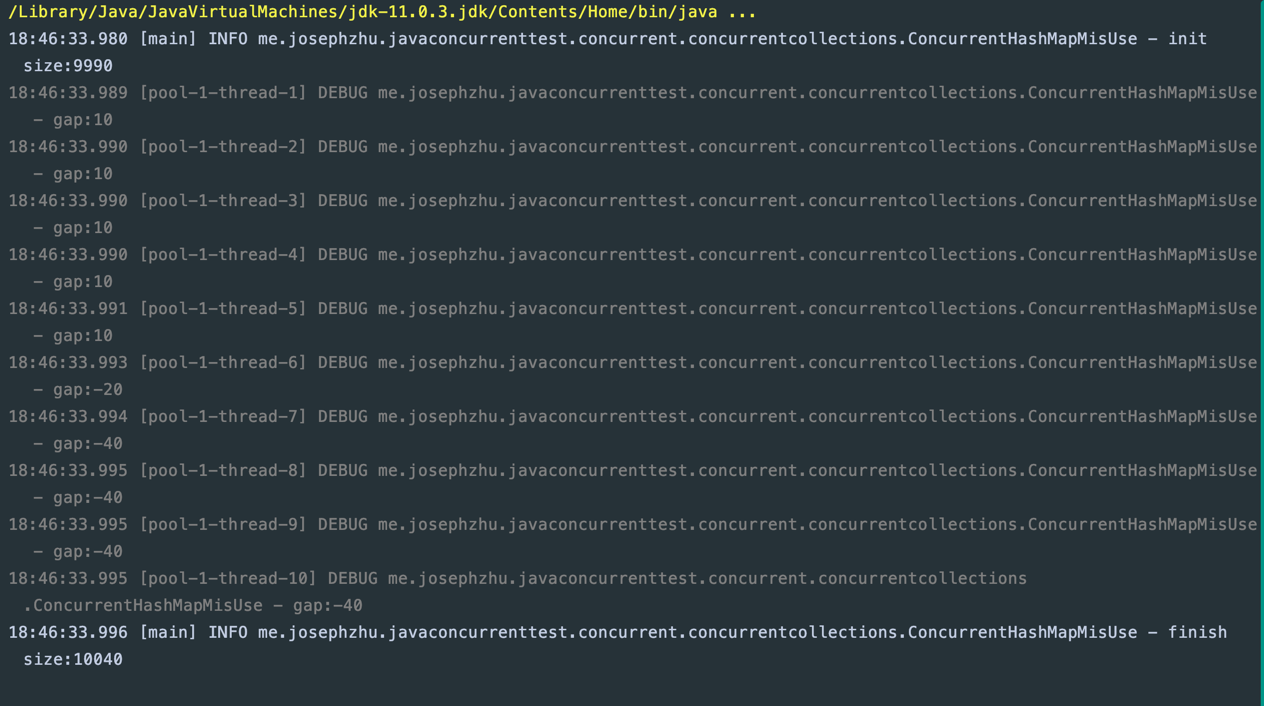
可以看到,有一些线程甚至计算出了负数的gap,最后结果是10040,比预期的limit多了40。
还有一点算不上误用,只是提一下,ConcurrentHashMap的Key/Value不能是null,而HashMap是可以的,为什么是这样呢?
下图是ConcurrentHashMap作者的回复:

意思就是如果get(key)返回了null,你搞不清楚这到底是key没有呢还是value就是null。非并发情况下你可以使用后contains(key)来判断,但是并发情况下不行,你判断的时候可能Map已经修改了。
CopyOnWriteArrayList测试
CopyOnWrite的意义在于几乎没有什么修改,而读并发超级高的场景,如果有修改,我们重起炉灶复制一份,虽然代价很大,但是这样能让99.9%的并发读实现无锁,我们来试试其性能,先是写的测试,我们比拼一下CopyOnWriteArrayList、手动锁的ArrayList以及synchronizedList包装过的ArrayList:
@Test
public void testWrite() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> arrayList = new ArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount = 100000;
stopWatch.start("copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
stopWatch.start("arrayList");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> {
synchronized (arrayList) {
arrayList.add(ThreadLocalRandom.current().nextInt(loopCount));
}
});
stopWatch.stop();
stopWatch.start("synchronizedList");
IntStream.range(0, loopCount).parallel().forEach(__ -> synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
10万次操作不算多,结果如下:
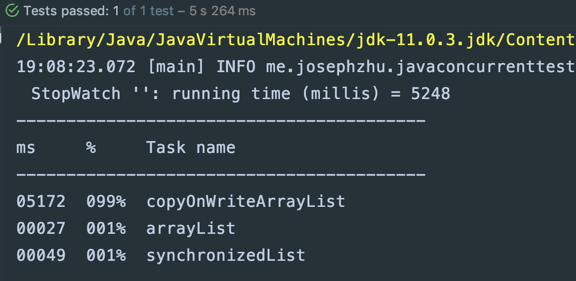
可见CopyOnWriteArrayList的修改因为涉及到整个数据的复制,代价相当大。
再来看看读,先使用一个方法来进行1000万数据填充,然后测试,迭代1亿次:
private void addAll(List<Integer> list) {
list.addAll(IntStream.rangeClosed(1, 10000000).boxed().collect(Collectors.toList()));
}
@Test
public void testRead() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> arrayList = new ArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
addAll(copyOnWriteArrayList);
addAll(arrayList);
addAll(synchronizedList);
StopWatch stopWatch = new StopWatch();
int loopCount = 100000000;
int count = arrayList.size();
stopWatch.start("copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
stopWatch.start("arrayList");
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> {
synchronized (arrayList) {
arrayList.get(ThreadLocalRandom.current().nextInt(count));
}
});
stopWatch.stop();
stopWatch.start("synchronizedList");
IntStream.range(0, loopCount).parallel().forEach(__ -> synchronizedList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
执行结果如下:
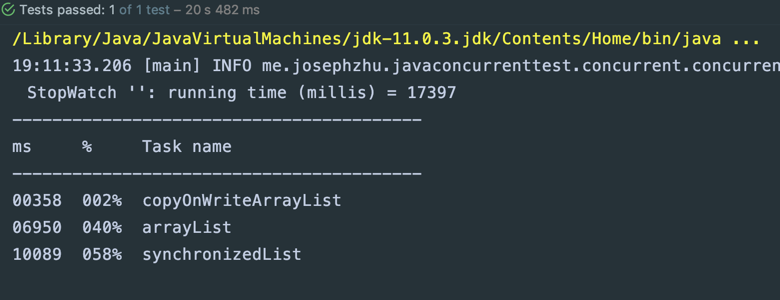
的确没错,CopyOnWriteArrayList性能相当强悍,毕竟读取无锁,想多少并发就多少并发。
看完了大部分的并发容器我们再来看看五种并发同步器。
CountDownLatch测试
CountDownLatch在之前的文章中已经出现过N次了,也是五种并发同步器中使用最最频繁的一种,一般常见的应用场景有:
- 等待N个线程执行完毕
- 就像之前很多次性能测试例子,使用两个CountDownLatch,一个用来让所有线程等待主线程发起命令一起开启,一个用来给主线程等待所有子线程执行完毕
- 异步操作的异步转同步,很多基于异步网络通讯(比如Netty)的RPC框架都使用了CountDownLatch来异步转同步,比如下面取自RocketMQ中Remoting模块的源码片段:
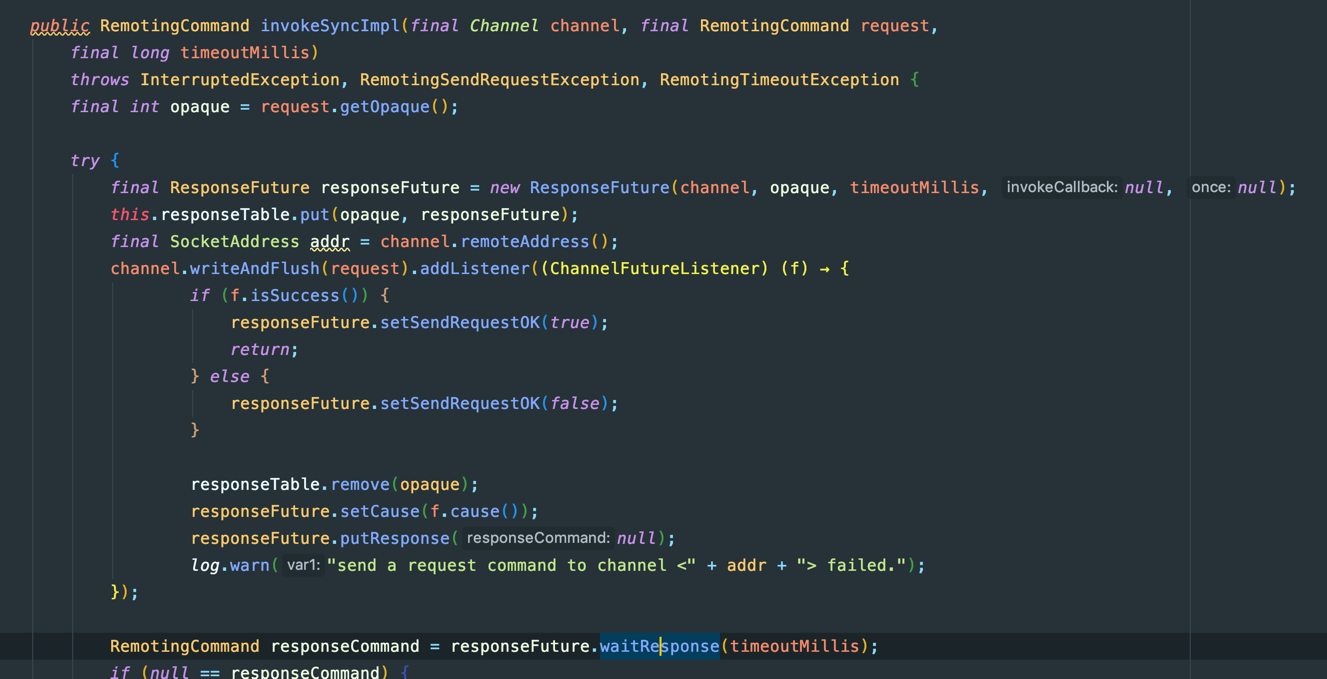
来看看ResponseFuture的相关代码实现:
public class ResponseFuture {
private final int opaque;
private final Channel processChannel;
private final long timeoutMillis;
private final InvokeCallback invokeCallback;
private final long beginTimestamp = System.currentTimeMillis();
private final CountDownLatch countDownLatch = new CountDownLatch(1);
private final SemaphoreReleaseOnlyOnce once;
private final AtomicBoolean executeCallbackOnlyOnce = new AtomicBoolean(false);
private volatile RemotingCommand responseCommand;
private volatile boolean sendRequestOK = true;
private volatile Throwable cause;
...
public RemotingCommand waitResponse(final long timeoutMillis) throws InterruptedException {
this.countDownLatch.await(timeoutMillis, TimeUnit.MILLISECONDS);
return this.responseCommand;
}
public void putResponse(final RemotingCommand responseCommand) {
this.responseCommand = responseCommand;
this.countDownLatch.countDown();
}
...
}
在发出网络请求后,我们等待响应,在收到响应后我们把数据放入后解锁CountDownLatch,然后等待响应的请求就可以继续拿数据。
Semaphore测试
Semaphore可以用来限制并发,假设我们有一个游戏需要限制同时在线的玩家,我们先来定义一个Player类,在这里我们通过传入的Semaphore限制进入玩家的数量。
在代码里,我们通过了之前学习到的AtomicInteger、AtomicLong和LongAdder来统计玩家的总数,最长等待时间和宗等待时长。
@Slf4j
public class Player implements Runnable {
private static AtomicInteger totalPlayer = new AtomicInteger();
private static AtomicLong longestWait = new AtomicLong();
private static LongAdder totalWait = new LongAdder();
private String playerName;
private Semaphore semaphore;
private LocalDateTime enterTime;
public Player(String playerName, Semaphore semaphore) {
this.playerName = playerName;
this.semaphore = semaphore;
}
public static void result() {
log.info("totalPlayer:{},longestWait:{}ms,averageWait:{}ms", totalPlayer.get(), longestWait.get(), totalWait.doubleValue() / totalPlayer.get());
}
@Override
public void run() {
try {
enterTime = LocalDateTime.now();
semaphore.acquire();
totalPlayer.incrementAndGet();
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
long ms = Duration.between(enterTime, LocalDateTime.now()).toMillis();
longestWait.accumulateAndGet(ms, Math::max);
totalWait.add(ms);
//log.debug("Player:{} finished, took:{}ms", playerName, ms);
}
}
}
主测试代码如下:
@Test
public void test() throws InterruptedException {
Semaphore semaphore = new Semaphore(10, false);
ExecutorService threadPool = Executors.newFixedThreadPool(100);
IntStream.rangeClosed(1, 10000).forEach(i -> threadPool.execute(new Player("Player" + i, semaphore)));
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
Player.result();
}
我们限制并发玩家数量为10个,非公平进入,线程池是100个固定线程,总共有10000个玩家需要进行游戏,程序结束后输出如下:

再来试试公平模式:

可以明显看到,开启公平模式后最长等待的那个玩家没有等那么久了,平均等待时间比之前略长,符合预期。
CyclicBarrier测试
CyclicBarrier用来让所有线程彼此等待,等待所有的线程或者说参与方一起到达了汇合点后一起进入下一次等待,不断循环。在所有线程到达了汇合点后可以由最后一个到达的线程做一下『后处理』操作,这个后处理操作可以在声明CyclicBarrier的时候传入,也可以通过判断await()的返回来实现。
这个例子我们实现一个简单的场景,一个演出需要等待3位演员到位才能开始表演,演出需要进行3次。我们通过CyclicBarrier来实现等到所有演员到位,到位后我们的演出需要2秒时间。
@Slf4j
public class CyclicBarrierTest {
@Test
public void test() throws InterruptedException {
int playerCount = 5;
int playCount = 3;
CyclicBarrier cyclicBarrier = new CyclicBarrier(playerCount);
List<Thread> threads = IntStream.rangeClosed(1, playerCount).mapToObj(player->new Thread(()-> IntStream.rangeClosed(1, playCount).forEach(play->{
try {
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current().nextInt(100));
log.debug("Player {} arrived for play {}", player, play);
if (cyclicBarrier.await() ==0) {
log.info("Total players {} arrived, let's play {}", cyclicBarrier.getParties(),play);
TimeUnit.SECONDS.sleep(2);
log.info("Play {} finished",play);
}
} catch (Exception e) {
e.printStackTrace();
}
}))).collect(Collectors.toList());
threads.forEach(Thread::start);
for (Thread thread : threads) {
thread.join();
}
}
}
通过if (cyclicBarrier.await() ==0)可以实现在最后一个演员到位后做冲破栅栏后的后处理操作,我们看下这个演出是不是循环了3次,并且是不是所有演员到位后才开始的:
10:35:43.333 [Thread-4] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 5 arrived for play 1
10:35:43.333 [Thread-1] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 2 arrived for play 1
10:35:43.333 [Thread-3] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 4 arrived for play 1
10:35:43.367 [Thread-2] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 3 arrived for play 1
10:35:43.376 [Thread-0] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 1 arrived for play 1
10:35:43.377 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Total players 5 arrived, let's play 1
10:35:43.378 [Thread-2] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 3 arrived for play 2
10:35:43.432 [Thread-3] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 4 arrived for play 2
10:35:43.434 [Thread-1] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 2 arrived for play 2
10:35:43.473 [Thread-4] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 5 arrived for play 2
10:35:45.382 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Play 1 finished
10:35:45.390 [Thread-0] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 1 arrived for play 2
10:35:45.390 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Total players 5 arrived, let's play 2
10:35:45.437 [Thread-3] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 4 arrived for play 3
10:35:45.443 [Thread-4] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 5 arrived for play 3
10:35:45.445 [Thread-2] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 3 arrived for play 3
10:35:45.467 [Thread-1] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 2 arrived for play 3
10:35:47.395 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Play 2 finished
10:35:47.472 [Thread-0] DEBUG me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Player 1 arrived for play 3
10:35:47.473 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Total players 5 arrived, let's play 3
10:35:49.477 [Thread-0] INFO me.josephzhu.javaconcurrenttest.concurrent.synchronizers.CyclicBarrierTest - Play 3 finished
从这个例子可以看到,我们的演出是在最后到达的Player1演员这个线程上进行的,值得注意的一点是,在他表演的时候其他演员已经又进入了等待状态(不要误认为,CyclicBarrier会让所有线程阻塞,等待后处理完成后再让其它线程继续下一次循环),就等他表演结束后继续来到await()才能又开始新的演出。
Phaser测试
Phaser和Barrier类似,只不过前者更灵活,参与方的人数是可以动态控制的,而不是一开始先确定的。Phaser可以手动通过register()方法注册成为一个参与方,然后通过arriveAndAwaitAdvance()表示自己已经到达,等到其它参与方一起到达后冲破栅栏。
比如下面的代码,我们对所有传入的任务进行iterations次迭代操作。
Phaser终止的条件是大于迭代次数或者没有参与方,onAdvance()返回true表示终止。
我们首先让主线程成为一个参与方,然后让每一个任务也成为参与方,在新的线程中运行任务,运行完成后到达栅栏,只要栅栏没有终止则无限循环。
在主线程上我们同样也是无限循环,每一个阶段都是等待其它线程完成任务后(到达栅栏后),自己再到达栅栏开启下一次任务。
@Slf4j
public class PhaserTest {
AtomicInteger atomicInteger = new AtomicInteger();
@Test
public void test() throws InterruptedException {
int iterations = 10;
int tasks = 100;
runTasks(IntStream.rangeClosed(1, tasks)
.mapToObj(index -> new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
atomicInteger.incrementAndGet();
}))
.collect(Collectors.toList()), iterations);
Assert.assertEquals(tasks * iterations, atomicInteger.get());
}
private void runTasks(List<Runnable> tasks, int iterations) {
Phaser phaser = new Phaser() {
protected boolean onAdvance(int phase, int registeredParties) {
return phase >= iterations - 1 || registeredParties == 0;
}
};
phaser.register();
for (Runnable task : tasks) {
phaser.register();
new Thread(() -> {
do {
task.run();
phaser.arriveAndAwaitAdvance();
} while (!phaser.isTerminated());
}).start();
}
while (!phaser.isTerminated()) {
doPostOperation(phaser);
phaser.arriveAndAwaitAdvance();
}
doPostOperation(phaser);
}
private void doPostOperation(Phaser phaser) {
while (phaser.getArrivedParties() < 100) {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.info("phase:{},registered:{},unarrived:{},arrived:{},result:{}",
phaser.getPhase(),
phaser.getRegisteredParties(),
phaser.getUnarrivedParties(),
phaser.getArrivedParties(), atomicInteger.get());
}
}
10次迭代,每次迭代100个任务,执行一下看看:
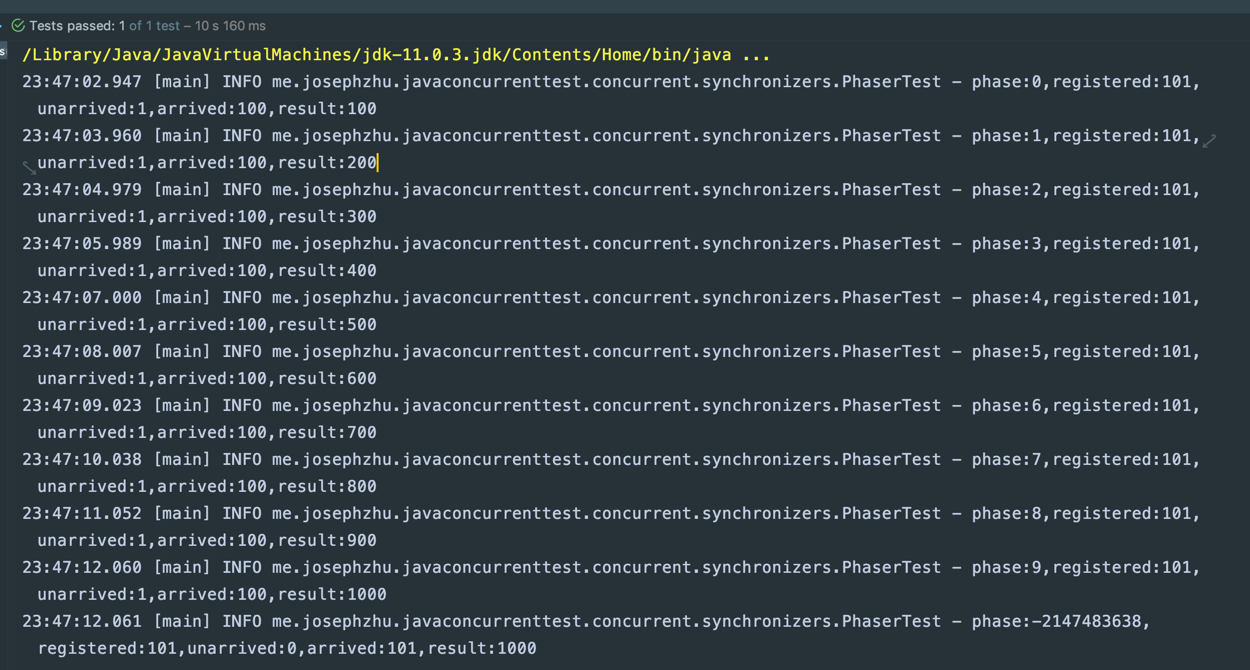
可以看到,主线程的后处理任务的while循环结束后只有它自己没有到达栅栏,这个时候它可以做一些任务后处理工作,完成后冲破栅栏。
Exchanger测试
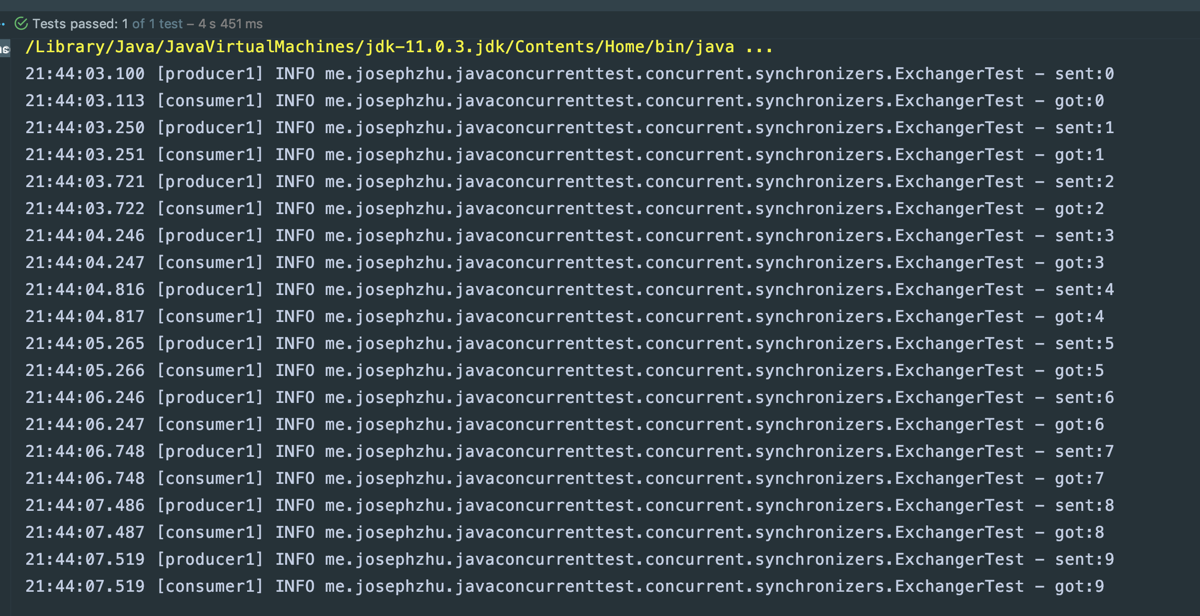
Exchanger实现的效果是两个线程在同一时间(会合点)交换数据,写一段代码测试一下。在下面的代码里,我们定义一个生产者线程不断发送数据,发送数据后休眠时间随机,通过使用Exchanger,消费者线程实现了在生产者发送数据后立刻拿到数据的效果,在这里我们并没有使用阻塞队列来实现:
@Slf4j
public class ExchangerTest {
@Test
public void test() throws InterruptedException {
Random random = new Random();
Exchanger<Integer> exchanger = new Exchanger<>();
int count = 10;
Executors.newFixedThreadPool(1, new ThreadFactoryImpl("producer"))
.execute(() -> {
try {
for (int i = 0; i < count; i++) {
log.info("sent:{}", i);
exchanger.exchange(i);
TimeUnit.MILLISECONDS.sleep(random.nextInt(1000));
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
ExecutorService executorService = Executors.newFixedThreadPool(1, new ThreadFactoryImpl("consumer"));
executorService.execute(() -> {
try {
for (int i = 0; i < count; i++) {
int data = exchanger.exchange(null);
log.info("got:{}", data);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdown();
executorService.awaitTermination(1, TimeUnit.HOURS);
}
}
运行效果如下:
小结
并发容器这块我就不做过多总结了,ConcurrentHashMap实在是太好用太常用,但是务必注意其线程安全的特性并不是说ConcurrentHashMap怎么用都没有问题,错误使用在业务代码中很常见。
现在我们来举个看表演的例子总结一下几种并发同步器:
- Semaphore是限制同时看表演的观众人数,有人走了后新人才能进来看
- CountDownLatch是演职人员人不到齐表演无法开始,演完结束
- CyclicBarrier是演职人员到期了后才能表演,最后一个到的人是导演,导演会主导整个演出,演出完毕后所有演职人员修整后重新等待大家到期
- Phaser是每一场演出的演职人员名单可能随时会更改,但是也是要确保所有演职人员到期后才能开演
同样,代码见我的Github,欢迎clone后自己把玩,欢迎点赞。
欢迎关注我的微信公众号:随缘主人的园子




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?