学习笔记 之 韩顺平老师的MySQL优化教程
一、表的设计
什么样的表才是符合3NF范式?
表的范式,首先是符合1NF,才能满足2NF,进一步才能满足3NF范式。
1NF范式:即表的列具有原子性,不可再分解,即列的信息,不能分解,只有数据库是关系型数据库,就自动满足1NF
2NF范式:表中的记录是唯一的,就满足2NF范式,通常我们设计一个主键来实现。
3NF范式:是对字段冗余性约束,要求字段没有冗余,没有冗余的数据库设计可以做到。
但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留数据冗余(即反三范式)。具体做法是:再概念数据模型设计市遵循第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。比如——在表的一对N情况下,为了提供效率,可能会在1 这表中设计字段,提高速率。

二、慢查询
SQL优化,SQL语句本身的优化。
SQL优化的一般步骤:
- 通过show status命令了解各种SQL的执行频率
- 定位执行效率较低的SQL语句(重点select)
- 通过explain分析低效率的SQL语句的执行情况
- 确定问题并采取相应的优化措施
问题是:如何从一个大项目中,迅速定位执行慢的语句(定位慢查询)?
①首先我们了解MySQL数据库的一些运行状态如何查询(比如想知道当前MySQL运行的时间/一共执行了多少次select,update,delete/当前连接)
show status
常用的:
show status like "uptime";
show status like "conn_select"; show status like "conn_insert"; ...类推 update,delete
show [session|global] status like ...... 如果你不写 [session|global]默认是session会话,只取出当前窗口的执行,如果你想看所有(从mysql启动到现在,则应该global)
show status like "connections";
show status like "show_queries"; 显示慢查询
②如何去定位慢查询
构建一个大表(400万)——>存储过程构建。大表中记录又要求,记录是不同才有用,否则测试效果和真实的相差大。
创建表:
-- 部门表
create table dept(
deptno mediumint unsigned not null default 0, -- 编号
dname varchar(20) not null default "", -- 名称
loc varchar(13) not null default "" -- 地点
)engine=myisam default charset=utf8;
-- 雇员表
create table emp(
empno mediumint unsigned not null default 0, --编号
ename varchar(20) not null default "", -- 名字
job varchar(9) not null default "", -- 工作
mgr mediumint unsigned not null default 0, --上级编号
hiredate date not null, -- 入职时间
sal decimal(7, 2) not null, -- 薪水
comm decimal(7, 2) not null, -- 红利
deptno mediumint unsigned not null default 0 --部门编号
)engine=myisam default charset=utf8;
-- 工资级别表
create table salgrade(
grade mediumint unsigned not null default 0,
losal decimal(7, 2) not null,
hisal decimal(7, 2) not null
)engine=myisam default charset=utf8;
-- 随机产生字符串
-- 定义一个新的命令结束符合delimiter$$
--
测试数据:
insert intio salgrade values(1, 700, 1200);
insert intio salgrade values(2, 1201, 1400);
insert intio salgrade values(3, 1401, 2000);
insert intio salgrade values(4, 2002, 3000);
insert intio salgrade values(5, 3001, 9999);
为了存储过程能够正常执行,我们需要把命令结束符修改:
delimiter $$;
select * from salgrade$$;
# rand_string(n INT) rand_string是函数名 (n INT) //该函数接收一个整数
create function rand_string(n INT)
returns varchar(255) # 该函数会返回一个字符串
# chars_str定义一个变量chars_str,类型是varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str=concat(return_str, substring(chars_str, floor(1+rand()*52), 1));
set i = i + 1;
end while;
return return_str;
end $$
默认情况下,mysql认为10秒才是一个慢查询
修改mysql的慢查询时间:
show variables like "long_query_time"; // 显示当前慢查询时间
set long_query_time=1; // 修改慢查询时间
③如何将慢查询的SQL记录到我们的一个日志中
在默认的情况下,mysql不记录慢查询,需要在启动mysql的时候指定记录慢查询才可以,
bin\mysqld.exe --safe-mode -- slow-query-log
查看慢查询日志:默认数据目录data中的host-name-show.log
三、索引
优化问题
通过explain语句可以分析,mysql如何执行你的SQL语句,
如何添加索引?
四种索引(主键索引、唯一索引、全文索引、普通索引)
1、添加
为什么创建索引后,速度会增加呢?(即原理:BTREE方式检索、二叉树搜索、log2N次数)
添加索引后,查询速度的提升是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的I/O。
1.1主键索引添加
可以在创建表的时候添加或者可以创完表后再添加。
alter table 表名 add primary key(列);
主键字段,不能为null,也不能重复。
1.2 普通索引添加
create index 索引名 on 表名 (列);
1.3 全文索引添加
fulltext索引仅限于myisam,主要针对文字、文本检索,
create table articles(
id int unsigned auto increment not null primary key,
title varchar(200),
body text,
fulltext(title, body)
)engine=myisam charset=utf8;
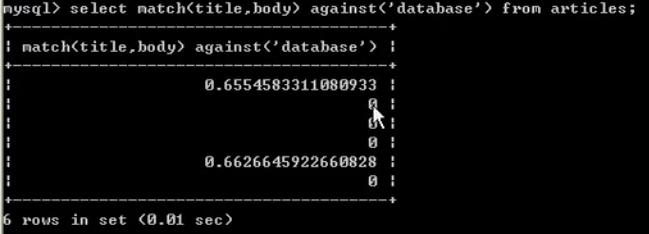
如何使用全文索引?
错误用法:select * from articles where body like "%mysql%"; 不会使用到全文索引
正确用法:select * from articles where match(title, body) against('mysql');
说明:
1. 在mysql中,全文索引只针对myisam 生效
2. mysql自己提供的fulltext 针对英文生效 ——> sphinx(coreseek) | 技术处理中文
3. 使用方法是 match(字段名,...) against('关键字')
-
全文索引有一个叫 停止词 ,因为在一个文本中,创建索引是一个无穷大的数,因此对一些常用词和字符,就不会去创建,这些词,称为停止词
1.4 唯一索引添加
方式一:
当表的某列被指定为unique 约束时,这列就是一个唯一索引
create table ddd(id int primary key not null auto increment, name varchar(32) unique);
此时,name列就是一个唯一索引,字段的值是可以为null,可以有多个null,如果是具体的值,则不能重复。
方式二:
当创建表后,再去创建唯一索引
create table eee(id int primary key auto_increment, name varchar(32) );
create unique index 索引名 on 表名 (字段名);
2、查询
2.1 三种查询方式
desc 表名; -- 缺点:不能显示出索引名称
show index(es) from 表名;
show keys from 表名;
3、删除
drop index 索引名 on 表名;
alter table 表名 drop index 索引名;
如果删除的是主键索引,
alter table 表名 drop primary key;
4、修改
先删除,再重新创建。
5、索引使用注意事项
索引使用的代价
磁盘空间占用
对dml(update, delete, insert)语句的效率影响——(二叉树重整、维护索引)
存储引擎
MyISAM BTREE
InnoDB BTREE
MEMORY/HEAP HASH, BTREE
哪些列上适合添加索引

索引的使用

explain:

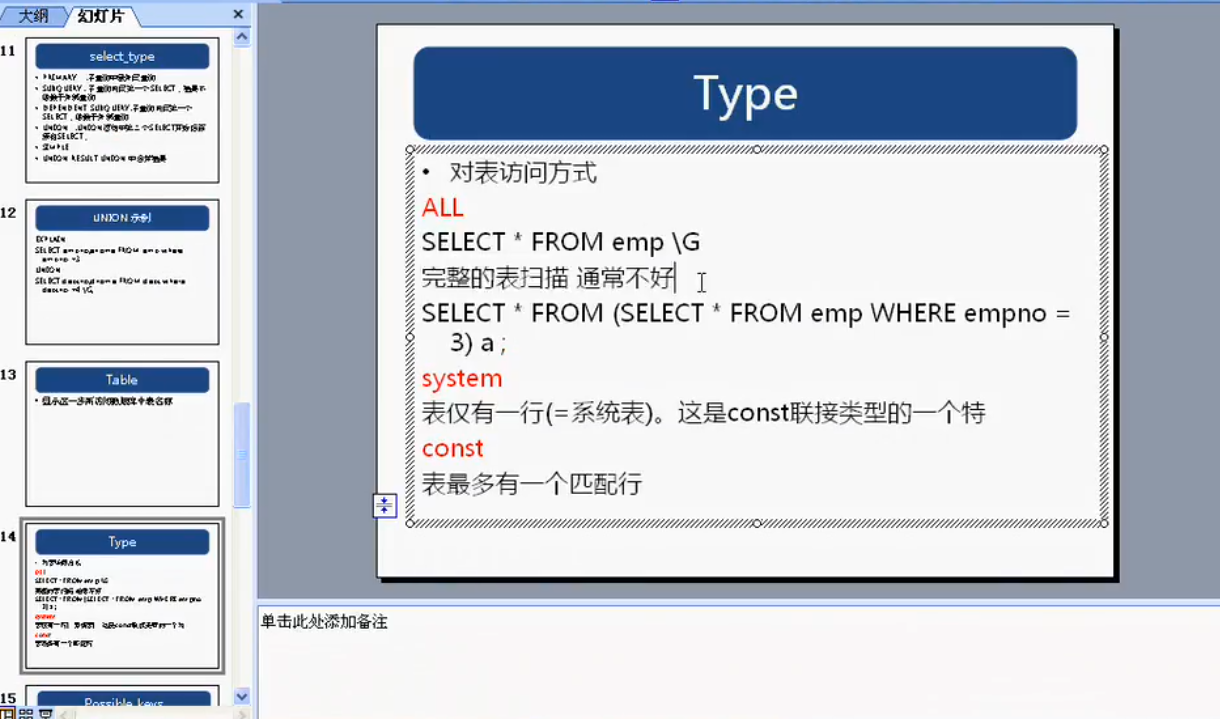
查看索引使用情况

四、优化诀窍
常用SQL优化


选择合适的存储引擎

Memory:比如数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory
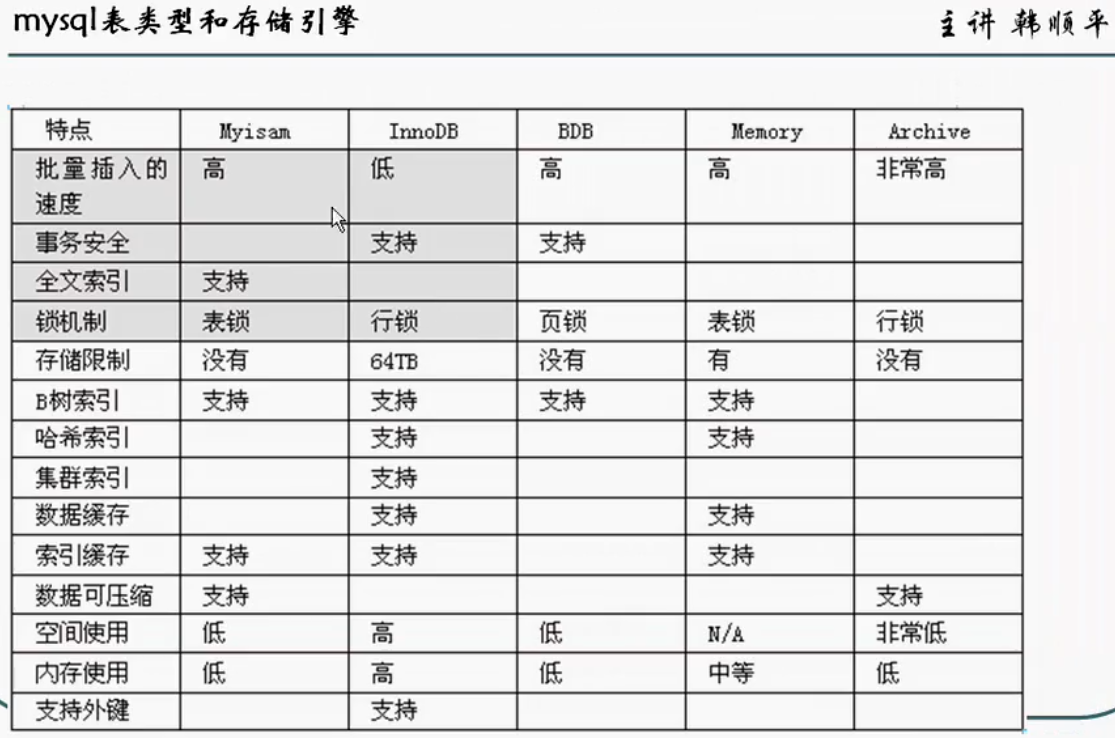
如果你的数据库的存储引擎是myisam,请一定记住要定时进行碎片整理。不然删除数据,删除不了。
optimize table test100;
选择合适的数据类型

五、定时维护

手动备份数据(库的)表方法
-- 备份数据库
-- cmd中执行
mysqldump -u root -proot ceshi > D:\output.sql
-- 备份表
-- cmd中执行
mysqldump -u root -proot ceshi student class > D:\output.sql
如何使用备份文件恢复我们的数据:
-- mysql控制台执行
source d:\output.sql
使用定时器来自动完成
把备份数据库的命令,写入到bat文件,然后使用任务管理器定时调用bat文件。( Linux中使用crontab )
mytask.bat
定时完成发送邮件功能

六、水平分割
表的分割技术
水平分割

垂直分割
对表进行垂直分割。
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。(JOIN)
七、读写分离
如果数据库压力过大,一台机器支撑不了,那么可以用mysql复制实现多台机器同步,将数据库的压力分散。
数据量很大:分表;并发量很大:读写分离。
master
slave
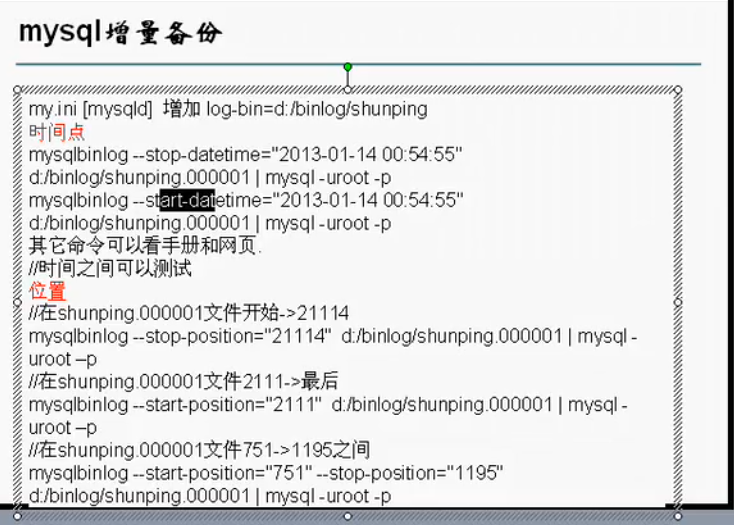
八、增量备份(binlog)
mysql会以二进制的形式,把用户对mysql的操作记录到日志文件中,
当用户希望恢复的时候,可以使用备份文件,进行恢复,
-
增量备份会记录,dml语句、创建表、创建库
-
记录操作语句本身、操作的时间、position
如何进行增量备份、恢复?
-
配置my.ini文件或者my.conf,启用二进制备份
[mysqld] # 指定备份文件放到哪里 log-bin=D:\binlog\mysql_binlog -
启动mysql
得到文件:mysql_binlog.index、mysql_binlog.000001