HashMap高并发下存在的问题
原文链接:https://blog.csdn.net/bjwfm2011/article/details/81076736
1、什么是HashMap?
HashMap底层原理
HashMap是存储键值对(key-value)的集合,每个键值对也叫做Entry,这些Entry分散存储在一个数组中,这个数组可以称为HashMap的主干。
2、HashMap在高并发下会产生的情况
在分析高并发情况之前,需要搞清楚ReHash这个概念。(ReHash是HashMap在扩容时候的一个步骤)
HashMap的容量是有限的,当经过多次元素插入,使得HashMap达到一定的饱和度时,key映射位置发生冲突的几率会逐渐提高,这时候HashMap需要扩展它的长度,就是进行Resize。
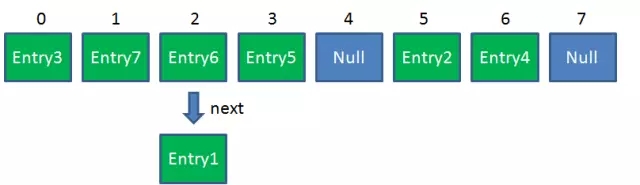
影响Resize的因素有两个
- Capacity HashMap的当前长度;
- LoadFactor HashMap的负载因子,默认值是0.75f;
衡量HashMap是否进行Resize的条件:
HashMap.Size >= Capacity * LoadFactor
3、HashMap的Resize具体做了哪些事情呢?HashMap不是简单的把长度扩大,而是经过了下面两个步骤:
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
Hash公式:index = HashCode(Key) & (Length - 1)
当原数组长度为8时,Hash运算是和111B做与运算;新数组长度为16,Hash运算是和1111B做与运算。Hash结果显然不同。
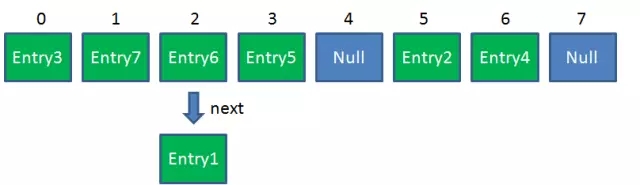
Resize前的HashMap:
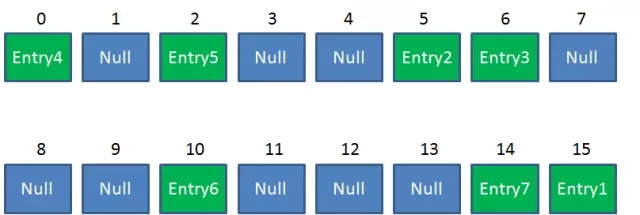
Resize后的HashMap:
ReHash的Java代码如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号