十、正则表达式和JSON
一、什么是正则表达式
正则表达式是一个特殊字符序列,一个字符串是否与我们所设定的这样的字符序列相匹配。
应用:快速检索文本、实现一些替换文本的操作
1、检查一串数字是否是电话号码
2、检查一个字符串是否符合email
3、把一个文本里指定的单词替换为另外一个单词
例:
a='C|C++|Java|C#|Python|Javascript'
判断a中是否包含Python
方法一:使用python内置方法
1) a.index('Python')>-1:
1 a='C|C++|Java|C#|Python|Javascript' 2 3 if a.index('Python')>-1: 4 print(True) 5 else: 6 print(False)
2)'Python' in a
1 a='C|C++|Java|C#|Python|Javascript' 2 if 'Python' in a: 3 print(True) 4 else: 5 print(False)
方法二:使用正则表达式
1 #coding=utf-8 2 import re 3 4 a='C|C++|Java|C#|Python|Javascript' 5 r=re.findall('Python',a) 6 print(r) 7 if len(r)>0: 8 print(u'字符串中包含Python') 9 else: 10 print(u'字符串中不包含Python')
以上例子中‘Python’是常量字符串,几乎无意义。正则表达是的意义或者灵活即:规则
二、元字符与普通字符
a='C0C++7Java8C#9Python6Javascript'
查找a中所有的数字
1 #coding=utf-8 2 import re 3 a='C0C++7Java8C#9Python6Javascript' 4 r=re.findall('\d',a) 5 print(r)
总结:以上两个例子中Python是普通字符,\d是元字符
正则表达式是由一系列的普通字符和元字符所组成的

正则表达式有很多,在实际工作中根据需要查找即可
三、字符集
字符集由[]括起来的一组字符组合,字符之间是或者的关系,^代表非,-代表范围
字符集两边常常由普通字符构成,如‘a[cf]c’,普通字符a、c用来定界
1 #coding=utf-8 2 import re 3 ''' 4 字符集的使用 5 ''' 6 s = 'abc,acc,adc,aec,afc,ahc' 7 #查找s中,中间一个字符是c或f的单词 8 r=re.findall('a[cf]c',s) 9 print(r) 10 11 #查找s中,中间一个字符不是c也不是f的单词 12 r1=re.findall('a[^cf]c',s) 13 print(r1) 14 15 #查找s中,中间一个字符是c\d\e\f的单词 16 r2=re.findall('a[c-f]c',s) 17 print(r2)
四、概括字符集

像\d、\D、\w这种具有高度概括的表达式,我们称为概括字符集
1 #coding=utf-8 2 import re 3 ''' 4 概括字符集 5 ''' 6 a='Python 1111Java678php' 7 # r=re.findall('[0-9]',a) 8 r=re.findall('\d',a) 9 print(r)
五、数量词
数量词{}表示个数
如{3}表示3位;{3,6}表示最小3位,最大6位
1 #coding=utf-8 2 import re 3 ''' 4 数量词{} 5 ''' 6 a='Python 1111\nJava678php' 7 #检索所有单词 8 # r=re.findall('[a-z]{3}',a) 9 #Python6位,Java4w位,php3位,所以取3到6位 10 r=re.findall('[a-zA-Z]{3,6}',a) 11 print(r)
六、贪婪与非贪婪
正则表达式默认是尽可能使用贪婪的匹配方式
非贪婪,后面加?
1 #coding=utf-8 2 import re 3 ''' 4 贪婪与非贪婪 5 ''' 6 a='Python 1111\nJava678php' 7 #贪婪方式匹配 8 r=re.findall('[a-zA-Z]{3,6}',a) 9 print(r) 10 #非贪婪方式匹配 11 r1=re.findall('[a-zA-Z]{3,6}?',a) 12 print(r1)

七、匹配0次1次无限次

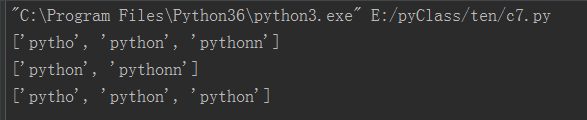
1 #coding=utf-8 2 import re 3 a='pytho0python1pythonn2' 4 r=re.findall('python*',a) 5 r1=re.findall('python+',a) 6 r2=re.findall('python?',a) 7 print(r) 8 print(r1) 9 print(r2)
关于?
1、作为非贪婪匹配方式?前面是范围
2、作为数量词?前面是普通字符
1 #coding=utf-8 2 import re 3 a='pytho0python1pythonn2' 4 5 r=re.findall('python{1,2}',a) 6 r1=re.findall('python{1,2}?',a) 7 r2=re.findall('python?',a) 8 print(r) 9 print(r1) 10 print(r2)

八、边界匹配符

例如:
1 #coding=utf-8 2 import re 3 4 # qq='100001' 5 # qq='101' 6 qq='100000001' 7 #检查qq号码是否符合4-8位数字 8 r=re.findall('\d{4,8}',qq) 9 print(r)
使用正则表达式'\d{4,8}'可以检测出4-8位,小于4位,但是大于8位时,无法检测,正确做法是使用首尾匹配
1 #coding=utf-8 2 import re 3 4 qq='100001' 5 # qq='101' 6 # qq='100000001' 7 #检查qq号码是否符合4-8位数字 8 r=re.findall('\d{4,8}$',qq) 9 print(r)
九、组
()小括号括起来的称为一组
1 #coding=utf-8 2 import re 3 a='PythonPythonPythonPythonPython*%%php' 4 #检测a中是否包含3个Python 5 r=re.findall('(Python){3}',a) 6 print(r)
十、匹配模式参数flag
findall(pattern, string, flags=0)方法中的第三个参数flags代表匹配模式
常用的匹配模式有

1 #coding=utf-8 2 import re 3 s = 'PythonC#\rJava\nPHP' 4 #使用re.I和re.S匹配模式,多个模式直接用|分隔 5 r=re.findall('c#',s,re.I|re.S) 6 print(r)
1 #coding=utf-8 2 import re 3 s = 'PythonC#\rJavaC#\nPHP' 4 #使用re.I和re.S匹配模式,多个模式直接用|分隔 5 r=re.findall('c#.{1}',s,re.I|re.S) 6 print(r)
十一、re.sub正则替换
1 #coding=utf-8 2 import re 3 4 s='PythonC#JavaC#phpC#' 5 r=re.sub('C#','GO',s,2) 6 r1=s.replace('C#','GO',1) 7 print(r) 8 print(r1)
其中‘GO’可以是函数
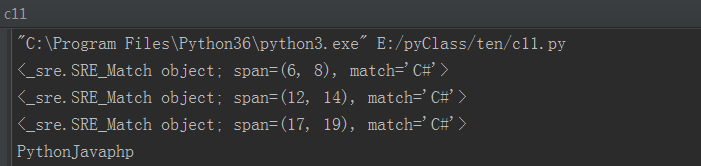
1 # coding=utf-8 2 import re 3 4 s = 'PythonC#JavaC#phpC#' 5 6 # r=re.sub('C#','GO',s,2) 7 def convert(value): 8 pass 9 r = re.sub('C#', convert, s) 10 print(r)
运行结果:

调用过程:
1)C#作为convert的参数
2)convert的返回作为re.sub()的参数,因无返回值所以替换后字符串中的C#消失了
打印value发现结果显示的是对象且被调用了三次(因为设置了参数3)
要获取值C#,需要用group()方法
1 # coding=utf-8 2 import re 3 4 s = 'PythonC#JavaC#phpC#' 5 6 def convert(value): 7 matched=value.group() 8 print(matched) 9 return '!!'+matched+'!!' 10 11 r = re.sub('C#', convert, s) 12 print(r)
12、把函数作为参数传递
上面convert是较为简单的函数,实际中常常使用更为复杂的函数,作为sub()参数
1 # coding=utf-8 2 import re 3 4 s = 'A8C3711D86' 5 6 7 # 找出s中所有数字,大于6的替换为9,小于6的替换为0 8 def convert(value): 9 matched = value.group() 10 res = None 11 if int(matched) >= 6:#注意matched是str格式,需要转成int格式 12 res = '9'#数字不能作为返回值,需要将int转成str 13 else: 14 res = '0' 15 return res 16 17 18 r = re.sub('\d', convert, s) 19 print(r)
convert:你给我个字符串,我还你个字符串。至于中间变量value如何处理,不关心
思考:s中大于50的替换为100,小于50的替换为0
1 # coding=utf-8 2 import re 3 4 s = 'A8C3711D86' 5 6 7 # 找出s中所有数字,大于6的替换为9,小于6的替换为0 8 def convert(value): 9 matched = value.group() 10 res = None 11 if int(matched) >= 50:#注意matched是str格式,需要转成int格式 12 res = '100'#数字不能作为返回值,需要将int转成str 13 else: 14 res = '0' 15 return res 16 17 18 r = re.sub('\d{2}', convert, s) 19 print(r)
13、search与match
实际没有findall好用
match:尝试从字符串首字母开始匹配,如果找不到返回None,找到第一个即返回。
search:尝试搜索整个字符串,找到第一个即返回
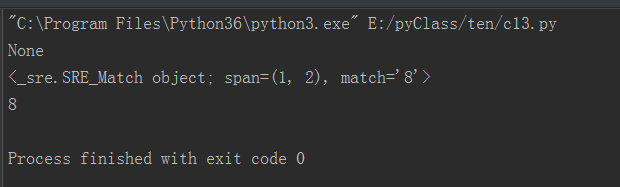
1 #coding=utf-8 2 import re 3 ''' 4 检索所有数字 5 ''' 6 s='A83C72D8E67' 7 8 r=re.match('\d',s) 9 #从首字母开始匹配数字 10 print(r) 11 r1=re.search('\d',s) 12 #返回对象,包含位置信息等 13 print(r1) 14 #获取查询结果,匹配一次即返回 15 print(r1.group())



 浙公网安备 33010602011771号
浙公网安备 33010602011771号