


An Image Worth 16x16 Words:Transformeers for Image Recognition At Scale | ViT 论文精读笔记
参考
https://www.bilibili.com/video/BV15P4y137jb/?spm_id_from=333.788&vd_source=920f8a63e92d345556c1e229d6ce363f 李沐组会的ViT精读
ViT借用NLP领域的Transformer,挑战了CNN在计算机视觉领域的绝对统治地位!!
ViT不仅仅在CV挖了一个大坑,给CV开启了一个新时代,他更是打破了CV和NLP的壁垒,在多模态领域也挖了一个大坑。
现在的NLP领域基本离不开Transformer,都是用大规模的数据去做预训练,再用小规模数据集去微调。
现在Transformer仿佛没有性能瓶颈,随着训练资源的增加,性能好像能一直提升一样,看不到瓶颈让其饱和。
ViT对标的工作:
想用Transformer处理图片,是这篇工作的motivation。其challenge主要是,transformer接收的是一个1d的序列,而且这个序列不能太大(比如原论文用的512长度,也曾扩展到1000这个数量级,但是不管多大,现在也基本都是Google这种大公司有钱人玩的。而传统的图片,即使是分类任务,对像素要求最低的一般也得是100的数量级,如果直接拉伸成1d,这个数量级就变成了万,几乎是不可训练的,更不用说更高级的语义分割等任务。因此,如何解决把2d图映射成1d向量这个问题,就是这篇文章的重点。)
1、Transformer出现后,引出了不少工作,其中就有在视觉领域用CNN结合Transformer的工作。不直接输入原图,而是输入CNN处理后的特征图,这时候特征图已经很小了,再用transformer去训练即可。
2、对图片的两个维度分别做transformer,但是这种速度非常慢,且效果不如目前最优秀的残差网络。
3、设置一个窗口,这个窗口大小可控,在当前窗口里进行transformer的attention。但是这种思路又回到了CNN的思想。
目前在图像领域,残差网络ResNet仍然是霸榜地位。
而ViT,思路非常简单,就是把图片打成patch,原文是将224x224的图按16x16打patch,打成了14x14个patch,这样将每一个patch当成元素,最终的输入就是14x14维度的向量,就很小了。这里的每一块patch,就相当于一个单词,一个图片就相当于一个句子,相对于NLP来说,模型对数据的感知也就是NLP任务中的所有句子的长度不一致了罢了。
这么简单的思路,当然有人做过,甚至说我听完transformer之后,就觉得可以这么做。但是,没办法,google有钱,别的机构都训练不动,所以paper只能google发。(钞能力)
现在没个几千万几个亿,你玩什么科研!!?(狗头保命)
如此处理,就可以直接将NLP的Transformer模型拿过来直接使用,而不需要对模型做什么基于CV的改动,只需要对图像做一些预处理(打成快),即可。这样,CV和NLP就大一统了。
MODEL
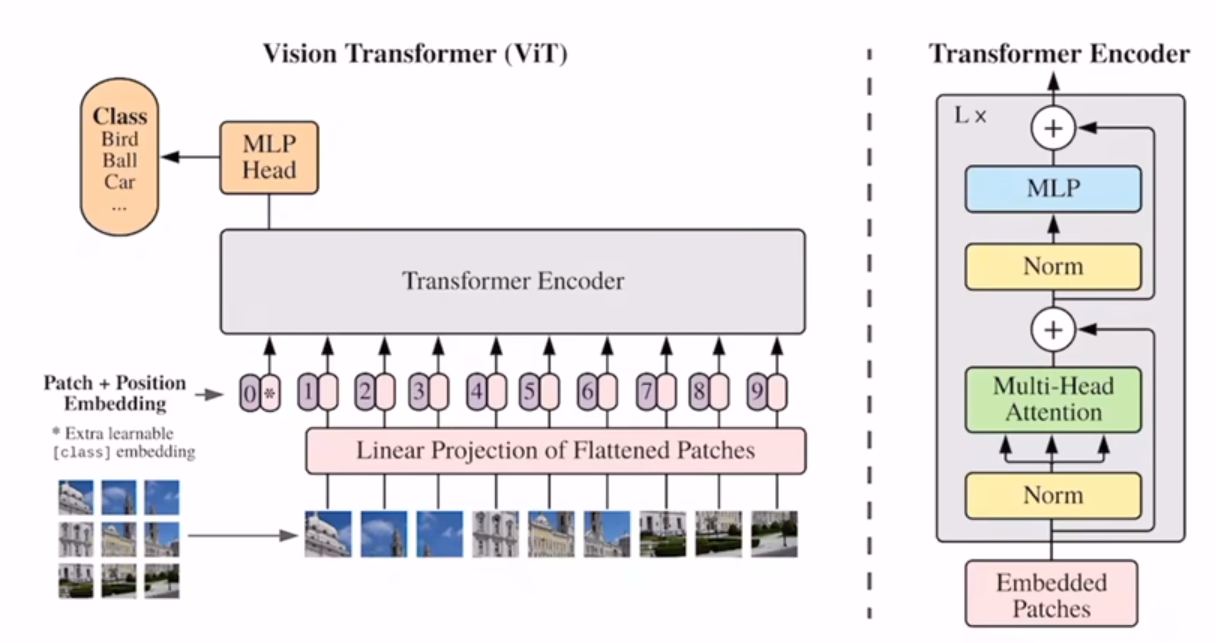
大概看一下ViT的结构,将图片打成patch,随后用同一个Linear将其展开。和Transformer一样,我们要给每一个展开后的向量加入一个位置信息。注意,这里有一个星号,是额外多加的一个向量,也就是最后送入Transformer的向量序列长度是patch_Num+1.这个型号的作用是分类,因为Transformer输出的仍然是一个向量序列,那既然我需要分类,我的依据是什么呢?就认为是这个*向量,因为送入Transformer之后,两两向量都能互相学到彼此的信息,那么就认为这个*向量学到了所有信息(这个向量借鉴于BERT的 class token )
这里用的位置编码,仍然是1D的编码,作者尝试了其他编码形式如2D编码,但是结果都差不多,所以为了和Transformer保持高度一致,仍然使用1d。
另外,这个class token也可以不使用,直接用线性层做全局平均池化,效果差不多,但是为了和Transformer保持高度一致,就这么做了。
总之,这篇paper的重点就是,要证明,NLP工作的很好的transformer的model,是可以直接拿到CV里用的。
实验
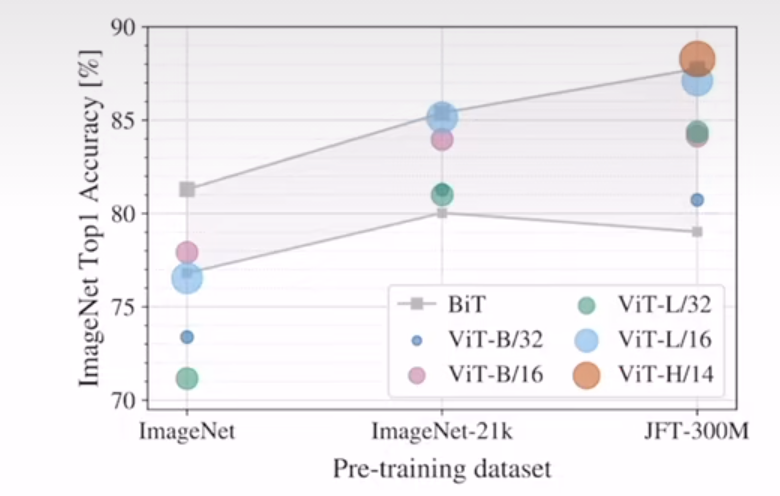
比较重要的就是这张图。从图中可以得到两个结论:
如果你用的数据集没有ImageNet-21k那么大,那么你是用ResNet或许是个更好的选择;如果你的数据集非常大,最起码超过了ImageNet-21k,那么大概率你选择ViT模型效果会更好。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通